| |

Elasticsearch Aggregation APIsElasticsearch provides aggregation API, which is used for the aggregation of data. Aggregation framework provides aggregated data based on the search query. In simple words, aggregation framework collects all the data that is selected by the search query and provides to the user. It contains several building blocks that help to build a complex summary of data. Aggregations generate the analytic information available in Elasticsearch. Below are some important points of aggregation need to be noted:
Look at the figure below, how aggregation look like: 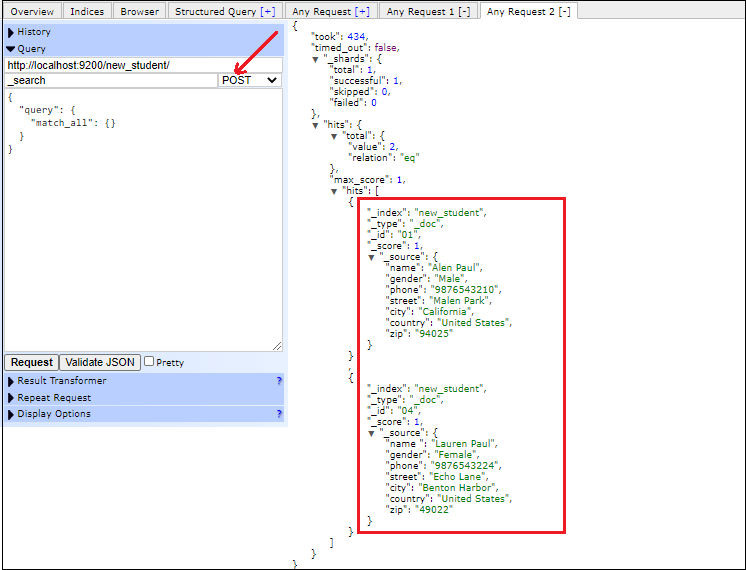
Aggregation SyntaxBasic structure of aggregation - We can use more than one aggregation in one shot. aggregation - It is an object in JSON that holds the aggregations to compute. You can also use the aggs keyword in place of aggregation. aggregation_name - Each aggregation has a logical name that is defined by the user. For example, use avg_price for computing average price. aggregation_type - It is a type of aggregation as each aggregation has a specific name. aggregation_body - Each aggregation type consists of its own aggregation body, which depends on the nature of aggregation. field - It is a field keyword. document_field_name - It is the name of the column name being targeted in a document. Types of AggregationIn Elasticsearch, several types of aggregations are available, where each aggregation has its own purpose and output. They are generalized in 4 major families for simplification, which are as follows -
Metric AggregationMetric aggregation is a type of aggregation, which is responsible for keep tracking the metrics. Metric aggregation computes the matrices from the field's values of the aggregated document. It also helps to compute the metrics over a set of documents. Some aggregations generate numeric metrics, which are either -
BucketingBucketing is a family of aggregations, which is responsible for building buckets. It does not calculate metrics over the fields like metric aggregation. In this aggregation, each bucket is associated with a key and a document. Bucket aggregation is used to group or create data buckets. These data buckets can be made based on the existing fields, ranges, and customized filters, etc. Matrix AggregationMetrix aggregation is an aggregation that operates on multiple fields. It works on more than one fields and produces a matrix result out of the values, which is extracted from the request document fields. Matrix does not support scripting. PipelineAs the name itself suggest, it takes input from the output of other aggregations. In other terms we can say that, - Pipeline aggregations are responsible for aggregating the output of other aggregations. All these aggregations are further classified, especially bucket, pipeline, and metric aggregation. Five important aggregationsSome essential aggregations of elasticsearch are described below with example. Avg AggregationAverage aggregation is used to calculate the average of any numeric field in an index. Specify the aggregation name avg in query while creating query. Look at the following example to find the average of