| |

K-Medoids clustering-Theoretical ExplanationK-Medoids and K-Means are two types of clustering mechanisms in Partition Clustering. First, Clustering is the process of breaking down an abstract group of data points/ objects into classes of similar objects such that all the objects in one cluster have similar traits. , a group of n objects is broken down into k number of clusters based on their similarities. Two statisticians, Leonard Kaufman, and Peter J. Rousseeuw came up with this method. This tutorial explains what K-Medoids do, their applications, and the difference between K-Means and K-Medoids. K-medoids is an unsupervised method with unlabelled data to be clustered. It is an improvised version of the K-Means algorithm mainly designed to deal with outlier data sensitivity. Compared to other partitioning algorithms, the algorithm is simple, fast, and easy to implement. The partitioning will be carried on such that:
Here is a small recap on K-Means clustering:In the K-Means algorithm, given the value of k and unlabelled data:
The problem with the K-Means algorithm is that the algorithm needs to handle outlier data. An outlier is a point different from the rest of the points. All the outlier data points show up in a different cluster and will attract other clusters to merge with it. Outlier data increases the mean of a cluster by up to 10 units. Hence, K-Means clustering is highly affected by outlier data. K-Medoids:Medoid: A Medoid is a point in the cluster from which the sum of distances to other data points is minimal. (or) A Medoid is a point in the cluster from which dissimilarities with all the other points in the clusters are minimal. Instead of centroids as reference points in K-Means algorithms, the K-Medoids algorithm takes a Medoid as a reference point. There are three types of algorithms for K-Medoids Clustering:
PAM is the most powerful algorithm of the three algorithms but has the disadvantage of time complexity. The following K-Medoids are performed using PAM. In the further parts, we'll see what CLARA and CLARANS are. Algorithm:Given the value of k and unlabelled data:
Here is an example to make the theory clear: Data set:
Scatter plot: 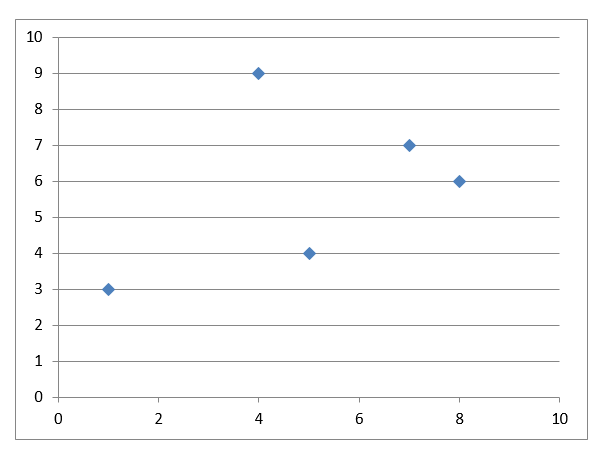
If k is given as 2, we need to break down the data points into 2 clusters.
Manhattan Distance: |x1 - x2| + |y1 - y2|
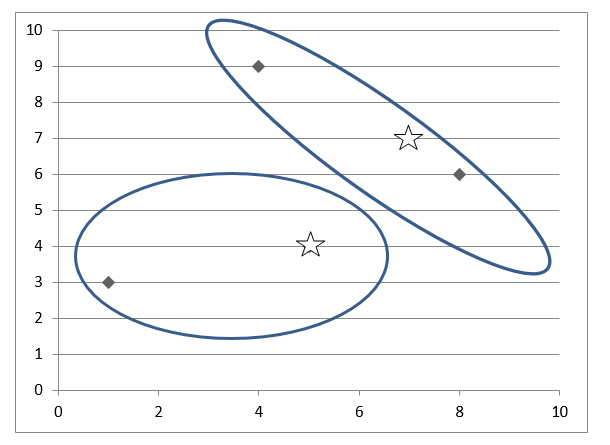
Cluster 1: 0 Cluster 2: 1, 3
M1(5, 4) and M2(4, 9):
Cluster 1: 2, 3 Cluster 2: 1
M1(5, 4) and M2(7, 7)
Cluster 1: 2 Cluster 2: 3, 4
M1(7, 7) and M2(8, 6)
Cluster 1: 4 Cluster 2: 0, 2
Limitation of PAM:Time complexity: O(k * (n - k)2)Possible combinations for every node: k*(n - k) Cost for each computation: (n - k) Total cost: k*(n - k)2 Hence, PAM is suitable and recommended to be used for small data sets. CLARA:It is an extension to PAM to support Medoid clustering for large data sets. This algorithm selects data samples from the data set, applies Pam on each sample, and outputs the best Clustering out of these samples. This is more effective than PAM. We should ensure that the selected samples aren't biased as they affect the Clustering of the whole data. CLARANS:This algorithm selects a sample of neighbors to examine instead of selecting samples from the data set. In every step, it examines the neighbors of every node. The time complexity of this algorithm is O(n2), and this is the best and most efficient Medoids algorithm of all. Advantages of using K-Medoids:
Disadvantages:
K-Means and K-Medoids:
Useful Outlier Clusters:For suppose, A data set with data on people's income is being clustered to analyze and understand individuals' purchasing and investing behavior within each cluster. Here outlier data will be people with high incomes-billionaires. All such people tend to purchase and invest more. Hence, a separate cluster for billionaires would be useful in this scenario. In K-Medoids, It merges this data into the upper-class cluster, which loses the meaningful outlier data in Clustering and is one of the disadvantages of K-Medoids in special situations. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








