| |

Convolutional Neural NetworkConvolutional Neural Networks are a special type of feed-forward artificial neural network in which the connectivity pattern between its neuron is inspired by the visual cortex. 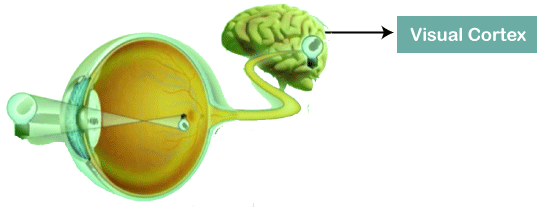
The visual cortex encompasses a small region of cells that are region sensitive to visual fields. In case some certain orientation edges are present then only some individual neuronal cells get fired inside the brain such as some neurons responds as and when they get exposed to the vertical edges, however some responds when they are shown to horizontal or diagonal edges, which is nothing but the motivation behind Convolutional Neural Networks. The Convolutional Neural Networks, which are also called as covnets, are nothing but neural networks, sharing their parameters. Suppose that there is an image, which is embodied as a cuboid, such that it encompasses length, width, and height. Here the dimensions of the image are represented by the Red, Green, and Blue channels, as shown in the image given below. 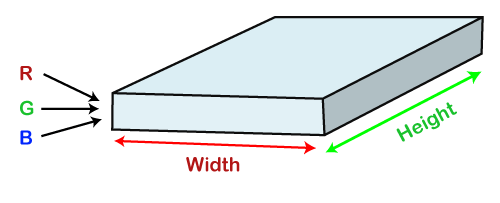
Now assume that we have taken a small patch of the same image, followed by running a small neural network on it, having k number of outputs, which is represented in a vertical manner. Now when we slide our small neural network all over the image, it will result in another image constituting different width, height as well as depth. We will notice that rather than having R, G, B channels, we have come across some more channels that, too, with less width and height, which is actually the concept of Convolution. In case, if we accomplished in having similar patch size as that of the image, then it would have been a regular neural network. We have some wights due to this small patch. 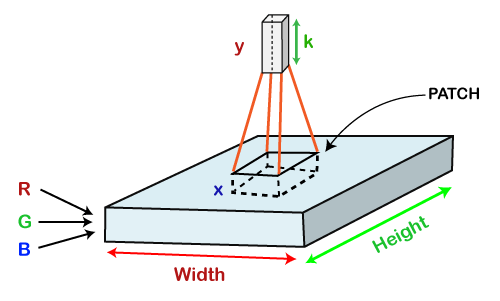
Mathematically it could be understood as follows;
Working of CNNGenerally, a Convolutional Neural Network has three layers, which are as follows;
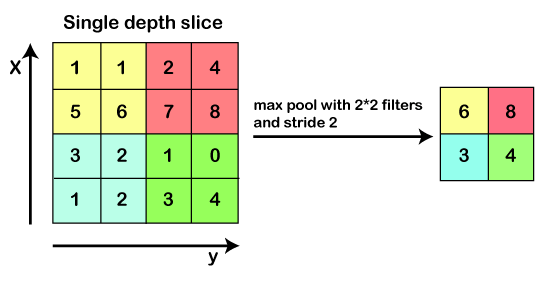
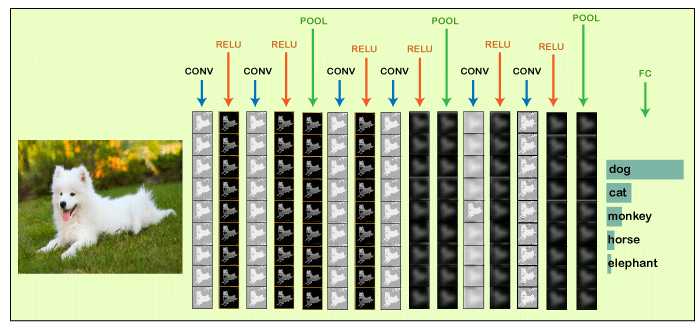
We will start with an input image to which we will be applying multiple feature detectors, which are also called as filters to create the feature maps that comprises of a Convolution layer. Then on the top of that layer, we will be applying the ReLU or Rectified Linear Unit to remove any linearity or increase non-linearity in our images. Next, we will apply a Pooling layer to our Convolutional layer, so that from every feature map we create a Pooled feature map as the main purpose of the pooling layer is to make sure that we have spatial invariance in our images. It also helps to reduce the size of our images as well as avoid any kind of overfitting of our data. After that, we will flatten all of our pooled images into one long vector or column of all of these values, followed by inputting these values into our artificial neural network. Lastly, we will feed it into the locally connected layer to achieve the final output. 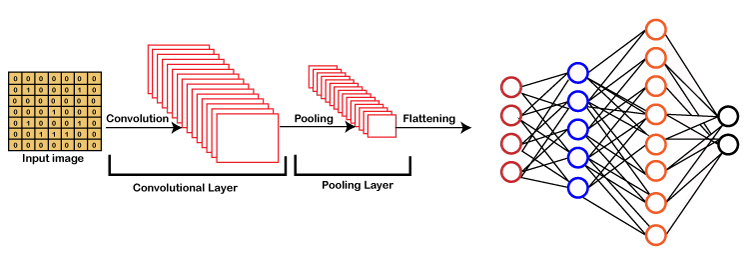
Building a CNNBasically, a Convolutional Neural Network consists of adding an extra layer, which is called convolutional that gives an eye to the Artificial Intelligence or Deep Learning model because with the help of it we can easily take a 3D frame or image as an input as opposed to our previous artificial neural network that could only take an input vector containing some features as information. But here we are going to add at the front a convolutional layer which will be able to visualize images just like humans do. In our dataset, we have all the images of cats and dogs in training as well as in the test set folders. We are going to train our CNN model on 4000 images of cats as well as 4000 images of dogs, each respectively that are present in the training set followed by evaluating our model with the new 1000 images of cats and 1000 images of dogs, each respectively in the test set on which our model was not trained. So, we are actually going to build and train a Convolutional Neural network to recognize if there is a dog or cat in the image. For the implementation of CNN, we are going to use the Jupyter notebook. So, we will start with importing the libraries, data preprocessing followed by building a