| |

Getting started with Apache SolrSolr is a specific NoSQL technology that is optimized for a unique class of problems. Solr is a scalable, ready-to-deploy enterprise search engine that was developed to search a large volume of text-centric data and returns results sorted by relevance. Solr was created by a programmer names Yonik Seely in 2004 to add search capabilities to the company website of CNET Network. In January 2006, the Apache solr was made an open-source project under the Apache software foundation. The newest version of Apache Solr is 8.6.2. 
Apache Solr is under active development with continuous feature releases on the current major version. The previous important version will see occasional critical security- or bug fixes releases. Older versions are considered EOL (End Of Life) and will not be further updated. For this reason, it may also be challenging to obtain community support for EOL versions. Basics of Search EngineA Search engine reflects on a massive collection of Internet resource databases such as webpages, newsgroups, programs, images, etc. To locate information on the WWW (World Wide Web), we can use the search engines. A search engine can be used by passing queries into the search box in the form of keyboards or phrases. When you press Enter, it searches the database and returns relevant links to the user. 
Components of Search Engine The search engine consists of three basic components that are given below: Web Crawler: It is also known as spiders or bot. It is a software component that searches the Web to gather information. Database: Each and every information on the Web is stored in databases. It contains huge volume of web resources. Search Interfaces: It is an interface between the database and the user. It helps the user to traverse through the database. Working of Search EnginesA search application performed some or all of the following operations to return the required result. 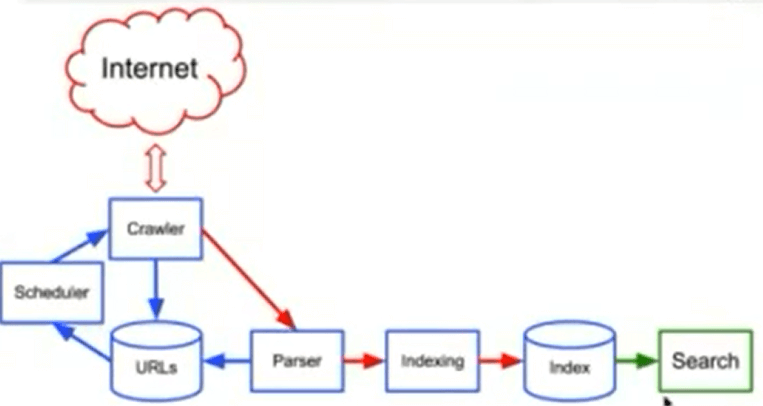
Step 1: The first step of any search application is to acquire the raw content on which search is to be conducted. Step 2: After that, build the documents from the raw contents that are understandable and interpretable easily by any search application. Step 3: Before starting indexing can start, the document is to be analyzed. Step 4: After the document has been created and analyzed, the next step is to index these documents so that it can be retrieved based on certain keys, instead of the whole contents of the document. Step 5: Once the index's database is ready, and then the application can perform search operations. For helping users in search operations, the application must be available with a user interface where the user can initiate the search process by entering text. Step 6: After creating a search request for a text, the application should prepare a query object using that text. The query object can be used to inquire about the index database to get relevant details. Step 7: After building the query object, it can be used to get the relevant details and the content documents. Step 8: Once we get the required result, the application should decide the way of displaying the results to the user of it's Interface. Before we can start developing an application using solr, we have to get it running on our local computer. It starts with downloading the binary distribution of Solr 8.6.o form Apache and extracting the download archive. For the complete installation process of Solr switch to the next page.
Next TopicInstalling Apache Solr
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








