| |

Apache Solr Text AnalysisApache Solr text analysis can be used for removing superficial differences between terms to address more complex issues to provide a good user experience like language-specific parsing, lemmatization, and part-of-speech tagging. We will discuss all these terms in more detail ahead. Apache Solr has an extensive framework for performing fundamental text analysis, such as- removing common words known as stop words and performing additional complex analysis. To put-up, such power and flexibility, Solr's text analysis framework can seem excessively complicated and intimidating for the new users. As we can say, Solr makes complicated text analysis so easy, but in doing so, it makes simple tasks a little too unmanageable. That is the reason why Solr inbuilt with so many preconfigured field types in its example "schema.xml" to ensure new users have an excellent place to start with text analysis when using Solr out of the box. After learning through this tutorial, you'll be able to tackle this robust structure to analyze most of the content we'll face. We demonstrate the approaches of text analysis and construct analysis solutions for our files. To this end, we'll tackle a complex text analysis problem to get the strategies and mechanics we need to be successful. Specifically, we'll understand the given fundamental elements of text analysis with Solr:
Specifically, we'll see how to analyze microblog content from sites like Twitter. Tweets present unique challenges that need us to think hard about how many users will use our search results. Specifically, we will see how to:
Analyzing microblog textLet's continue with the example microblog search application we introduced on this page. Here, we're going to design and implement solutions to search microblogs from different social media sites such as Twitter, Facebook, etc. Because this tutorial's fundamental focus is on text analysis, let's look closer at the text field in our example microblog document. 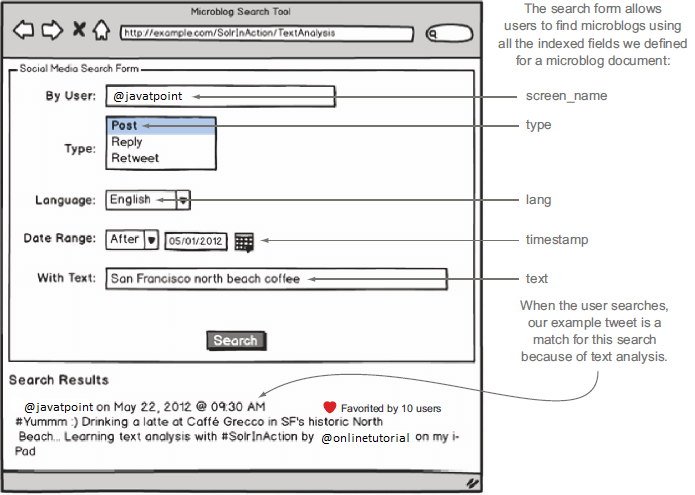
Here is the text we want to analyze: As we discussed in the introduction, a primary goal of text analysis is to allow your users to search using natural language without worrying about all possible forms of their search terms. In the figure above, the user searched via the text field for San Francisco north beach coffee, which is a natural query to expect given all the great coffeehouses in North Beach; maybe our user is trying to find a great place to drink coffee in North Beach by searching social media content. We declare that our example tweet should be a strong match for this query even if exact text matches for north beach, San Francisco, and coffee do not occur in our example tweet. Yes, North Beach is in our file, but case matters in the search unless you take specific action to make your search index case-insensitive. We assert that our example document should be a strong match for this query because of the relationships between terms used in the user's search query and terms in the document shown in the table.
Basic text analysisAs we learned earlier, the <types> section in schema.xml defines <fieldType> elements for all possible fields in your documents, in which each <fieldType> defines the format and working of the field that is analyzed for queries and indexing. The sample schema provided an extensive list of field types applicable to Solr's vast search applications. If any of the predefined Solr field types doesn't meet our needs, we can build our own field type with Solr Plug-In frameworks' help. Suppose all the fields contained organizes data like timestamps and language codes. In that case, we may not need to use Solr because a relational database is systematic at searching and indexing of structured data. Operating with unstructured text is where Solr truly shows its capabilities. Therefore, the example Solr schema predefines some powerful field types for analyzing text. It provides the XML definition for text_general, one of the simpler field types, as a starting point for analyzing our tweet text. The examples in this tutorial depend on a few minor customizations to the schema.xml that ships with the Solr example. We recommend replacing the schema.xml file that ships with the Solr example with the customized version in $SOLR_IN_ACTION/example-docs/ch6/schema.xml. Specifically, you need to overwrite $SOLR_INSTALL/example/solr/collection1/conf/schema.xml by doing: Besides, you need to copy the wdfftypes.txt file to the conf directory: Finally, to start with a clean slate (since we already indexed some test documents in an earlier chapter), you should delete everything in your data directory to start with an empty search index: After copying the custom schema.xml and wdfftypes.txt, you'll need to reload the collection1 core from the Core administration page in the Solr administration console or restart Solr. AnalyzerInside the <fieldType> element, you should define at least one <analyzer>, which will determine how the text will be analyzed. It is common to define two separate <analyzer> elements in practice: one for analyzing the text and another for the indexing will be entered by the users when performing search operation. The "text_general" field uses this approach for this operation. Think, for a moment, about why we might use different analyzers for indexing and querying. It would help if you often had additional analysis for processing queries beyond what's necessary for document indexing. For example: if synonyms are typically added during query text analysis to avoid only inflating the size of our index and making it easier to control synonyms. However, we can define two different analyzers. The analysis applied to query terms must be compatible with how the text was analyzed during indexing. Considering the case in which an analyzer is configured too small terms while indexing, it does not lower the query terms. Users of Solr searching for North Beach would not find our example tweet because the index contains the small alphabetic forms of "north" and "beach." TokenizerIn Solr, each <analyzer> breaks the text analysis process into two phases:
There is also a third phase that allows pre-processing while tokenization, in which you can apply character filters. In the tokenization phase, the text will be split into a stream of tokens with parsing. The most basic tokenizer is a WhitespaceTokenizer that can be used to split text on whitespace only. Another one is StandardTokenizer, which performs intelligent parsing to splitting terms on whitespace, punctuation and correctly handles URLs, acronyms, and email addresses. We need to specify the Java implementation class of the factory for our tokenizer to define the tokenizer. To use the common Standard- Tokenizer, you specify solr.StandardTokenizerFactory. <tokenizer class="solr.StandardTokenizerFactory"/> In Solr, we can specify the factory class instead of the underlying Tokenizer class (implementation) because many of the tokenizers doesn't provide a default no-argument constructor. If we use the factory approach, Solr provides us a standard way to define any tokenizer in XML. All the factory class knows the way to translate the XML configuration properties to make an instance of the specific Tokenizer implementation class. All of them produce a stream of tokens, which can be processed by zero or more filters to transform the token.
Next TopicAdding Document
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