CNN, training the CNN and lastly, we will make a single prediction. All the steps will be carried out in the same way as we did in ANN, the only difference is that now we are not pre-processing the classic dataset, but some images, which is why the data preprocessing is different and will consist of doing two steps, i.e., in the first, we will pre-process the training set and then will pre-process the test set. In the second part, we will build the whole architecture of CNN. We will initialize the CNN as a sequence of layers, and then we will add the convolution layer followed by adding the max-pooling layer. Then we will add the second convolutional layer to make it a deep neural network as opposed to a shallow neural network. Next, we will proceed to the flattening layer to flatten the result of all the convolutions and pooling into a one-dimensional vector, which will become the input of a fully connected neural network. Finally, we will connect all this to the output layer. In the third part, we will first compile the CNN, and then we will train the CNN on the training set. And then, finally, we will make a single prediction to test our model in a prediction that is when we will deploy our CNN on to different images, one that has a dog and the other that has a cat. So, this was just a brief description of how we will build our CNN model, let's get started with its practical implementation. We will start by importing the TensorFlow library and actually the preprocessing module by Keras library. And then, we will import the image sub-module of the preprocessing module of the Keras library, which will allow us to do image pre-processing in part 1. Output 
It can be seen that we have successfully run our first cell from the image given above. Using TensorFlow backend, which is the output of the first cell, and in order for this to work this way, we have to make sure to run pip install commands of TensorFlow and Keras. Next, we will check the version of the TensorFlow. Output 
It can be seen that the version of TensorFlow is 2.0.0. After this, we will move on to Part1: Data Pre-processing, which will be done in two steps, i.e., firstly, we will preprocess the training set, and secondly, we will preprocess the test set. Part1: Data Pre-processingPreprocessing the Training set We will apply some transformations on all the images of the training set but not on the images of the test set, so as to avoid overfitting. Indeed, if we don't apply these transformations while training our CNN on the training set, we will get a huge difference between the accuracy on the training set and the one on the test set. For the computer vision, the way to avoid overfitting is to apply the transformations, which are nothing but a simple geometrical transformation or some zoom or some rotations on the images. So, basically, we are going to apply some geometrical transformations to shift some of the pixels followed by rotating a bit the images, we will be doing some horizontal flips, zoom in as well as zoom out. We are actually going to apply some series of transformations to modify the images and get them augmented, which is called image augmentation. It actually consists of transforming the images of the training set so that our CNN model doesn't overlearn. We will create an object of train_datagen of the ImageDataGenerator class that represents the tool that will apply all the transformations on the images of the training set, such that the rescale argument will apply feature scaling to each and every single one the pixel by dividing their value 255 as each pixel take a value between 0 and 255, which is really necessary for neural networks and the rest are the transformations that will perform image augmentation on the training set images so as to prevent the overfitting. After this, we will need to connect the train_datagen object to the training set, and to do this, we will have to import the training set, which can be done as given below. Here training_set is the name of the training set that we are importing in the notebook, and then we indeed take our train_datagen object so as to call the method of ImageDataGenerator class. The method that we will call is the flow_from_directory that will help to connect the image augmentation tool to the image of the training set. we will pass the following parameter;
