| |

What is the Full Form of ETLETL: Extract, Transform and LoadETL stands for Extract, Transform and Load. Data is extracted, converted (cleaned, sanitised, and scrubbed), and then placed into an output container in a three-step process known as extract, transform, and load (ETL) in computing. The information may be compiled from one or more providers and output to one or more locations. ETL processing is commonly carried out by software programmes, although system administrators can also perform it manually. ETL software often automates the whole process and may be used to conduct individual tasks or batches of jobs either manually or on recurring schedules automatically. 
An ETL system that has been appropriately built takes data from source systems, imposes data type & data validity criteria, and ensures that the data is structurally compliant with the output requirements. For application developers to create applications and end users to make decisions, specific ETL systems may also supply data in a PowerPoint format. The ETL technique, frequently used in data warehousing, gained popularity in the early days of 1970. ETL systems often combine data from several applications (methods) that are either housed on different computer hardware or produced and maintained by various suppliers. Additionally, the stakeholders commonly manage and run the different systems that contain the original data. For instance, a cost accounting system may include purchasing, sales, and payroll information. Understanding Each Term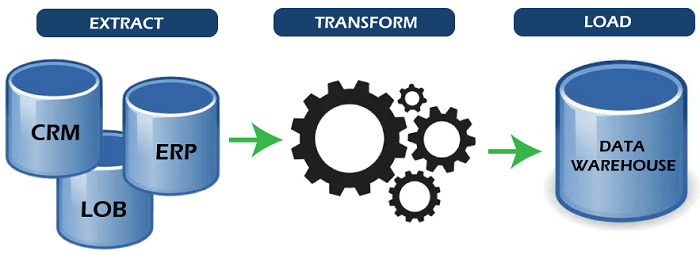
ExtractData loading refers to the process of inserting data into the final target database, such as an operational database store, a data mart, a data lake, or a data warehouse. Data extraction is the process of extracting information from homogeneous or heterogeneous references; data transformation is the processing of data by data cleaning and transformation into an appropriate storage format/structure for the specific purpose of querying and analysis. Data extraction from the originating system is part of the ETL processing process (s). Since accurate data extraction is the foundation for successful future procedures, this frequently serves as the most crucial component of ETL. The majority of data-warehousing initiatives integrate information from many source systems. Additionally, each system may use a different data structure and format. Relational databases, XML, JSON, and flat files are standard data-source formats. However, non-relational database structures like Information Management Systems (IMS), additional data structures like Virtual Storage Access Method (VSAM) or Indexed Sequential Access Method (ISAM), or perhaps even formats fetched from external sources using techniques like web spidering or screen-scraping, may also be used. When no need for intermediary data storage exists, another method of executing ETL is to stream the harvested data source and load it instantly into the target database. Data validation, which verifies that the data extracted from the source materials have the correct values in a specified domain (such as a pattern/default or set of items), is an integral aspect of the extraction process. The data is rejected entirely or partly if it doesn't pass the validation standards. It is best to return the rejected data to the original system for additional analysis to find and repair the inaccurate information. TransformThe extracted data is subjected to several rules or functions during the data transformation step to get it ready to be loaded into the final destination. Data purification, which tries to send only "correct" data to the destination, is a crucial transformation function. The difficulty arises when the pertinent systems must interface and communicate with one another. Character sets that could be offered by one system might not be useful in another. Apart from this, one or more of the following changes may be necessary to meet the technical and business requirements of the server or data warehouse:
LoadThe load stage transfers the information to the final destination, which might be a data warehouse or a straightforward delimited flat file. This method varies considerably based on the demands of the company. Some data warehouses have the potential to replace existing data with cumulative data; extracted data is often updated daily, weekly, or monthly. At regular periods, such as hourly, additional data centres (or even other portions of the same data store) may supply new data in a historical form. Imagine a database system that is necessary to keep sales records from the previous year to comprehend this. Any information older than a year is replaced by more recent data in this data warehouse. However, data is entered in a historical way for any one-year interval. Depending on the amount of time allocated and the business requirements, strategic design decisions are made on when and how much to replace or add. A record and audit trace of all modifications to the data put in the data warehouse can be kept by more complicated systems. The constraints specified in the database schema and triggers activated upon data load (such as uniqueness, referential integrity, and mandatory fields) apply as the load process and interact with a database. These constraints also influence the overall information and goods' performance of the ETL process.
ChallengesETL procedures may be complicated, and poorly designed ETL systems can even lead to serious operational issues. When validation and conversion rules are established, the range of information values or data integrity in an operational environment may surpass the expectations of the designers. The data circumstances that must be controlled by the transform rules specifications can be identified by data profiling of a resource during data analysis, which results in an alteration of the validation rules expressly and implicitly applied in the ETL process. Data sources with various formats and objectives are frequently combined to create data warehouses. To gather all the information together in a uniform, homogenous environment, ETL is a crucial step. A design analysis should determine an ETL system's scalability during its operation, considering the amounts of data that must be handled while adhering to service-level agreements. The amount of time accessible to retrieve data sources may fluctuate, which might require processing the same quantity of information in less time. To refresh data warehouses containing tens of terabytes, specific ETL systems must expand to handle terabytes of data. To continuously convert and update data, designs may need to expand from daily batches to numerous micro-batches to connect with message queuing or real-time changes in data capture. Virtual ETLData virtualisation had started to boost ETL processing by 2010. Data virtualisation's use in ETL made it possible to handle the most frequent ETL operations, such as application integration and data migration for several scattered data sources. Objects or entities acquired from a range of structured, semi-structured, and unorganised data sources are presented abstractly when doing virtual ETL. ETL tools can use object-oriented modelling and interact with permanently stored entity representations in a hub-and-spoke design that is centrally placed. A metadata repository is a collection of such terms of the things or objects acquired from data sources for ETL processing. It can exist in the mind or be made permanent. ETL tools may switch from one-time operations to persistent middleware by utilising a constant metadata library, conducting data harmonisation and data profiling regularly and almost instantly. ToolsConnectivity and scalability may be enhanced via an established ETL framework. An effective ETL tool should be able to exchange data with a wide range of database systems and read many file formats. ETL tools have begun to move into systems that do much more than just extract, convert, and load data, such as Enterprise Application Integration or even Enterprise Service Bus. Data profiling, quality, and metadata features are becoming common among ETL solutions. Converting CSV files into forms usable by relational databases is a typical use case for ETL technologies. ETL technologies enable users to enter data feeds/files that resemble CSV and integrate them into a database with the least amount of code feasible, facilitating a typical translation of millions of entries. ETL tools are often utilised by a broad spectrum of professions. From database designers in charge of business account management to computer science students wanting to swiftly import big data sets, ETL tools have evolved into a handy tool that can be relied on to achieve the best performance.
Next TopicFull Form
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








