Data Science Definition
What is Data?
Generally, we can say Data is a collection of facts and figures. It is a set of characters used to collect, store or transmit information for a specific purpose. Data can be in any form, i.e., text, image, audio, etc. Data comes from the Latin word 'Datum,' which means 'something given'. Data can be structured as well as unstructured. Processed data is termed Information.
In computer or programming language, Data is the collection of binary digits 0's and 1's. This type of data can be directly read and processed by the computer. There are various types of data.
Types of Data
- Qualitative Data: Such kind of data deals with data characteristics that cannot be measured but observed. It has two types- Nominal Data and Ordinal Data.
- Nominal Data: This kind of data has no specific order or ranking-for example, the gender of a person.
- Ordinal Data: This kind of data follows a specific order or ranking-for example, a grading system.
- Quantitative Data: Such kind of data deals with numbers or figures that can be measured. It has two types- Discrete Data and Continuous Data.
- Discrete Data: This kind of data can hold afinite number of values-for example, the number of students in a class.
- Continuous Data: This kind of data can holdinfinite possible values-for example, a person's weight.
Big Data: A collection of extensive and complicated data sets for which it becomes difficult to process using manual or traditional database handling tools. The size of Big Data is enormous (in terabytes or petabytes) and grows exponentially with time.
What is Data Science?
Before the Internet era began, handling data was easier as there was no concept of Big Data. It was at the beginning of the 1990s when people started using Internet widely, and later, with the arrival of Facebook and YouTube in the early 2000s, almost everybody started using the Internet. There began the generation of a huge amount of data. With the generation of such large amounts of data, its storage and process became difficult, and thus the concept of Big Data came into the picture.
Data Science is the study of handling and extracting meaningful insights from large data sets using modern tools and algorithms. The meaningful insights drawn from the data help us in decision-making.
Data Science has been widely used in businesses for better decision-making to make more and more profits.
Data Science can also be defined as collecting, storing, and analyzing data sets to build models that help in better decision-making.
How Data Science Works?
- Raw data is collected from various sources and combined at a single space.
- Collected data is cleaned from various types of errors and outliners are removed.
- Various statistical methods, Machine Learning Algorithms, Data Science tools, etc. are applied to the data sets.
- Valuable insights are drawn from the analysis of data sets.
- Finally, the representation of insights is given to the customer or clients.
What are the Prerequisites for Data Science?
- Statistics: Statistics play an important role in Data Science. Basic knowledge of statistical terms such as mean, median, mode, standard deviation, variance, etc., helps in a better understanding of data science models.
- Probability: Basic knowledge of probability to calculate the certainty of possible outcomes helps in better analysis in Data Science.
- Machine Learning: Knowledge of Machine Learning Algorithms helps draw better decision-making models. Machine Learning is an essential aspect of Data Science.
- Programming: Knowledge of any programming language helps build better Data Science projects. The most commonly used programming languages are Python, and R. Python is the most popular because it supports various libraries such as NumPy, Pandas, Matplotlib, etc., which helps in better analysis of data.
- Modeling: Mathematical models help in quick calculations and predictions based on the data you have. Modeling involves the identification of the algorithm you have to use to solve a given problem.
- Databases: Knowledge of managing, handling, and processing data from databases is essential to Data Science-for example, SQL.
Thus, we can conclude that Data Science is the combination of Statistics, Machine Learning, Probability, modeling, databases and domain knowledge.
Importance of Data Science
Data Science helps in extracting meaningful insights. These insights are used in various sectors, such as e-commerce, medicine, social media, entertainment, human resources, etc., to make better-decision making models, which will increase the profit of the respective sectors.
Data Science is used in almost every industry today that can predict the behavior of customers for better profits and identification of new trends.
