How does Machine Learning Work?
Introduction to Machine Learning
Machine learning is a subfield of artificial intelligence that involves developing of algorithms and statistical models to enable computers to learn and make decisions without being explicitly programmed. It is based on the idea that systems can learn from data, identify patterns, and make decisions based on those patterns without being explicitly told how to do so.
Machine learning is often used to solve problems that are too complex or time-consuming for humans to solve manually, such as analysing large amounts of data or detecting patterns in data that are not immediately apparent. It is a key technology behind many of the AI applications we see today, such as self-driving cars, voice recognition systems, recommendation engines, and computer vision related tasks.
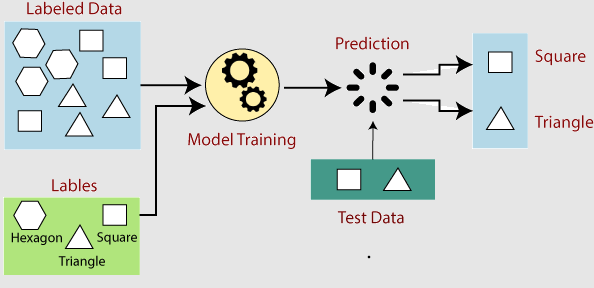
The fundamental principle of Machine Learning is to build mathematical models that can recognize patterns, relationships, and trends within dataset. These models have been trained by using labelled or unlabelled data, and their performance has been evaluated based on how well they can generalize to new, that means unseen data.
In this tutorial, we will be exploring the fundamentals of Machine Learning, including the different types of algorithms, training processes, and evaluation methods. By understanding how Machine Learning works, we can gain insights into its potential and use it effectively for solving real-world problems.
Fundamentals of Machine Learning
At its core, Machine Learning involves training a model to make predictions or decisions based on patterns and relationships in data. To understand the fundamentals of Machine Learning, it is essential to grasp key concepts such as features, labels, training data, and model optimization.
Features are the individual measurable characteristics or attributes of the data relevant to the task. For example, in a spam email detection system, features could include the presence of specific keywords or the length of the email. Labels, on the other hand, represent the desired output or outcome for a given set of features. In the case of spam detection, the label could be "spam" or "not spam" for each email.
Training data is a collection of labelled examples for training a Machine Learning model. This data consists of input features and their corresponding labels. During the training phase, the model learns the underlying patterns in the data by adjusting its internal parameters. The model's performance is evaluated using a separate data set called the test set, which contains examples not used during training.
Model optimization is a crucial step in Machine Learning. The objective is to find the best set of parameters for the model that minimizes the prediction errors or maximizes the accuracy. This is typically done through an iterative process called optimization or training, where the model's parameters are adjusted based on the discrepancy between its predictions and the actual labels in the training data.
Types of Machine Learning
Machine Learning can be broadly categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning.
- Supervised Learning: Supervised learning is a type of Machine Learning where the model learns from labelled training data. Labelled data consists of input features and their corresponding output labels. Supervised learning aims to train the model to make accurate predictions or classifications when given new, unseen data. Examples of supervised learning algorithms include linear regression, decision trees, support vector machines, and neural networks. This type of learning is commonly used in tasks such as image classification, speech recognition, and sentiment analysis.
- Unsupervised Learning: Unsupervised learning involves finding patterns, structures, or relationships in unlabelled data. Unlike supervised learning, no predefined labels or output values are provided during training. Instead, the algorithm aims to discover intrinsic patterns or groupings within the data. Clustering and dimensionality reduction are common techniques used in unsupervised learning. Clustering algorithms group similar data points together, while dimensionality reduction techniques aim to reduce the complexity of the data by identifying the most informative features. Unsupervised learning is often applied in customer segmentation, anomaly detection, and recommendation systems.
- Reinforcement Learning: Reinforcement learning is a type of Machine Learning where an agent learns to make decisions or take actions in an environment to maximize a reward signal. The agent learns through trial and error by interacting with the environment and receiving feedback through rewards or penalties. The objective is to find the optimal policy or strategy that maximizes the cumulative reward over time. Reinforcement learning has been successfully used in various applications, including game-playing, robotics, and autonomous systems.
