| |

RDD Shared VariablesIn Spark, when any function passed to a transformation operation, then it is executed on a remote cluster node. It works on different copies of all the variables used in the function. These variables are copied to each machine, and no updates to the variables on the remote machine are revert to the driver program. Broadcast variableThe broadcast variables support a read-only variable cached on each machine rather than providing a copy of it with tasks. Spark uses broadcast algorithms to distribute broadcast variables for reducing communication cost. The execution of spark actions passes through several stages, separated by distributed "shuffle" operations. Spark automatically broadcasts the common data required by tasks within each stage. The data broadcasted this way is cached in serialized form and deserialized before running each task. To create a broadcast variable (let say, v), call SparkContext.broadcast(v). Let's understand with an example. 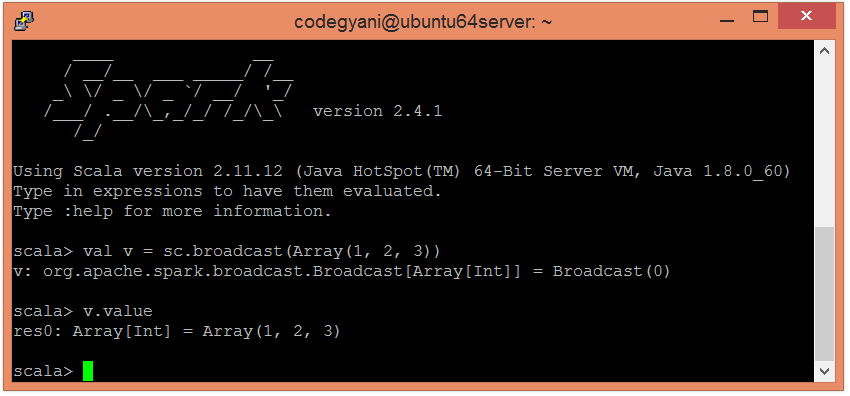
AccumulatorThe Accumulator are variables that are used to perform associative and commutative operations such as counters or sums. The Spark provides support for accumulators of numeric types. However, we can add support for new types. To create a numeric accumulator, call SparkContext.longAccumulator() or SparkContext.doubleAccumulator() to accumulate the values of Long or Double type. 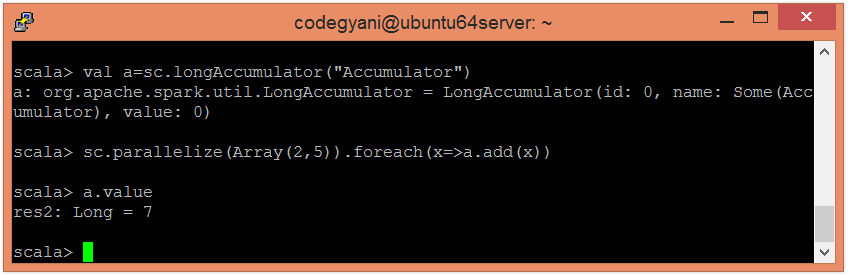
Next TopicSpark Map Function
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








