| |

Random Forest AlgorithmRandom Forest is a popular machine learning algorithm that belongs to the supervised learning technique. It can be used for both Classification and Regression problems in ML. It is based on the concept of ensemble learning, which is a process of combining multiple classifiers to solve a complex problem and to improve the performance of the model. As the name suggests, "Random Forest is a classifier that contains a number of decision trees on various subsets of the given dataset and takes the average to improve the predictive accuracy of that dataset." Instead of relying on one decision tree, the random forest takes the prediction from each tree and based on the majority votes of predictions, and it predicts the final output. The greater number of trees in the forest leads to higher accuracy and prevents the problem of overfitting. The below diagram explains the working of the Random Forest algorithm: 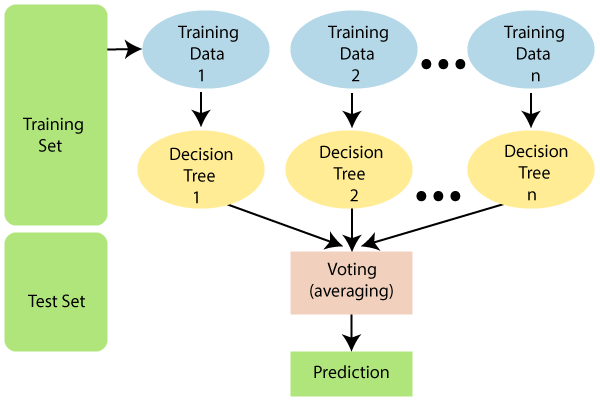
Note: To better understand the Random Forest Algorithm, you should have knowledge of the Decision Tree Algorithm.Assumptions for Random ForestSince the random forest combines multiple trees to predict the class of the dataset, it is possible that some decision trees may predict the correct output, while others may not. But together, all the trees predict the correct output. Therefore, below are two assumptions for a better Random forest classifier:
Why use Random Forest?Below are some points that explain why we should use the Random Forest algorithm:
How does Random Forest algorithm work?Random Forest works in two-phase first is to create the random forest by combining N decision tree, and second is to make predictions for each tree created in the first phase. The Working process can be explained in the below steps and diagram: Step-1: Select random K data points from the training set. Step-2: Build the decision trees associated with the selected data points (Subsets). Step-3: Choose the number N for decision trees that you want to build. Step-4: Repeat Step 1 & 2. Step-5: For new data points, find the predictions of each decision tree, and assign the new data points to the category that wins the majority votes. The working of the algorithm can be better understood by the below example: Example: Suppose there is a dataset that contains multiple fruit images. So, this dataset is given to the Random forest classifier. The dataset is divided into subsets and given to each decision tree. During the training phase, each decision tree produces a prediction result, and when a new data point occurs, then based on the majority of results, the Random Forest classifier predicts the final decision. Consider the below image: 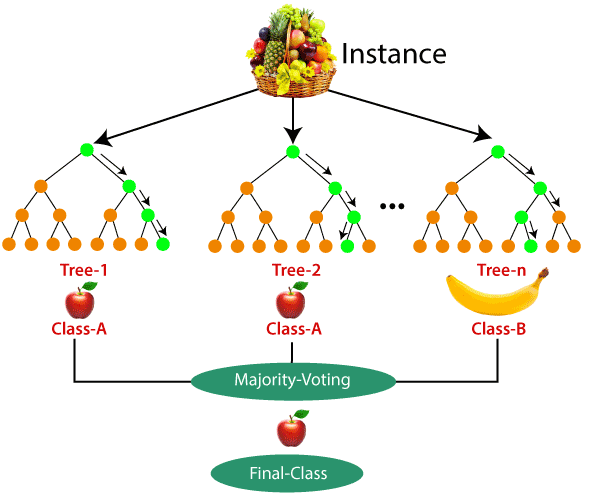
Applications of Random ForestThere are mainly four sectors where Random forest mostly used:
Advantages of Random Forest
Disadvantages of Random Forest
