Informatica interview questions

A list of top frequently asked Informatica Interview Questions and answers are given below.
1) What is Informatica? Why do we need it?
Informatica is a software development firm founded in 1993 by Gaurav Dhillon and Diaz Nesamoney. Informatica is an ETL tool that offers data integration solutions. ETL tools are the tools used to extract, transform, and load the data. Therefore, we can say that Informatica is an ETL tool used to extract the data from one database and stores it in another database.
- Extract: The Extract is a process of extracting the data from one database. In this phase, an ETL tool extracts the data from multiple sources. Validation rules are applied to test whether they matches the expected values or not. If it fails the validation, data will be rejected.
- Transform: Transform is the process of converting the one form into another form in such a way the data can be placed in another database as well. Transformations include data formatting, resorting the column or row data, combining the two values into one and splitting the data into two or three values.
- Load: In the load phase, data is moved to the target database. Once the data is loaded, the ETL process is completed.
2) What are the popular Informatica products?
The following are the popular Informatica products:
- Power Center
- Power Mart
- Power Exchange
- Power Center Connect
- Power Channel
- Metadata Exchange
- Power Analyzer
- Super Glue
3) What is Informatica PowerCenter?
Informatica PowerCenter is an ETL tool used to build the enterprise data warehouses. It is highly available, fully-scalable, and high performing tool.
It provides reliable solutions to the IT management team as it delivers not only data to meet the operational and analytical requirements of the business, but also supports various data integration projects
4) What is a data warehouse?
- The data warehouse is a technique of integrating data from multiple sources. It involves analytical reporting, data integration, data cleaning, and data consolidations.
- A data warehouse is mainly designed for query and data analysis purpose instead of transaction processing.
- It is used to transform the information into useful data whenever the user required.
- The data warehouse is an environment, not a product that provides the current and historical decision support information to the users, which is not possible to access the traditional operational database.
- The data which is processed and transformed in the data warehouse can be accessed by using the Business Intelligence tools, SQL Clients, and spreadsheets.
5) How can Informatica be used for an organization?
Informatica in an organization can be used in the following ways:
- Data Migration: Data Migration means transferring the data from the traditional system to a new database system.
- Data Warehousing: Informatica is an ETL tool used for moving the data from the database or production system to the data warehouse. This process is known as Data Warehousing.
- Data Integration: Data Integration means integrating the data from multiple sources or file-based systems. For example, cleaning up the data.
6) Explain the Informatica workflow?
Informatica workflow is a collection of tasks which are connected with the starting task and triggers the proper sequence to execute the process.
Workflow is created either manually or automatically by using the workflow designer tool.
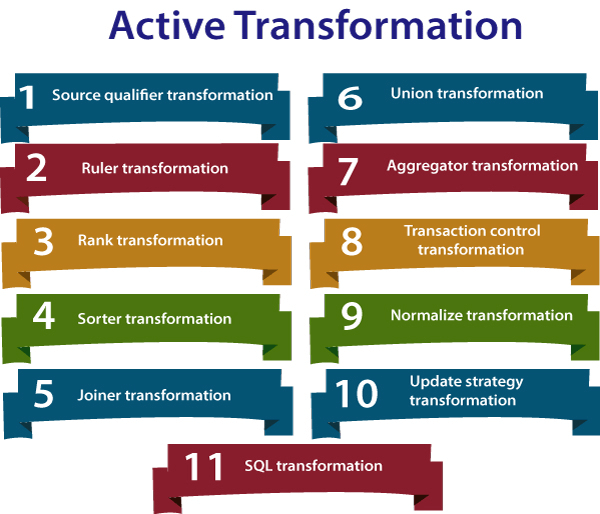
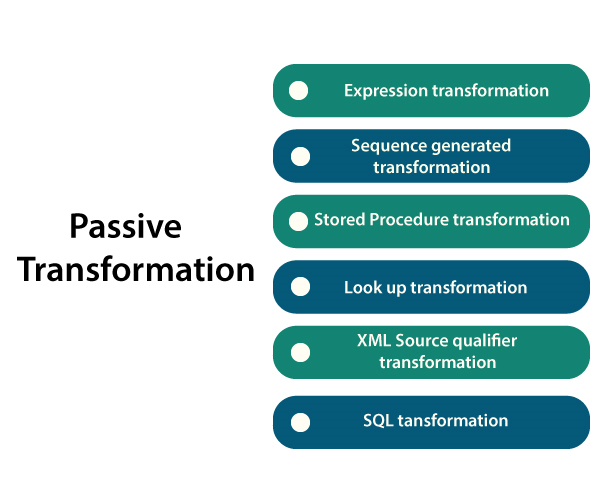
7) Mention some types of transformation?
