| |

NLP Analysis of Restaurant ReviewsThe field of natural Language Processing (NLP) is a branch of computer science, as well as artificial intelligence, that focuses on the interaction between computer systems and human (natural) languages and, specifically, the way computers, are programmed to process and analyse vast quantities of data from natural languages It is a branch of machine learning that involves analysing any text and implementing a predictive analysis. Scikit-learn is an open-source machine learning library compatible with using the Python programming language. Scikit-learn is mainly written in Python and has some basic methods written using Cython to provide performance. Cython is a subset of Python programming language designed to emulate C's performance by using the majority of code written in Python. Let's explore the various processes involved in text processing and the process of NLP. This algorithm could analyse any text, such as classifying books into Romance and Friction. In the meantime, let's make use of existing reviews of restaurant datasets to analyse positive and negative feedback. Steps Involved:Following is the stepwise explanation of how to analyse the restaurant reviews using NLP: Step 1: Import data with delimiter setting by 't' in columns. They are separated by tab space. Reviews and the category (0 and 1) do not have any symbol to separate them. However, they are separated using tab space, as the majority of all other symbols in the review (like $ for value, ...! etc.) The algorithm could utilize them as a delimiter, resulting in weird behaviour (like odd output, errors) in the output. Code: Step 2: Text Cleaning or Pre-processing
Code: Step 3: Tokenization This involves splitting words and sentences from the text's body. Step 4: The bag of words using a sparse matrix
For this purpose we need CountVectorizer class from sklearn.feature_extraction.text. It is also possible to set a number of features that are allowed (max none. features that aid the most) by setting attributes "max_features"). Do the training on the corpus and then apply the same transformation to the corpus ".fit_transform(corpus)" and then convert it into an array. If the review is negative or positive, that is indicated within column 2 of the data [ 1All rows and the 1st column (indexing from zero). Code: The description for the data to be employed:

Step 5: Separating Corpus in the Test and Training set. For this, we need class train_test_split from sklearn.cross_validation. Split can be constructed 70/30, 70/30, 80/20 or 85/15, or 75/25. In this case, I've chosen 75/25 through "test_size." The words bag and y can be 0 and 1. (positive or negative). Code: Step 6: Use a predictive model (here, we will use RandomForest Classifier)
Code: Step 7: Predicting End Results using the .predict() technique using the attribute X_test. Code: Output: 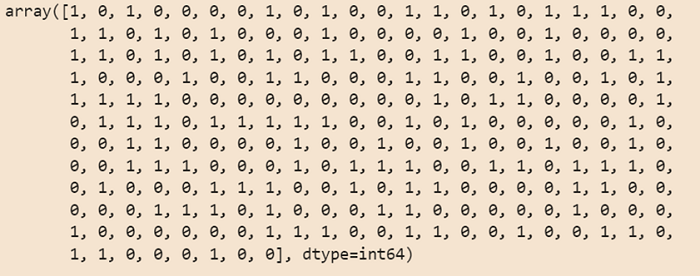
NOTE: Accuracy with the random forest was 72 percent. (It could be different if we experimented using diverse test sizes; in this case, it is 0.25).Step 8: For being aware of the exactness of the accuracy result, we do need to get the confusion matrix. The Confusion Matrix is a 2X2 Matrix. TRUE POSITIVE: It is the measure of the percentage of positives in the real world that have been appropriately recognized. TRUE NEGATIVE: It determines the percentage of real positives not accurately determined. FALSE POSITIVE: It is the measure of the proportion of actual negatives adequately recognized. FALSE NEGATIVE: It determines the percentage of negatives that aren't correctly recognized in real life. Code: Output:
array([[105, 25],
[ 41, 79]], dtype=int64)
Next TopicWhat are LSTM Networks
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