Python Implementation of Random Forest AlgorithmNow we will implement the Random Forest Algorithm tree using Python. For this, we will use the same dataset "user_data.csv", which we have used in previous classification models. By using the same dataset, we can compare the Random Forest classifier with other classification models such as Decision tree Classifier, KNN, SVM, Logistic Regression, etc. Implementation Steps are given below:
1.Data Pre-Processing Step:Below is the code for the pre-processing step: In the above code, we have pre-processed the data. Where we have loaded the dataset, which is given as: 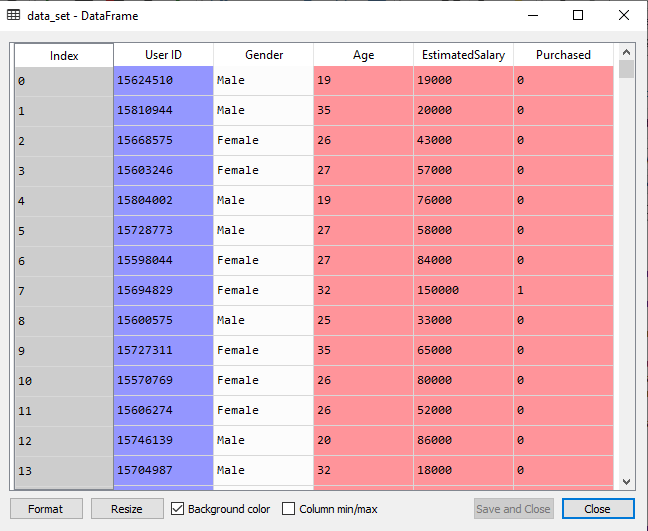
2. Fitting the Random Forest algorithm to the training set:Now we will fit the Random forest algorithm to the training set. To fit it, we will import the RandomForestClassifier class from the sklearn.ensemble library. The code is given below: In the above code, the classifier object takes below parameters:
Output:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='entropy',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
3. Predicting the Test Set resultSince our model is fitted to the training set, so now we can predict the test result. For prediction, we will create a new prediction vector y_pred. Below is the code for it: Output: The prediction vector is given as: 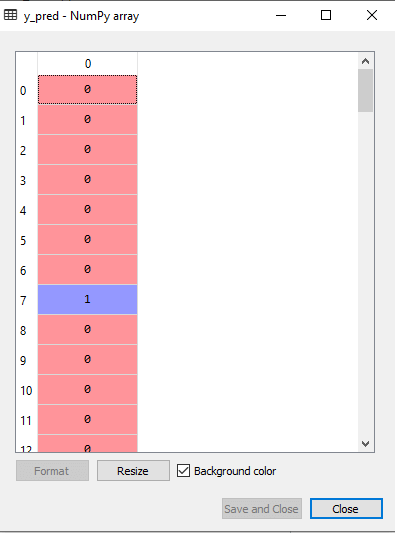
By checking the above prediction vector and test set real vector, we can determine the incorrect predictions done by the classifier. 4. Creating the Confusion MatrixNow we will create the confusion matrix to determine the correct and incorrect predictions. Below is the code for it: Output: 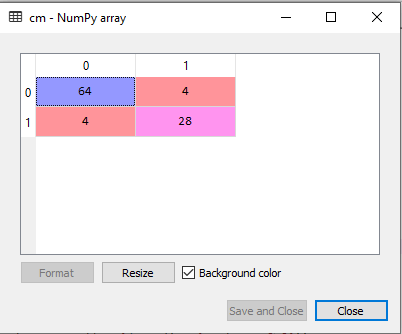
As we can see in the above matrix, there are 4+4= 8 incorrect predictions and 64+28= 92 correct predictions. 5. Visualizing the training Set resultHere we will visualize the training set result. To visualize the training set result we will plot a graph for the Random forest classifier. The classifier will predict yes or No for the users who have either Purchased or Not purchased the SUV car as we did in Logistic Regression. Below is the code for it: Output: 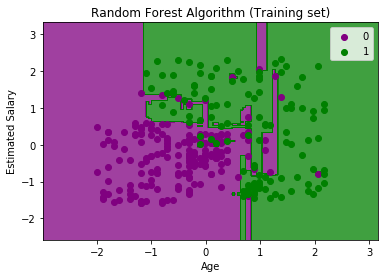
The above image is the visualization result for the Random Forest classifier working with the training set result. It is very much similar to the Decision tree classifier. Each data point corresponds to each user of the user_data, and the purple and green regions are the prediction regions. The purple region is classified for the users who did not purchase the SUV car, and the green region is for the users who purchased the SUV. So, in the Random Forest classifier, we have taken 10 trees that have predicted Yes or NO for the Purchased variable. The classifier took the majority of the predictions and provided the result. 6. Visualizing the test set resultNow we will visualize the test set result. Below is the code for it: Output: 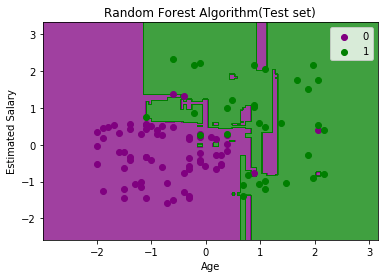
The above image is the visualization result for the test set. We can check that there is a minimum number of incorrect predictions (8) without the Overfitting issue. We will get different results by changing the number of trees in the classifier.
Next TopicMachine Learning Interview Questions
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