field "fees": Copy Code By executing the above code, we will get the average of fees present in documents. Response You will get the output like the below response. If the field is missing If the field is not present (for which you are calculating average value) in the document, it gets ignored by default and a null value is returned. You can add a missing field ("missing": 0) in aggregation to consider missing value as default. Execute the following code: Copy Code Terms AggregationThe terms aggregation is responsible for generating buckets by the field values. By selecting a field (like name, admission year, etc.), it generates the buckets. Specify the aggregation name in query while creating query. Execute the following code to search the values grouped by admission year field: Copy Code By executing the above code, the output will be returned as a group by admission year. Response You will get the output like the below response. The above query and response will be looked like the below screenshot in elasticsearch-head plugin: 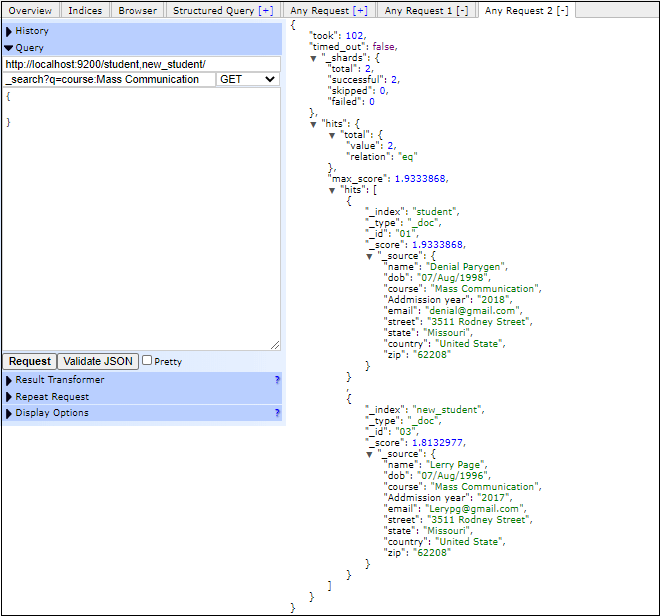
Cardinality AggregationIt is a common requirement to find a unique value for a field. Cardinality aggregation is helpful for finding unique value for any particular field. It helps to determine the number of unique elements present in an index. Specify the aggregation name in query while creating query. Execute the following code to find the number of unique values for a field: Copy Code By executing the above code, the output will return the total number of unique values for fees field present in student index. Response You will get the output like the below response. See the below screenshot, how query run in elasticsearch head plugin and responded back - 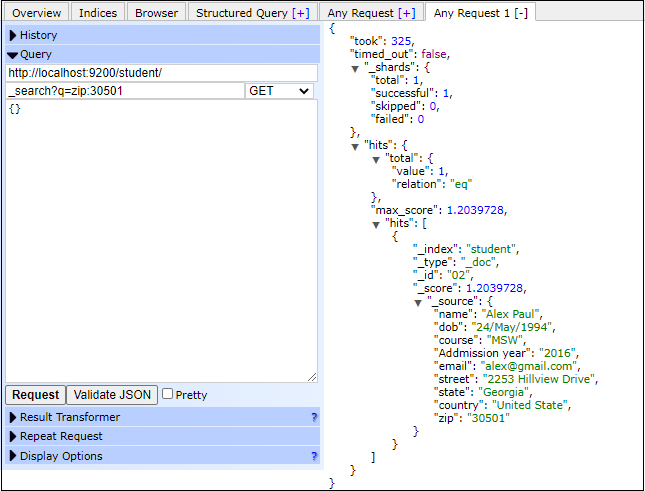
Stats AggregationStats aggregation stands for statistics, which is a multi-value numeric matric aggregation. It helps to generate sum, avg, min, max, and count in a single shot. When the aggregated documents are large, this aggregation allows to generate all the statistics for a specific numeric field. The query structure is same as the other aggregation. Execute the following code to find the sum, avg, min, max, and count in a single shot: Copy CodeResponse By executing the above code, you will get the output like the below response. Filter AggregationThe filter aggregation helps to filter the documents in a single bucket. Its main purpose is to provide the best results to its users by filtering the document. Let's take an example to filter the documents based on "fees" and "Addmission year". This will return documents that matched with the conditions specified in the query. You can filter the document using any field you want. Execute the following code to filter the document which matched with the conditions specified by you in a query: Copy Code Response By executing the above code, you will get the output like the below response. The above query and response will look like the below screenshot in elasticsearch head plugin - 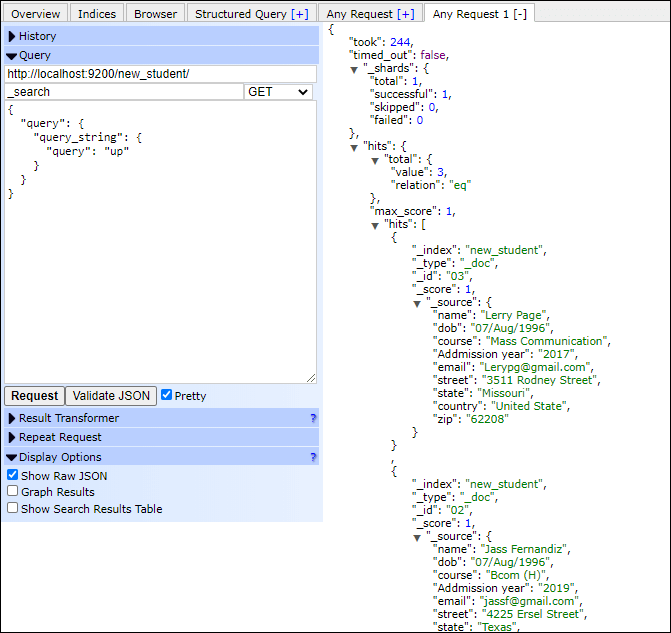
Next TopicElasticsearch Index APIs
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








