| |

Computer Vision TechniquesAs human beings, we can see, process, understand, and act on anything that we can see or any visual input; in other words, we have the ability to see and understand any visual data. But how we can implement the same thing in machines? So, here Computer Vision comes into the picture. Although there are still various limitations in machines to visualise similar to humans, they are very close to analysing, understanding, and extracting meaningful information from any visual input. Nowadays, Computer vision is one of the trending research areas with deep learning. In this topic, we will have a deep understanding of different computer vision techniques that are currently being used in several applications. However, before starting, let's first understand the basic introduction of computer vision. What is Computer Vision?Computer vision is a sub-field of AI and machine learning that enables the machine to see, understand, and interpret the visuals such as images, video, etc., and extract useful information from them that can be helpful in the decision-making of AI applications. It can be considered as an eye for an AI application. With the help of computer vision technology, such tasks can be done that would be impossible without this technology, such as Self Driving Cars. Computer Vision Process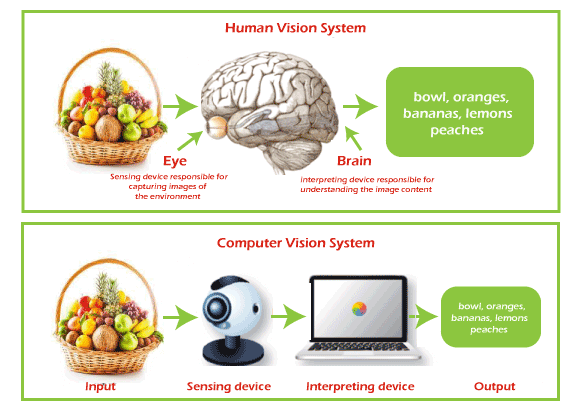
A typic process of Computer vision is illustrated in the above image. It mainly performs three steps, which are: 1. Capturing an Image A computer vision software or application always includes a digital camera or CCTV to capture the image. So, firstly it captures the image and puts it as a digital file that consists of Zero and one's. 2. Processing the image In the next step, different CV algorithms are used to process the digital data stored in a file. These algorithms determine the basic geometric elements and generate the image using the stored digital data. 3. Analyzing and taking required action Finally, the CV analyses the data, and according to this analysis, the system takes the required action for which it is designed. Top Computer Vision Techniques1. Image Classification Image classification is the simplest technique of Computer Vision. The main aim of image classification is to classify the image into one or more different categories. Image classifier basically takes an image as input and tells about different objects present in that image, such as a person, dog, tree, etc. However, it would not give you other more information about the image data, such as how many persons are there, tree colour, item positions, etc., and for this, we need to go for any other CV technique. Image classification is basically of two types, Binary classification and multi-class classification. As the name suggests, binary image classification looks for a single class in the given image and provides results based on if the image has that object or not. For example, we can achieve superhuman performance in detecting skin cancer in humans by training an AI system on both images that have skin cancer and images that do not have skin cancer. 2. Object Detection Object detection is another popular technique of computer vision that can be performed after Image classification or which uses image classification to detect the objects in visual data. It is basically used to recognize the objects within the boundary boxes and find the class of the objects in the image. Object detection makes use of deep learning and machine learning technology to generate useful results. As human beings, whenever we see a visual or look at an image or video, we can immediately recognize and even locate the objects within a moment. So, the aim of object detection is to replicate the same human intelligence into machines to identify and locate the objects. Object detection has several applications, including object tracking, retrieval, video surveillance, image captioning, etc. A variety of techniques can be used to perform object detection, which includes R-CNN, YOLO v2, etc. 3. Semantic Segmentation Semantic Segmentation is not only about detecting the classes in an image as image classification. Instead, it classifies each pixel of an image to specify what objects it has. It tries to determine the role of each pixel in the image. It basically classifies pixelS in a particular category without differentiating the object instances. Or we can say it classifies similar objects as a single class from the pixel levels. For example, if an image contains two dogs, then semantic segmentation will put both the dogs under the same label. It tries to understand the role of each pixel in an image. 