| |

HashSet vs TreeSetIn Java, the entire Collections Framework is built upon a set of standard interfaces. Several standard implementations (such as LinkedList, HashSet, and TreeSet) of these interfaces are provided that we may use as-is. In this section, first, we will discuss HashSet and TreeSet with proper examples. Also, we will discuss the differences and similarities between HashSet and TreeSet. 
The following figure shows the hierarchy of HashSet and TreeSet in the Collections framework. 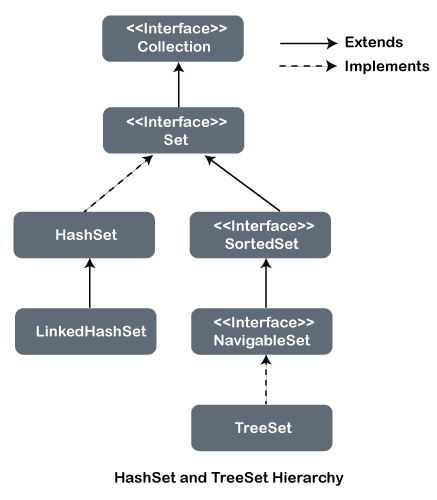
HashSetHashSet is a generic class of the Java collection framework. It extends AbstractSet and implements the Set interface. It creates a collection that uses a hash table for storage. The hash table stores the information by using the hashing mechanism. Hashing uses the informational content to determine a unique value which is known as hash code. It is used as the index in which data is stored that is associated with the key. The transformation of the key into hash code performed automatically. The benefit of hashing is that it allows the execution time of add, contain, remove, and size operation to remain constant even for large sets. Its time complexity for the operation search, insert, and delete is O(1). The HashSet class does not provide any additional methods. It uses the methods of its superclasses and interfaces. It is to be noted that it does not guarantee the order of its elements. Let's understand the HashSet through a Java program. HashSetExample.java Output 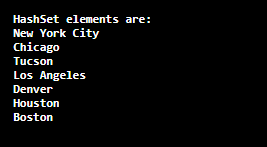
In the above output, we observe two things. The first one is the elements are not sorted in the natural order and the second thing is that the duplicate element Chicago has been removed. TreeSetTreeSet is a class of Java collection framework that extends AbstractSet and implements the Set, NavigableSet, and SortedSet interface. It creates a collection that uses a tree for storage. TreeSet is a generic class of the Java collection framework. It implements the Set interface. It uses TreeMap internally to store the TreeSet elements. By default, it sorts the elements in natural order (ascending order). The order of sorting depends on the Comparator that we have parsed. If no Comparator is parsed, it sorts the elements in the natural order. Its performance is slow in comparison to HashSet because TreeSet sorts the elements after each insertion and deletion operation. It uses two methods comaperTo() or compare() to compare the elements. It is to be noted that the implementation of TreeSet is not synchronized. It means that it is not thread-safe. The implementation must be synchronized externally if multiple threads accessing a TreeSet concurrently and a thread try to modify the TreeSet. It does not allow to store null elements. It throws NullPointerException if we try to insert a null element. It requires more memory than TreeSet because it also maintains the comparator to sort the elements. Its time complexity for the operation search, insert, and delete is O(log n) which is much higher than HashSet. It uses a self-balancing BST (Red-Black Tree) to implement the TreeSet. Let's understand the TreeSet through a Java program. TreeSetExample.java Output 
In the above output, we observe two things. The first one is the elements are sorted in the natural order and the second thing is that the duplicate elements Asus has been deleted. We have deeply understood the HashSet and TreeSet. Now, we will move to the differences between the two. Difference Between HashSet and TreeSet
There are some similarities between HashSet and TreeSet:
Which one is better to use?Use HashSet if you want elements in sorted order else use HashSet because its performance is fast in comparison to TreeSet.
Next TopicPublic Vs Private Java
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








