| |

Kafka: Multiple ClustersWe have studied that there can be multiple partitions, topics as well as brokers in a single Kafka Cluster. Thus, with growing Apache Kafka deployments, it is beneficial to have multiple clusters. In this section, we will discuss about multiple clusters, its advantages, and many more. A Kafka cluster is a cluster which is composed of multiple brokers with their respective partitions. A multiple Kafka cluster means connecting two or more clusters to ease the work of producers and consumers. Advantages of Multiple ClustersA single Kafka cluster is enough for local developments. But, it is beneficial to have multiple clusters. There are several reasons which best describes the advantages of multiple clusters:
Isolation of types of data Using multiple clusters allows the user to segregate different types of data under different brokers. This makes it easy to fetch the data. Also, the user does not need to filter data in a single cluster. Multiple Datacenters The purpose of building multiple datacenters is to save our data or messages from disasters. Therefore, these datacenters need to copy data between them. If any disaster happens, like a system crash or server crash, the data can still be able to recover. Also, it becomes easy for online applications to access the user's activity at both sites. Isolation for security requirements Security is the main concern for any data or message. Apache Kafka offers various security measures for the stored data. As multiple datacenters stores a vast amount of data separately, security requirements are also isolated in different datacenters. MirrorMakerIn Apache Kafka, the replication process works only within the cluster, not between multiple clusters. Consequently, the Kafka project introduces a tool known as MirrorMaker. A MirrorMaker is a combination of a consumer and a producer. Both of them are linked together with a queue. A producer from one Kafka cluster produces a message, and a consumer from another cluster reads that message. 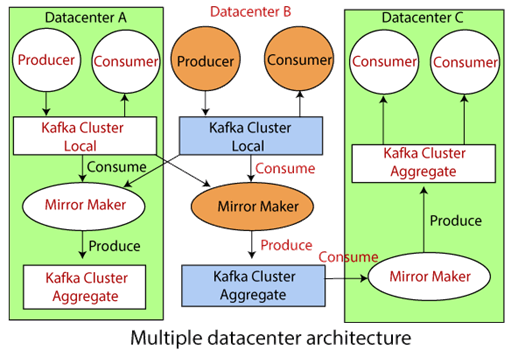
In the above figure, messages from two local datacenters are aggregated into one single cluster through MirrorMaker. Then the respective cluster is copied to other datacenters. Therefore, to manage a vast amount of data and messages, MirrorMaker is used for replicating data between various Kafka clusters.
Next TopicKafka Architecture
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








