| |

Activation Functions in Neural NetworksA paradigm for information processing that draws inspiration from the brain is called an artificial neural network (ANN). ANNs learn via imitation just like people do. Through a learning process, an ANN is tailored for a particular purpose, including such pattern classification or data classification. The synapses interconnections that exist between both the neurons change because of learning. What input layer to employ with in hidden layer and at the input level of the network is one of the decisions you get to make while creating a neural network. This article discusses a few of the alternatives. The nerve impulse in neurology serves as a model for activation functions within computer science. A chain reaction permits a neuron to "fire" and send a signal to nearby neurons if the induced voltage between its interior and exterior exceeds a threshold value known as the action potential. The next series of activations, known as a "spike train," enables motor neurons to transfer commands from of the brain to the limbs and sensory neurons too transmit sensation from the digits to the brain. Neural Network ComponentsLayers are the vertically stacked parts that make up a neural network. The image's dotted lines each signify a layer. A NN has three different types of layers. Input LayerThe input layer is first. The data will be accepted by this layer and forwarded to the remainder of the network. This layer allows feature input. It feeds the network with data from the outside world; no calculation is done here; instead, nodes simply transmit the information (features) to the hidden units. Hidden LayerSince they are a component of the abstraction that any neural network provides, the nodes in this layer are not visible to the outside world. Any features entered through to the input layer are processed by the hidden layer in any way, with the results being sent to the output layer. The concealed layer is the name given to the second kind of layer. For a neural network, either there are one or many hidden layers. The number inside the example above is 1. In reality, hidden layers are what give neural networks their exceptional performance and intricacy. They carry out several tasks concurrently, including data transformation and automatic feature generation. Output LayerThis layer raises the knowledge that the network has acquired to the outside world. The output layer is the final kind of layer The output layer contains the answer to the issue. We receive output from the output layer after passing raw photos to the input layer. Data science makes extensive use of the rectified unit (ReLU) functional or the category of sigmoid processes, which also includes the logistic regression model, logistic hyperbolic tangent, and arctangent function. Activation FunctionDefinitionIn artificial neural networks, an activation function is one that outputs a smaller value for tiny inputs and a higher value if its inputs are greater than a threshold. An activation function "fires" if the inputs are big enough; otherwise, nothing happens. An activation function, then, is a gate that verifies how an incoming value is higher than a threshold value. Because they introduce non-linearities in neural networks and enable the neural networks can learn powerful operations, activation functions are helpful. A feedforward neural network might be refactored into a straightforward linear function or matrix transformation on to its input if indeed the activation functions were taken out. By generating a weighted total and then including bias with it, the activation function determines whether a neuron should be turned on. The activation function seeks to boost a neuron's output's nonlinearity. Explanation: As we are aware, neurons in neural networks operate in accordance with weight, bias, and their corresponding activation functions. Based on the mistake, the values of the neurons inside a neural network would be modified. This process is known as back-propagation. Back-propagation is made possible by activation functions since they provide the gradients and error required to change the biases and weights. Need of Non-linear Activation FunctionsAn interconnected regression model without an activation function is all that a neural network is. Input is transformed nonlinearly by the activation function, allowing the system to learn and perform more challenging tasks. It is merely a thing procedure that is used to obtain a node's output. It also goes by the name Transfer Function. The mixture of two linear functions yields a linear function, so no matter how several hidden layers we add to a neural network, they all will behave in the same way. The neuron cannot learn if all it has is a linear model. It will be able to learn based on the difference with respect to error with a non-linear activation function. The mixture of two linear functions yields a linear function in itself, so no matter how several hidden layers we add to a neural network, they all will behave in the same way. The neuron cannot learn if all it has is a linear model. The two main categories of activation functions are:
Linear Activation FunctionAs can be observed, the functional is linear or linear. Therefore, no region will be employed to restrict the functions' output. 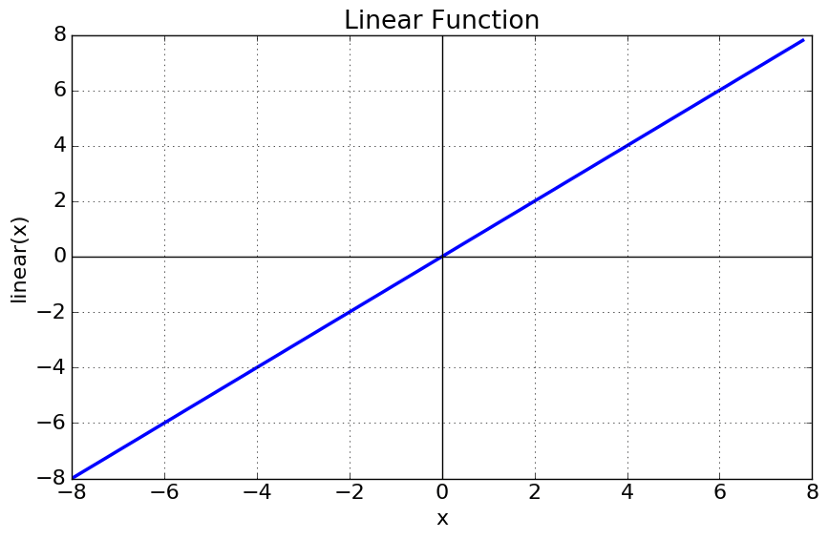
The normal data input to neural networks is unaffected by the complexity or other factors. Non-linear Activation FunctionThe normal data input to neural networks is unaffected by the complexity or other factors. Activation Function
Equation: A linear function's equation, which is y = x, is similar to the eqn of a single direction. The ultimate activation function of the last layer is nothing more than a linear function of input from the first layer, regardless of how many levels we have if they are all linear in nature. -inf to +inf is the range. Uses: The output layer is the only location where the activation function's function is applied. If we separate a linear function to add non-linearity, the outcome will no longer depend on the input "x," the function will become fixed, and our algorithm won't exhibit any novel behaviour. A good example of a regression problem is determining the cost of a house. We can use linear activation at the output layer since the price of a house may have any huge or little value. The neural network's hidden layers must perform some sort of non-linear function even in this circumstance.
It is a functional that is graphed in a "S" shape. A is equal to 1/(1 + e-x). Non-linear in nature. Observe that while Y values are fairly steep, X values range from -2 to 2. To put it another way, small changes in x also would cause significant shifts in the value of Y. spans from 0 to 1. Uses: Sigmoid function is typically employed in the output nodes of a classi?cation, where the result may only be either 0 or 1. Since the value for the sigmoid function only ranges from 0 to 1, the result can be easily anticipated to be 1 if the value is more than 0.5 and 0 if it is not.
The activation that consistently outperforms sigmoid function is known as tangent hyperbolic function. It's actually a sigmoid function that has been mathematically adjusted. Both are comparable to and derivable from one another. 
Range of values: -1 to +1. non-linear nature Uses: - Since its values typically range from -1 to 1, the mean again for hidden layer of a neural network will be 0 or very near to it. This helps to centre the data by getting the mean close to 0. This greatly facilitates learning for the following layer. Equation: max A(x) (0, x). If x is positive, it outputs x; if not, it outputs 0. Value Interval: [0, inf] Nature: non-linear, which allows us to simply backpropagate the mistakes and have the ReLU function activate many layers of neurons. Uses: Because ReLu includes simpler mathematical processes than tanh and sigmoid, it requires less computer time to run. The system is sparse and efficient for computation since only a limited number of neurons are activated at any given time. Simply said, RELU picks up information considerably more quickly than sigmoid and Tanh functions.
Currently, the ReLU is the activation function that is employed the most globally. Since practically all convolutional neural networks and deep learning systems employ it. The derivative and the function are both monotonic. However, the problem is that all negative values instantly become zero, which reduces the model's capacity to effectively fit or learn from the data. This means that any negative input to a ReLU activation function immediately becomes zero in the graph, which has an impact on the final graph by improperly mapping the negative values.
Although it is a subclass of the sigmoid function, the softmax function comes in handy when dealing with multiclass classification issues. Used frequently when managing several classes. In the output nodes of image classification issues, the softmax was typically present. The softmax function would split by the sum of the outputs and squeeze all outputs for each category between 0 and 1. The output unit of the classifier, where we are actually attempting to obtain the probabilities to determine the class of each input, is where the softmax function is best applied. The usual rule of thumb is to utilise RELU, which is a usual perceptron in hidden layers and is employed in the majority of cases these days, if we really are unsure of what encoder to apply. A very logical choice for the output layer is the sigmoid function if your input is for binary classification. If our output involves multiple classes, Softmax can be quite helpful in predicting the odds for each class. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








