| |

ETL ArchitectureETL stands for Extract, Transform, and Load. In today's data warehousing world, this term is extended to E-MPAC-TL or Extract, Monitor, Profile, Analyze, Cleanse, Transform, and Load. In other words, ETL focus on Data Quality and MetaData. 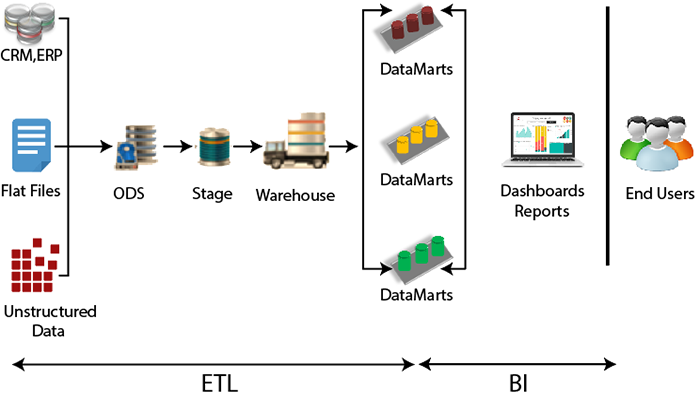
ExtractionThe main goal of extraction is to collect the data from the source system as fast as possible and less convenient for these source systems. It also states that the most applicable extraction method should be chosen for source date/time stamps, database log tables, hybrid depending on the situation. 
Transform and LoadingTransform and loading the data is all about to integrate the data and finally moving the combined data to the presentation area, which can be accessed by the front end tools by the end-user community. Here, the emphasis should be on the functionality offered by the ETL-tool and using it most effectively. It is not enough to use an ETL tool. In a medium to large scale data warehouse environment, it is important to standardize the data as much as possible instead of going for customization. ETL will reduce the throughput time of the different source to target development activities which form the bulk of the traditional ETL effort. MonitoringMonitoring of the data enables the verification of the data, which is moved throughout the entire ETL process and has two main objectives. Firstly, the data should be screened. A proper balance should be there between screening the incoming data as much as possible and not slowing down the entire ETL process when too much checking is done. Here an inside-out approach which is used in Ralph Kimbal screening technique could be used. This technique can capture all errors consistently which is based on a pre-defined set of metadata business rules and enables the reporting on them through a simple star schema, which enables a view on the data quality evolution over the time. Secondly, we should have to be focused on ETL performance. This metadata information can be plugged into all dimension and fact tables and can be called an audit dimension. Quality AssuranceQuality Assurance is a process between the different stages that could be defined depending on the need, and these processes can check the completeness of the value; do we still have the same number of records or total of specific measures between different ETL stages? This information should be captured as metadata. Finally, the data lineage should be foreseen throughout the entire ETL process, included the error records produced. Data ProfilingIt is used to generate statistics about the sources. The objective of data profiling is to know about the sources. Data profiling will use analytical techniques to discover the actual content, structure, and quality of the data by analyzing and validating the data pattern and formats and by identifying and validating redundant data across the data source. It is essential to use the correct tool, which is used to automate this process. It gives a huge amount and variety of data. Data AnalysisTo analyze the results of the profiled data, Data Analysis is used. For analyzing the data, it is easier to identify data quality problems such as missing data, inconsistent data, invalid data, constraint problems, parent-child issues such as orphans, duplicated. It is essential to capture the results of this assessment correctly. Data analysis will become the communication medium between the source and the data warehouse team for tackling the outstanding issues. The source to target mapping highly depends on the quality of the source analysis. Source AnalysisIn the source Analysis, the focus should not only on the sources but also on the surroundings, to obtain the source documentation. The future of the source applications depends upon the current data issues of origin, the corresponding data models/ metadata repositories, and receiving a walkthrough of source model and business rules by source owners. It is crucial to set up the frequent meetings with owners of the source to detect the changes which might impact the data warehouse and the associated ETL process. CleansingIn this section, the errors found can be fixed, which is based on the Metadata of a pre-defined set of rules. Here, a distinction needs to be made between completely or partly rejected records and enable the manual correction of the issues or by fixing the data by correcting the inaccurate data fields, adjusting the data format, etc. E-MPAC-TL is an extended ETL concept which tries to balance the requirements with the realities of the systems, tools, metadata, technical issues, and constraint and above all the data itself.
Next TopicETL Testing Tools
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