These three types of Machine Learning form the foundation for a wide range of algorithms and techniques.
How Machine Learning Works
Machine Learning enables computers to learn from data and make predictions or decisions without explicit programming. The process involves several key steps:
- Data Collection: The first step in Machine Learning is gathering relevant data representing the problem or task at hand. This data can be collected from various sources such as databases, sensors, or online platforms.
- Data Preprocessing: Once the data is collected, it needs to be pre-processed to ensure its quality and suitability for training the model. This involves cleaning the data, handling missing values, and normalizing or transforming the data to a consistent format.
- Feature Extraction and Selection: The collected data may contain many features or attributes in many cases. Feature extraction and selection involve identifying the most informative and relevant features contributing to the learning task. This helps reduce the data's dimensionality and improves the learning process's efficiency and effectiveness.
- Model Training: The training phase involves feeding the pre-processed data into a Machine Learning algorithm or model. The model learns from the data by adjusting its internal parameters based on the patterns and relationships it discovers. This is done through iterative optimization processes, such as gradient descent or backpropagation, depending on the specific algorithm used.
- Model Evaluation: The model must be evaluated to assess its performance and generalization ability after training it. This is typically done using a separate data set called the test set, which was not used during training. Common evaluation metrics include accuracy, precision, recall, and F1 score, depending on the nature of the learning task.
- Prediction or Decision Making: Once the model is trained and evaluated, it can predict or decide on new, unseen data. The model takes input features and applies the learned patterns to generate the desired output or prediction.
- Model Refinement and Iteration: ML is an iterative process that involves refining the model based on their feedback and new dataset. If the model's performance is unsatisfactory and not accurate, then we can make adjustments by retraining the model with additional data, changing the algorithm, or tuning the model's parameters.
Evaluation and Improvement of Machine Learning Models
Once the ML model has been trained, it is essential to evaluate its performance and constantly seek ways for improving it. This process involves various techniques and strategies for assessing the model's effectiveness and enhance its predictive capabilities.
- Evaluation Metrics: To measure the performance of a Machine Learning model, specific evaluation metrics are used. The choice of metrics depends on the nature of the problem being solved. For classification tasks, metrics such as accuracy, precision, recall, and F1 score are commonly employed. For regression tasks, metrics like mean squared error (MSE) or root mean squared error (RMSE) can be used. Evaluation metrics provide quantitative measures of the model's performance, enabling comparison and assessment.
- Cross-Validation: Cross-Validation is a technique used to evaluate the performance of a model on multiple subsets of data. It helps to assess how well the model generalizes to unseen data and mitigates the potential impact of data variability. Commonly used cross-validation methods include k-fold cross-validation and stratified cross-validation. Cross-validation provides a more robust estimate of the model's performance by evaluating the model on different subsets of the data.
- Hyperparameter Tuning: Machine Learning models often have hyperparameters that are not learned from the data but set manually. Hyperparameters control aspects such as the learning rate, regularization strength, or the number of hidden layers in a neural network. Tuning these hyperparameters is essential for optimizing model performance. Techniques like grid or random search can explore different combinations of hyperparameters and identify the optimal configuration that yields the best results.
- Feature Engineering: Feature engineering involves transforming or creating new features from the existing data to enhance the model's predictive power. This process requires domain expertise and a deep understanding of the problem. Feature engineering techniques include scaling or normalizing features, encoding categorical variables, creating interaction terms, or applying dimensionality reduction methods. Well-designed features can provide more meaningful information to the model, leading to improved performance.
- Ensemble Methods: Combining multiple individual models to obtain a more accurate and robust prediction. Techniques such as bagging, boosting, and stacking are commonly used in ensemble learning. By aggregating the predictions of multiple models, ensemble methods can reduce bias and variance and improve the overall predictive performance.
- Monitoring and Maintenance: ML models require continuous monitoring and maintenance. The model's performance may degrade as new data becomes available or the problem domain changes. Monitoring and retraining the model's performance with updated data helps maintain its accuracy and relevance over time.
Conclusion
In this tutorial, we have explored the fundamental concepts and processes of Machine Learning. We also learned how Machine Learning enables computers to learn from data and make predictions or decisions without explicit programming.
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