8) What is the difference between active and passive transformation?
An active transformation is a transformation that changes the number of rows when the source table is passed through it. For example, Aggregator transformation is a type of active transformation that performs the aggregations on groups such as sum and reduces the number of rows.
A passive transformation is a transformation that does not change the number of rows when the source data is passed through it, i.e., neither the new rows are added, nor existing rows are dropped. In this transformation, the number of output and input rows are the same.
9) Explain the difference between a data warehouse and a data mart?
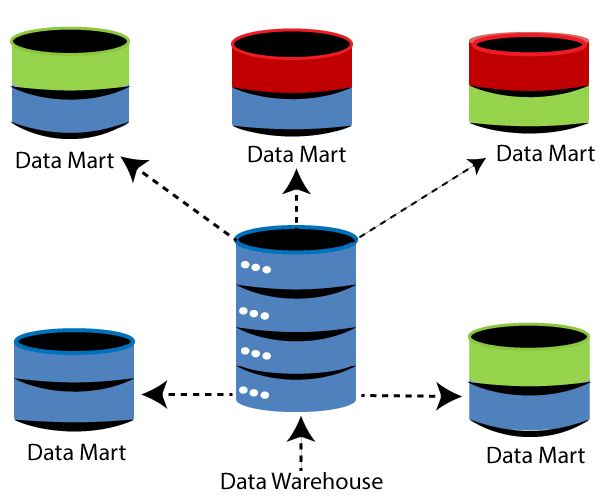
Data warehouse and Data mart are the structured repositories that store and manage the data. A data warehouse is used to store the data centrally for the entire business while data mart is used to store the specific data, not the entire business data. Querying the data from the data warehouse is a very tedious task, so data mart is used. The data mart is a collection of smaller sets of data which allows you to access the data faster and efficiently.
10) What is repository manager?
A repository is a place or a relational database used to store the information or metadata. Metadata can include various information such as mappings that describes how to transform the data, sessions describe when you want the Informatica server to perform the transformations, also stores the administrative information such username and password, permissions and privileges, and product version. The repository is created and maintained by the Repository Manager client tool.
Repository Manager is a manager that manages and organizes the repository. Repository Manager can create the folders to organize the data and groups to handle multiple users.
11) What is mapping?
Mapping is a pipeline or structural flow of data that describes how data flows from source to the destination through transformations.

Mapping consists of the following components:
- Source Definition: Source Definition defines the structure and characteristics of the source such as data types, type of the data source, etc. You can create more than one source definitions by using the Informatica Source Analyzer.
- Target Definition: Target Definition defines the final destination or target where the data will be loaded.
- Transformation: Transformation defines how source data should be transformed, and various functions are applied during the transformation process.
- Links: Links define how data should flow from source definition to the target table by performing different transformations.
12) What is session?
- A session is a property in Informatica that have a set of instructions to define when and how to move the data from the source table to the target table.
- A session is like a task that we create in workflow manager. Any session that you create must have a mapping associated with it.
- Session must have a single mapping at a time, and it cannot be changed.
- In order to execute the session, it must be added to the workflow.
- A session can either be a reusable or non-reusable object where reusable means that we can use the data for multiple rows.
13) What is Designer?
A designer is a graphical user interface that builds and manage the objects like source table, target table, Mapplets, Mappings, and transformations.
Mapping in Designer is created by using the Source Analyzer to import the source table, and target designer is used to import the target table.
Designer components:
Designer contains multiple components:
- Navigator
Navigator is used to perform the following activities:
- It is used to connect with Repository service.
- It is used to open folders.
- It is used to copy objects and to create the shortcuts.
- Workspace
- Workspace is a space where we do the coding.
- In a workspace, we can create as well as edit the repository objects such as sources, targets, mapplets, mappings, and transformations.
- Toolbar
Different components in the toolbar are available such as Repository, edit, tools, versioning, windows, and help.
- Output/Control panel
It displays the output about the task that we perform in designer such as mapping is valid or not, is mapping saved or not, and it also displays the errors.
- Status bar
The status bar displays the status of the current operation.
14) What is domain?
- The domain is a collection of nodes (machines) and services, i.e., repository service, integration service, nodes, etc.
- It is an administrative unit from where you manage or control things such as configurations, users, security.
- The domain is an environment where you can have a single domain as well as multiple domains. For example, we have three departments such as development, test, and production; then we will have a domain for each department, i.e., we have three domains.