Benefits of Data Science
- Improves business predictions
- Interpretation of complex data
- Better decision making
- Product innovation
- Improves data security
- Development of user-centric products
Data Science Lifecycle
There are five stages in a Data Science Lifecycle:
- Data Acquisition: There are many sources of data these days. Collecting or acquiring data in various forms from these sources and storing them is known as Data Acquisition. Data can be collected through multiple means, such as surveys, social media, statistical methods, transactional data, etc.
- Data Pre-processing: The data acquired is in its raw state and various forms, scattered over different servers. Thus, it is necessary to pre-process the data to convert it into a single format and store it together in a single place. This single space where all the data is stored is also known as Data Warehouse. This step is known as Data-Pre-processing.
- Machine-Learning Algorithms: Machine-Learning Algorithms are applied to the pre-processed data based on the problem statement to get meaningful insights from the pre-processed data. Some most common Machine Learning Algorithms include Linear Regression, Logistic Regression, K-nearest neighbors algorithm, Support vector machine, etc.
- Pattern Evaluation: The result obtained by applying Machine Learning Algorithms may not necessarily be correct. Thus, it is verified whether the outcome received solves the problem statement. This step is called Pattern Evaluation.
- Representation: The result obtained is then visualized using simple and easy-to-understand charts and represented to our customers or clients to give them an idea of the solution you have modeled using Data Science techniques.
Applications of Data Science:
- Search Engines:Various search engines like Google, Yahoo, etc. uses Data Science techniques and algorithms to provide millions of result to your search in just a few seconds. Without Data Science, it was just impossible for search engines to work so quickly and efficiently.
- Social Media and Entertainment: You must have witnessed streaming service apps such as Netflix recommending shows and movies based on your previous searches and what you have watched. These recommendations are given to you using Data Science Algorithms. It helps in a better streaming experience for the users.
- E-commerce websites: All E-commerce websites use Data Science Algorithms to provide customized suggestions and product recommendations based on your past purchases, likes, and search history. Recommendation systems provide a better experience to users as it helps them select the best item to purchase and increase the chances of profits for the company.
- Image Recognition: You must have witnessed that while posting a picture on Facebook, it shows you recommendations to tag people. This automatic tag suggestion feature uses a face recognition algorithm to detect and suggest people be tagged. Google also uses an image recognition algorithm to provide search results based on images uploaded.
- Speech Recognition: Google Voice, Alexa, Siri, etc., uses a speech recognition algorithm to provide results by converting your speech into text.
- Health Care: Health Care sectors use Data Science Algorithms to predict and analyze the health and fitness of a patient. Mass outbreaks of diseases can be predicted by analyzing the data and using algorithms. The use of medical imaging (X-Rays, CT-Scans, MRI, etc.) for detecting internal problems includes the use of Data Science Algorithms.
- Virtual Assistance: You must have witnessed many websites and apps provide virtual assistance or chatbots to clear your doubts or queries. Food delivery apps like Swiggy and Zomato offer virtual assistance to answer your order-related questions. These chatbots work on Machine Learning Algorithms such as Natural Language Processing (NLP) and generation to provide adequate customer support to the users.
- Gaming: Modern games are designed using Machine Learning Algorithms to provide a better experience to the users. It stores users' information and history to analyze and provide the best match for the users.
- Sports: Machine Learning Algorithms are used to predict the winning teams of sports like basketball, cricket, football, etc. Data Science Algorithms help predict and track athletes' health through wearable devices that follow the features such as heartbeat, blood pressure, oxygen level, etc., of a person.
Brief Introduction to Machine Learning
Machine Learning is an essential tool of Data Science as it helps make better decision-making models for Data Science projects. Almost every Data Science project is based on Machine Learning Algorithms. Some most common algorithms of Machine Learning are Linear Regression, Logistic Regression, K nearest neighbor Algorithm, etc. So, what is Machine Learning?
Machine Learning is the branch of AI (Artificial Intelligence) that allows devices or computers to learn from their past data without the use of any explicit programming. Machine Learning Algorithms help computers learn from their past experience. The goal is to make computers think and work like humans, or we can say exhibit intelligent behavior like humans.