Output 
After running the above cell, which is Preprocessing the Training Set, we will get in the output from the above image that indeed we imported and preprocessed with the data augmentation; 8000 images belonging to 2 classes, i.e., dogs and cats. Preprocessing the Test set After we are done with preprocessing the training set, we will further move on to preprocessing the test set. We will again take the ImageDataGenerator object to apply transformations to the test images, but here we will not apply the same transformations as we did in the previous step. However, we need to rescale their pixels the same as before because the future predict method of CNN will have to be applied to the same scaling as the one that was applied to the training set. Here test_set is the name of the test set that we are importing in the notebook, and then we indeed take our test_datagen, which will only apply if it is going to the pixels of the test set images. Then we call the same flow_from_directory function to access the test set from the directory. Then we will need to have the same target_size, batch_size, and class_mode as used in the previous step. Output 
We can see from the above image, which we got after running Preprocessing the Test Set cell, that 2000 images belong to 2 classes. Instead of applying image augmentation, we have only applied feature scaling. Part2: Building the CNNIn part two, we are going to build together the convolutional neural network and, more specifically, the whole architecture of the artificial neural network. So, it is actually going to start the same as with our artificial neural network because the convolutional neural network is still a sequence of layers. Therefore, we are going to initialize our CNN with the same class, which is the sequential class. Initializing the CNN So, this is the first step where we are not only going to call the sequential class but will actually create the cnn variable, which will represent this convolutional neural network. And this cnn variable will be created once again as an instance of that sequential class allows us to create an artificial neural network as a sequence of layers. First, we will need to call the TensorFlow that has a shortcut tf from which we are going to call Keras library from where we are going to get access to the model's module, or we can say from where we are going to call that sequential class. After this, we will step by step use the add method to add different layers, whether they are convolutional layers or fully connected layers, and in the end, the output layer. So, we are now going to successfully use the add method starting with the step1: convolution. Step1: Convolution We will first take the cnn object or the convolutional neural network from which we will call the add method to add our very first convolutional layer, which will further be an object of a certain class, i.e., Conv2D class. And this class, just like the dense class that allows us to build a fully connected layer, belongs to the same module, which is the layer module from the Keras library, but this time it is the TensorFlow. Inside the class, we are going to pass three important parameters, which are as follows:
Step2: Pooling Next, we will move on to applying pooling, and more specifically, if we talk about, we are going to apply the max pooling, and for that, we will again take cnn object from which we are going to call our new method. Since we are adding the pooling layer to our convolutional layer, so we will again call the add method, and inside it, we will create an object of a max-pooling layer or an instance of a certain class, which is called MaxPool2D class. Inside the class, we will pass pool_size and strides parameters. Adding a second layer Now we will add our second layer, for which again we have to undergo applying convolutional as well as pooling layer just like we did in the previous step, but here will need to change the input_shape parameter because it is entered only when we add our very first layer to automatically connect that first layer to the input layer, which automatically adds the input layer. Since we are already here adding the