| |

LR ParserLR parsing is one type of bottom up parsing. It is used to parse the large class of grammars. In the LR parsing, "L" stands for left-to-right scanning of the input. "R" stands for constructing a right most derivation in reverse. "K" is the number of input symbols of the look ahead used to make number of parsing decision. LR parsing is divided into four parts: LR (0) parsing, SLR parsing, CLR parsing and LALR parsing. 
LR algorithm:The LR algorithm requires stack, input, output and parsing table. In all type of LR parsing, input, output and stack are same but parsing table is different. 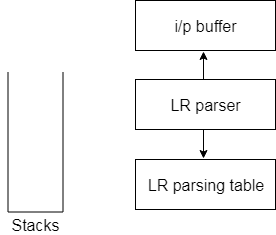
Fig: Block diagram of LR parser Input buffer is used to indicate end of input and it contains the string to be parsed followed by a $ Symbol. A stack is used to contain a sequence of grammar symbols with a $ at the bottom of the stack. Parsing table is a two dimensional array. It contains two parts: Action part and Go To part. LR (1) ParsingVarious steps involved in the LR (1) Parsing:
Augment GrammarAugmented grammar G` will be generated if we add one more production in the given grammar G. It helps the parser to identify when to stop the parsing and announce the acceptance of the input. ExampleGiven grammar The Augment grammar G` is represented by
Next TopicCanonical Collection of LR(0) items
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