In Machine Learning, first, we train our model with the help of a data set (the more extensive the data set, the better the model will be trained). Then our model learns to train itself and finds patterns and predictions to find as accurate a solution as possible. The programmer can change parameters to meet the precise result.
Now, the model is tested by giving the evaluation data set to it. If the result is accurate, then the ML model developed is valid. If the result is incorrect, the programmer can change the parameters to test and push the model toward accurate results.
Machine Learning models can be descriptive, predictive, prescriptive, or diagnostic in nature.
Types of Machine Learning
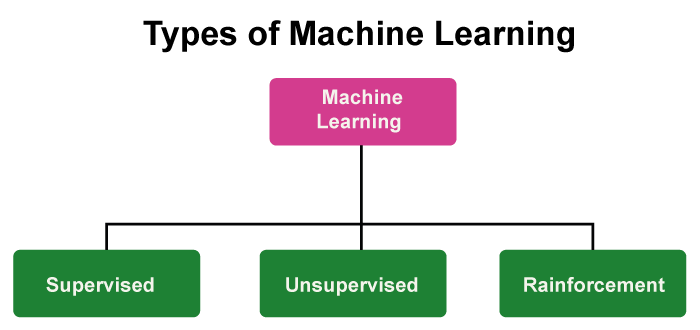
Supervised Learning: This type of Machine Learning requires a labeled set of data to learn and is thus called Supervised Learning. A labeled set of data has both the input as well as output parameters. Some examples of Supervised Learning are Linear Regression, Logistic Regression, etc.
Unsupervised Learning: This type of Machine Learning does not require a labeled data set. They predict and analyze using unlabeled sets of data. This algorithm is not supervised hence called Unsupervised Learning. Some examples of Unsupervised Learning are Clustering, Association, etc.
Reinforcement Learning: This type of Machine Learning uses a trial and error method to learn from the experiences. It does not need labeled data sets to work upon. This type of algorithm learns from its previous mistakes. The goal is to maximize the total output.
Types of Data Science Jobs
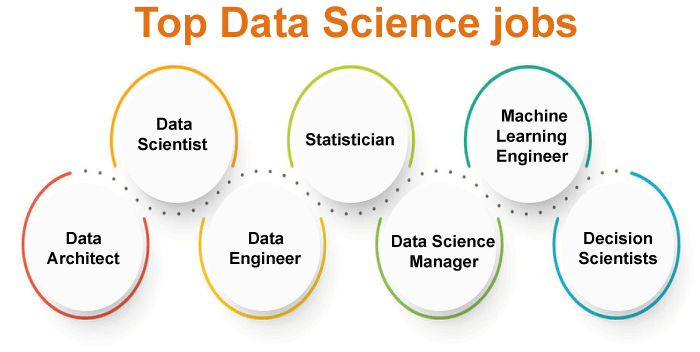
- Data Scientist: Data Scientists have to deal with collecting, cleaning, analyzing data, building insights from it, and finally, data visualization and presentations. Their job also includes researching and developing new models and algorithms.
- Data Architect: Data Architects' main job is to make new databases and maintain their management and privacy policies.
- Data Engineer: Data Engineers' main job is to design, implement and maintain data pipelines. Optimizing data pipelines and maintaining their efficiency is also part of their job. They ensure that proper data is available for data analysts or data scientists.
- Machine Learning Engineer: Machine Learning Engineer develops new Machine Learning Systems. Machine Learning Engineers should have strong statistics as well as programming skills to analyze and test new models.
- Decision Scientist: Decision Scientists' main job is to make better decision-making models. They analyze statistical data to drive decision-making models.
- Statistician: Statisticians' main job is to apply statistical models to real-time problems.
- Data Science Manager: Data Science Managers' main job is to manage and implement Big Data Solutions for their respective company.
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