15) What is Workflow Manager?
Workflow Manager is used to create Workflow and Worklet.
- Workflow
- Workflow is a set of instructions used to execute the mappings.
- The workflow contains various tasks such as session task, command task, event wait task, email task, etc. which are used to execute the sessions.
- It is also used to schedule the mappings.
- All the tasks are connected to each other through links inside a workflow.
- After creating the workflow, we can execute the workflow in the workflow manager and monitor its progress through the workflow monitor.
- Worklet
- Worklet is an object that groups a set of tasks which can be reused in multiple workflows.
- A worklet is similar to a workflow, but it does not have any scheduling information.
- In worklet, you can group the tasks in a single place so that it can be easily identified.
16) What is Workflow Monitor?
Workflow Monitor is used to monitor the execution of workflows or the tasks available in the workflow. It is mainly used to monitor the progress of activities such as Event log information, a list of executed workflows, and their execution time.
Workflow Monitor can be used to perform the following activities:
- You can see the details of execution
- You can see the history of workflow execution
- You can stop, abort, or restart the workflows.
- It displays the workflows that have been executed at least once.
It consists of the following windows:
- Navigator window: It displays the repositories, servers, and repositories objects that have been monitored.
- Output window: It displays messages coming from the Integration service and Repository service.
- Time window: It displays the progress of workflow execution.
- Gantt Chart view: It displays the progress of the workflow execution in a tabulated form.
- Task view: It displays the details about the workflow execution in a report format.
17) Explain the types of transformations?
Transformations are used to transform the source data into target data. It ensures that the data will be loaded to the target database based on the requirements of the target system.
A transformation is basically a repository object that can read, modify, and passes the data from source to the target.
There are two types of transformations:
- Active transformation
Active transformation is a transformation which can modify the number of rows that passes from source to the target, i.e., it can eliminate the rows that do not meet the condition in transformation.
- Passive transformation
Passive transformation is a transformation that does not eliminate the number of rows, i.e., all the data passes from source to the target without any modification.
18) What is SQ transformation?
- SQ stands for Source Qualifier transformation that selects the records from multiple sources, and the sources can be relational tables, flat files, and Informatica PowerExchange services.
- It is an active and connected transformation.
- When you add the source tables in mapping, then Source Qualifier is added automatically.
- It displays the transformation types, i.e., it converts the source datatypes into an Informatica compatible datatypes.
- In the case of SQ transformation datatypes, source datatype does not match with the Informatica compatible datatype then the mapping will become invalid when you save it.
- SQ transformation is an active transformation as you can apply all the business rules and filters to overcome the performance issue.
- By using SQ transformation, you can apply filters on the data by applying joins on the tables.
- Source Qualifier transformation can also join homogeneous tables, i.e., data originating from the same database into a single SQ transformation.
Following are the properties of SQ transformation:
- User Defined SQL Query
- User Defined Joins
- Add/Modify WHERE clause using Filter
- Add/Modify ORDER BY sorted ports
- Select Unique/Distinct rows
19) What is an Expression Transformation?
- Expression Transformation is a passive and connected transformation.
- It is used to manipulate the values in a single row.
- Examples of expression transformation are concatenating the first name and last name, adjusting the student records, converting strings to date, etc.
- It also checks the conditional statements before passing the data to other transformations.
- Expression transformation uses numeric and logical operators
Following are the operations performed by the expression transformer are:
- Data manipulation
It performs operations such as concatenation, truncation, and round.
- Datatype conversion
It can also convert one data type into another data type.
- Data cleansing
It checks for nulls, test for spaces, test for numbers.
- Manipulate dates
It can also manipulate the dates.
- Scientific calculations and numerical operations
It also performs the exponential, log, modulus, and power operations.
There are three types of ports used in Expression Transformation:
- Input
An input port consists of values which are used in the calculation. For example, we need to calculate the total salary; then it will be calculated only when we know the salary and incentives of an employee.
- Output
We provide expression to each output port, and the return value of the output port should match the return value of the expression.
- Variable
It is a temporary variable used in the calculation.
20) What is a Sorter Transformation?
- It is an active and connected transformation.
- It is used to sort the data either in ascending or in descending order, similar to the ORDER BY clause in SQL.
- It is also used in case-sensitive sorting, and also used to specify whether the output rows should be distinct or not.
- Sorter transformation is an active transformation as it eliminates duplicates.
Properties of Sorter Transformation:
- Sorter cache size
An integration service uses sorter cache size property to determine the maximum amount of memory required to perform the sort operation.