second convolution layer, so we can simply remove that parameter. So, we are all set to move on to step3. Step3: Flattening In the third step, we will undergo flattening the result of these convolutions and pooling into a one-dimensional vector, which will become the input of a fully connected layer neural network in a similar way as we did in the previous section. We will start with again taking our cnn object from which we will call the add method because the way we are going to create that flattening layer is once again by creating an instance of the Flatten class, such that Keras will automatically understand that this is the result of all these convolutions and pooling, which will be flattened into the one-dimensional vector. So, we just need to specify that we want to apply flattening and to do this we will have to call once again the layers module by the Keras library by TensorFlow from which we are actually going to call the flatten class, and we don't need to pass any kind of parameter inside it. Step4: Full Conversion In step 4, we are exactly in the same situation as before building a fully connected neural network. So, we will be adding a new fully-connected layer to that flatten layer, which is nothing but a one-dimensional vector that will become the input of a fully connected neural network. And for this, we will again start by taking a cnn neural network from which we are going to call the add method because now we are about to add a new layer, which is a fully connected layer that belongs to tf.keras.layers. But this time, we will take a Dense class followed by passing units, which is the number of hidden neurons we want to have into this fully connected layer and activation function parameter. Step5: Output Layer Here we need to add the final output layer, which will be fully connected to the previous hidden layer. Therefore, we will call the Dense class once again in the same way as we did in the previous step but will change the value of the input parameters because the numbers of units in the output layer are definitely not 128. Since we are doing binary classification, it will actually be one neuron to encode that binary class into a 'cat' or 'dog'. And for the activation layer, it is recommended to have a sigmoid activation function. Otherwise, if we were doing multiclass classification, we would have used the SoftMax activation function. Part3: Training the CNNIn the previous steps, we built the brain the, which contained in the eyes of the Artificial Intelligence and now we are going to make that brain smart with the training of CNN on all our training set images, and at the same time, we will evaluate our same model on the test set over the epochs. Now we are going to train our CNN over 25 epochs, and at each epoch, we will actually see how our model is performing on our test set images. This is a different kind of training as we did before because we always used to separate the training and evaluation, but here this will happen at the same time as we are making some specific application, i.e., computer vision. Compiling the CNN Now we are going to compile the CNN, which means that we are going to connect it to an optimizer, a loss function, and some metrics. As we are doing once again a binary classification, so we are going to compile our CNN exactly the same way as we complied our ANN model because indeed, we are going to choose once again adam optimizer to perform stochastic gradient descent to update the weights in order to reduce the loss error between the predictions and target. Then we will choose the same loss, i.e., the binary_crossentrophy loss because we are doing exactly the same task binary classification. And then same for the metrics, we will choose accuracy metrics because it is the most relevant way to measure the performance of the classification model, which is exactly our case of CNN. So, we will take our cnn from which we will be calling the compile method that will take as input the optimizer, loss function, and the metrics. Training the CNN on the Training set and evaluation on the Test set After the compilation, we will train the CNN on the training set followed by evaluating at the same time on the test set, which will not be exactly the same as before but will be somewhat similar. Basically, the first two steps are always the same, i.e., in the first step, we will take cnn followed by taking the fit method in the second step that will train the cnn on the training set. Inside it, we will pass the following parameters:
Output 
From the image given above, it can be seen that we ended with 90% of final accuracy on the training set and final accuracy of 80.50%on the test set. Let's remind it again that if we had not done image augmentation preprocessing in part1, we would have ended up with an accuracy of around 98% or even 99% on the training set, which clearly indicates overfitting and lower accuracy here on the test set around 70%. This is the reason why we insisted image augmentation is absolutely fundamental. Part4: Making a single predictionIn part4, we will make a single prediction, which actually consists of deploying our model on the two separate images of this single prediction folder for which our model will have to recognize for both the dog and cat, respectively. So, basically, we will deploy our CNN model on each of these single images, and we will hope that our CNN successfully predicts a dog as well as a cat. And for this, we will start with importing NumPy. Next, we will import a new module that we actually imported earlier, i.e., we imported the ImageDataGenerator from the image submodule of the preprocessing module of the Keras library. And in fact, what we are going to import now is that image module. But because we specifically imported something specific from that module, well, we need to import it again. So, we will start with Keras, which we will help us to get access to the preprocessing module from which we will further import that image module. The next is, of course, to load that single image on which we want to deploy our model to predict if there is a cat or dog inside. We will create a new variable, i.e., the test_set that will be initialized with loading the image on which we want to test out model from the same single prediction folder. It can be done by first calling the image submodule from which we will call the load_img function, and inside this function, we will simply pass two arguments, i.e., the first parameter is the path specifying that particular image we want to select which will actually lead us to the test_set image variable and the second one plays a vital role as it relates to the image which will become the input of the predict method has to have the same size as the one that was used during the training. Since we actually resized our images into the size target of (64, 64), whether it was for the training set or test set and we also specify it again while building the CNN with the same input shape, so the size of the image we are going to work with either for training the CNN or calling the predict method has to be (64, 64). So, in order to specify it here, we will enter our second parameter, which is the target_size. But to make our first test _set image accepted by the predict method, we need to convert the format of an image into an array because the predict method expects its input to be a 2D array. And we will do this with the help of another function of the image preprocessing module, i.e., img_to_array function, which indeed converts PIL image instance into a NumPy array that is exactly the format of array expected by the predict method. We will again use our image submodule from which we will call img_to_array(), and inside, it will take the test_size image in PIL format that we are looking forward to convert it into the NumPy array format. Since the predict method has to be called on the exact same format that was used during the training, so if we go back into the preprocessing phase of both training set as well as the test set, we created batches of images. Therefore, our CNN was not trained in any single image; rather, it was trained on the batches of images. So, as we have an extra dimension of batch and we are about to deploy our model on a single image, then that single image still has to be into the batch even if we are going to have one image in the batch, it has to be into this batch so that the predict method of our CNN model can recognize the batch as that extra dimension. Next, we