4. Instance Segmentation Instance segmentation can classify the objects in an image at pixel level as similar to semantic segmentation but with a more advanced level. It means Instance Segmentation can classify similar types of objects into different categories. For example, if visual consists of various cars, then with semantic segmentation, we can tell that there are multiple cars, but with instance segmentation, we can label them according to their colour, shape, etc. Instance segmentation is a typical computer vision task compared to other techniques as it needs to analyse the difference within visual data with different overlapping objects and different backgrounds. In Instance segmentation, CNN or Convolutional Neural Networks can be effectively used, where they can locate the objects at pixels level instead of just bounding the boxes. A well-known example of CNN and instance segmentation is Facebook AI. This application can detect or differentiate two colours of the same object, and the architecture of CNN used in this is known as Mask R-CNN or Mask Region-Based Convolutional Neural Network. Using the below image, we can analyse the difference between semantic segmentation and instance segmentation, where semantic segmentation classified all the persons as singly entities, whereas instance segmentation classified all the persons as different by considering colours also. 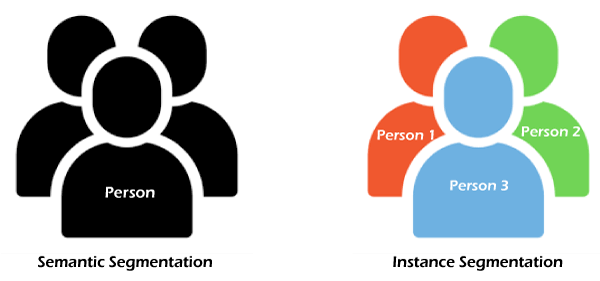
5. Panoptic Segmentation Panoptic Segmentation is one of the most powerful computer vision techniques as it combines the Instance and Semantic Segmentation techniques. It means with Panoptic Segmentation, you can classify image objects at pixel levels and can also identify separate instances of that class. 6. Keypoint Detection Keypoint detection tries to detect some key points in an image to give more details about a class of objects. It basically detects people and localizes their key points. There are mainly two keypoint detection areas, which are Body Keypoint Detection and Facial Keypoint Detection. For example, Facial keypoint detection includes detecting key parts of the human face such as the nose, eyes, corners, eyebrows, etc. Keypoint detection mainly has applications, including face detection, pose detection, etc. With Pose estimation, we can detect what pose people have in a given image, which usually includes where the head, eyes, nose, arms, shoulders, hands, and legs are in an image. This can be done for a single person or multiple people as per the need. 7. Person Segmentation Person segmentation is a type of image segmentation technique which is used to separate the person from the background within an image. It can be used after the pose estimation, as with this, we can closely identify the exact location of the person in the image as well as the pose of that person. 8. Depth Perception Depth perception is a computer vision technique that provides the visual ability to machines to estimate the 3D depth/distance of an object from the source. Depth Perception has wide applications, including the Reconstruction of objects in Augmented Reality, Robotics, self-driving cars, etc. LiDAR(Lights Detection and Ranging) is one of the popular techniques that is used for in-depth perception. With the help of laser beams, it measures the relative distance of an object by illuminating it with laser light and then measuring the reflections using sensors. 9. Image Captioning Image captioning, as the name suggests, is about giving a suitable caption to the image that can describe the image. It makes use of neural networks, where when we input an image, then it generates a caption for that image that can easily describe the image. It is not only the task of Computer vision but also an NLP task. 10. 3D Object Reconstruction As the name suggests, 3D object reconstruction is a technique that can extract 3D objects from a 2D image. Currently, it is a much-developing field of computer vision, and it can be done in different ways for different objects. On this technique, one of the most successful papers is PiFuHD, which tells about 3D human digitization.
Next Topic#
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