- Case Sensitive
You can also enable the case-sensitive property; in such case, an integration service will give more priority to the uppercase characters than lowercase characters.
- Work directory
Work directory is a directory where integration service creates temporary files while sorting the data. When data is sorted, then all the temporary files will be removed from the work directory.
- Distinct Output Rows
This property is used by the integration service to produce the distinct output rows.
- Tracing Level
The tracing level is a property that controls the number, type of sorter error, and status messages that integration service writes to the session log.
- Null Treated Low
Enable this property when you want integration service treat null value lower than other value. Disable this property when you want to treat the null value higher than the other value.
21) What is an Aggregator Transformation?
- Aggregator transformation is a connected and active transformation.
- It is used to perform aggregate functions over a group of rows such as sum, average, count, etc., similar to the aggregate functions in SQL such as sum(), avg(), count(), etc.
- For example, if you want to calculate the sum of the salary of all the employees, then an aggregator transformation is used.
- Aggregator transformation uses the temporary main table to store all the records, and perform the calculations.
Components of Aggregator transformation:
- Aggregate cache
An integration service uses the aggregate cache to store the data until the aggregate calculation is completed. It stores the group values in index cache and row data in the data cache.
- Aggregate expression
An aggregate expression is provided to the output port and output port can also contain non-aggregate expressions and conditional clauses.
- Group by port
This property is used to create the groups. Groups can be input, output, or any variable port.
- Sorted input
Sorted input property is used to improve the session performance. In order to use sorted input, you need to pass the data to aggregator transformation sorted by group by port either in ascending or in descending order.
22) What is a Filter Transformation?
- Filter transformation is an active and connected transformation.
- It filters out the rows which are passed through it, i.e., it changes the number of rows which are passed through.
- It applies the filter condition on the group of data. This filter condition returns an either true or false value. If the value is true means that the condition is satisfied, then data is passed through, and if the value is false means that the filter condition is not satisfied, then integration service drops the data and writes the message to the session log.
23) What is a Joiner Transformation?
- Joiner Transformation is an active and connected transformation.
- It allows you to create the joins in Informatica, similar to the joins that we create in database.
- In joiner transformation, joins are used for two sources and these sources are:
- Master source
- Detail source
In joiner transformation, you need to choose which data source will be Master, and which data source will be Detail.
There are four types of joins used in a joiner transformation:
- Master outer join
In Master outer join, the resultset contains all the records from the Detail source and the matching rows in the master source. This join will be similar to the Right join in SQL.
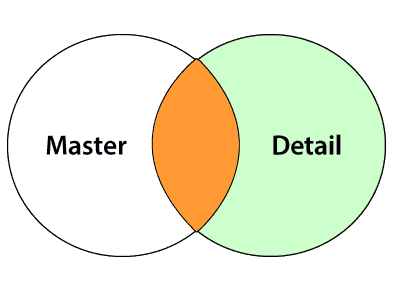
- Detail outer join
In Detail outer join, the resultset contains all the records from the Master source and the matching rows in the Detail source. This join will be similar to the Left join in SQL.
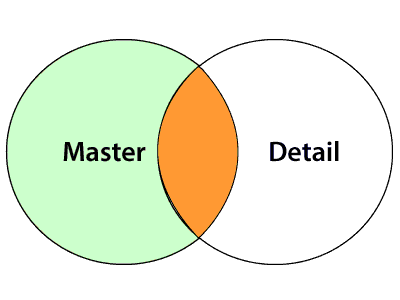
- Full outer join
In Full outer join, the resultset contains all the records from both the sources, i.e., Master and Detail source.
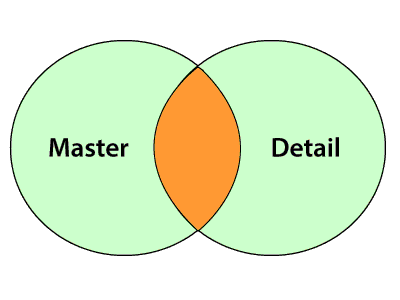
- Normal join
In Normal join, the resultset contains only the matching rows between Master and Detail source. This join is similar to the inner join in SQL.
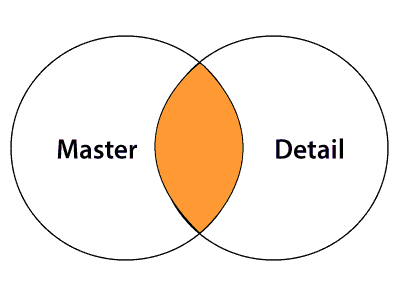
24) What is a Router Transformation?