will add an extra dimension, which will correspond to the batch that will contain that image into the batch, and it can be simply done by updating our test image by adding extra dimensions corresponding to batch. And the way to do it is with NumPy as the NumPy arrays can be easily manipulated, so we will first call the NumPy from which we will call this function that allows exactly to add a fake dimension, or we can say a dimension corresponding to the batch, which is called expand_dims function inside of which we will input the image to which we want to add this extra dimension corresponding to the batch followed by adding an extra argument, i.e., where we want to add that extra dimension such that the dimension of the batch is always the first dimension to which we always give our first batch of images, and then inside of each batch we get the different images. So, it seems natural to have the batch as the first dimension and to specify this is exactly what we need to enter as a second argument, which is an axis that we have to set equal to zero. That is why the dimension of a batch that we want to add to our image will be the first dimension. After this, we can call the predict method because, indeed, that test set image, which is not only in the right NumPy array but also which has the extra dimension corresponding to the batch, has exactly the right format expected by the predict method. Therefore, we can create a new variable which will call result as it will actually predict our CNN model with the test image. Here we are not calling it prediction because it will only return or zero or one, which is why we are required to encode so as to represent 0 relates to cat and 1 is a dog. So, we will call our first result variable, which will actually be the output of the predict method called from our CNN. Inside the predict method, we will pass the test_image, which now has the right format expected by that predict method. To figure out in between what relates to 0 and what narrates about 1, we will call either the training_set or test_set and then from which we will further call class_indices, such that by printing this, we will get the right class_indices. And with this, we indeed get that dog corresponds to 1 and cat relates to 0. In the end, when the two single predictions are made on these two single images, we will finish it with the if condition. Since we already know that result contains the outcome in batches because it was called on a test image that was into a batch, so results also have a batch dimension, and we are going to get access to the batch. After this, inside the batch, we are going to get access to the first element of the batch that corresponds to the prediction of that same cat_or_dog_1 image. As we are dealing with a single image, so a single prediction is needed, and to get that, we will need to get inside the batch of index zero, the first and only prediction once again, which has a [0] index. So, that is how we get our prediction by first accessing the batch followed by accessing the single element of the batch, and if that prediction equals to one, then we already know that it corresponds to the dog, then we will create a new variable which we will call as prediction and will set that prediction variable equals to the dog. Likewise, in the else condition, if the result prediction equals to 1, then the prediction will be a cat. Now we will wrap it up by simply printing the prediction. Output 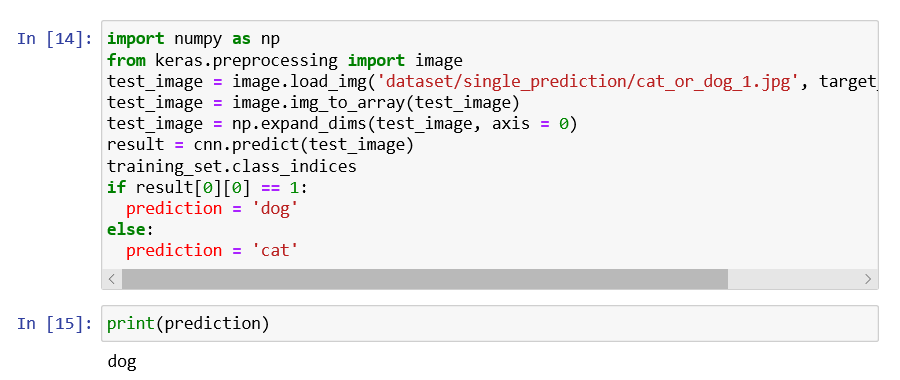
We can see our Convolution Neural Network predicted that there is a dog inside the image. So, it can be concluded that our first test is passed successfully. Now we will check for the other image which is of the cat, so for that we will need to deploy our model on this single image and check that indeed, our CNN returns a cat. To do this, we need to change the name here, i.e. cat_or_dog_2.jpg and then play this cell again by clicking on the Run button. Output 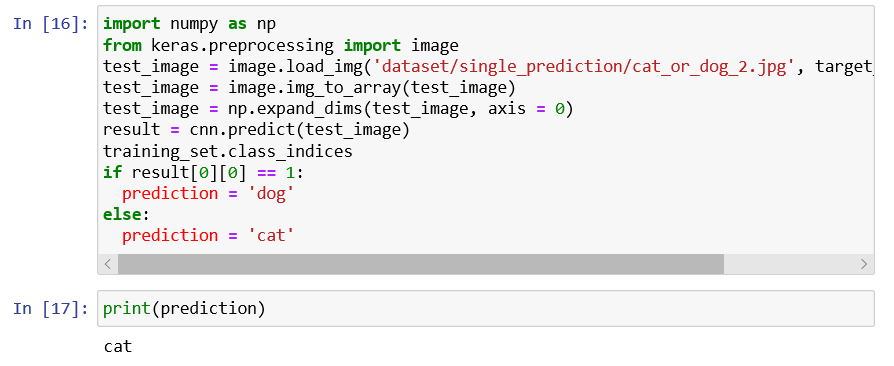
So, it's clear now that our CNN model is successful in predicting cat in the output of the console. Hence our CNN got all the answers correct.
Next TopicRecurrent Neural Networks
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