- Router transformation is an active and connected transformation.
- Router transformation is similar to the filter transformation as both the transformations test the input data based on the filters.
- In Filter transformation, you can apply only one filter or condition, and if the condition is not satisfied, then a particular is dropped. But in Router transformation, more than one condition can be applied. Therefore, we can say that the single input data can be checked on multiple conditions.
25) What is Rank Transform?
- Rank transformation is an active and connected transformation.
- It filters the data based on groups and ranks.
- For example, if you want to get top 3 salaried employees department wise, then this will be achieved by the rank transformation.
- Rank transform contains an output port which assigns a rank to the rows.
26) What is a Sequence Generator Transformation?
- Sequence Generator transformation is a passive and connected transformation.
- It is a type of transformation that generates numeric values.
- It creates unique primary key values, replaces missing primary keys, or cycle through a sequential range of numbers.
27) What is a Stored Procedure Transformation?
- It is a passive transformation.
- It can be used in both connected and unconnected mode.
- Informatica contains the stored procedure transformation which is used to run the stored procedures in the database where stored procedures are pre-compiled PL-SQL statements, and these pre-compiled statements are executed using Execute or Call statements.
There are three types of data that can be passed between the integration service and stored procedure:
- Input/Output parameters
It is used to send or receive the data from the stored procedure.
- Return values
On running a stored procedure, it returns a single value, and the value can be user-definable, single output value or only a single integer value. If the stored procedure returns resultset, then stored transformation accepts the only first value of the resultset.
- Status codes
Stored procedure transformation provides a status code that notifies whether the stored procedure has been completed successfully or not.
28) What is lookup Transformation?
- Lookup transformation is active as well as passive transformation.
- It can be used in both connected and unconnected mode.
- It is used to look up the data in a source, source qualifier, flat file, or a relational table to retrieve the data.
- We can import the definition of lookup from any flat file or relational database, and an integration service queries the lookup source based on the ports, lookup condition and then returns the result to other transformations.
Lookup transformation can be in two modes:
- Lookup table
The Lookup table is imported either from the mapping source or target database using the Informatica client and server.
- Lookup condition
Lookup condition determines whether the input data satisfies the value in the lookup table or not.
The following are the activities performed by the lookup transformation:
- Get a Related value
It can be used to retrieve the value from the lookup table based on the value available in the source table. For example, we want to retrieve the student name from the lookup table based on the student id in the source table.
- Get multiple values
It can also be used to retrieve the multiple rows from a lookup table. For example, we want to retrieve all the students branch wise.
- Perform a calculation
It can used to retrieve the value from a lookup table and can perform the calculation on it. For example, retrieve the marks of students and then calculate their percentages.
- Update slowly changing dimension tables
It determines whether the rows exist in a target table or not.
29) What is Union transformation?
- Union transformation is an active transformation.
- It is similar to the SQL Union All, i.e., it combines the data from the multiple files and produces the single output and then store it in the target table.
Guidelines of Union transformation
- Union transformation contains multiple output groups, but one input group.
- It does not remove duplicates from the input source. To overcome this issue, we use the sorter transformation in which we use the select distinct statement to remove the duplicate rows.
- It does not generate any transaction.
- You cannot connect to a sequence generator transformation to generate the sequences.
30) What is Update Strategy transform?
- It is an active and connected transformation.
- This type of transformation can be used to insert, update, or delete the records from the target table.
- It can even reject all the records to avoid reaching to the target table
The design of the target table depends on how the changes are made in the existing row. An update strategy transform works in two levels:
- Session level
When we configure the session, we can either instruct the integration service to treat all the rows in the same way, i.e., treat all rows as insert/delete/update, or you can use the instruction coded in session mapping to flag rows for performing different database operations.
- Mapping level
Within mapping, you can apply update strategy transformation to flag rows either for insert, update, delete, or reject.
31) What are the tasks that can be performed using SQ?
The following are the tasks performed by using SQ:
- Joins
You can join two or more tables belonging to the same database, and by default, all the tables are joined by using the primary key and foreign key relationship. We can also explicitly specify the join condition in user-defined join property.
- Filter rows
You can also filter the rows. An integration service adds a WHERE clause to filter the rows.
- Sorting input
You can also sort the input data by specifying the numbers of sorted inputs. An integration service uses the ORDER BY clause by default to sort the input data.
- Distinct rows
You can also select the distinct rows from the source table by selecting the Select Distinct property; then integration service will add the Select Distinct statement to the default SQL query.
- Custom SQL Query
You can also write your own queries to perform the calculations on the source data.
|






