| |

Pandas Sorting MethodsPandas sort methods are the most primary way for learn and practice the basics of Data analysis by using Python. Data analysis is commonly done with Pandas, SQL, and spreadsheets. Pandas can handle a large amount of data and can offer the capabilities of highly performant data manipulations. In this tutorial, we will explain how to use .sort_values() and .sort_index(), which enables the users to sort the data efficiently in the DataFrame. IntroductionThe DataFrame is the data structure with the labelled axes for both rows and columns. The user can sort the DataFrame by the row or column values and also by the row or column index. The rows and columns both have numerical representations of where the data is in the user's Data Frame, known as indices. So that user can retrieve the data from the specific rows or columns with the help of the index location of DataFrame. The index number starts from zero by default, but the user can assign their index manually. Preparing the DatasetIn this tutorial, we will be working with the dataset of fuel economy compiles by the US Environmental Protection Agency (EPA) on the vehicles made between 1984 and 2021. The dataset of the Environmental Protection Agency is perfect for understanding the sorting as it has many different types of information from numeric to textual data types based on which user can perform the sorting. This Dataset contains eighty-three columns in total. Before starting the analyzing and sorting the dataset, the user needs to install the Pandas library. The version of pandas library should be 1.2.0 and the version of Python should be above 3.7.1. For analyzing purpose, the user will be looking at miles per gallon (MPG) data on the vehicles by model, year, make and other attributes. User will be able to specify which columns to include in their DataFrame. For this article, we will need only the subset of the accessible columns. In the following example we have passed the commands for reading the significant columns of the fuel economy dataset into the DataFrame and it will also display the first five rows of new DataFrame. For example: Output: 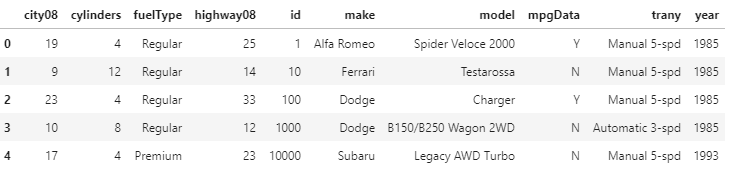
The users can load the dataset into the DataFrame by calling the .read_csv() function with the dataset URL. We have narrowed the column result for the faster output with low memory use. To further limit memory consumption and get a quick preview of the data, users can also specify the number of rows they want to load by using the 'nrows' command. The sort_values() functionThe user can sort values in the DataFrame along with both the axis (rows or columns) by using the sort_values() function. If they want to sort the rows in the DataFrame in reference to the values of the one or more columns: 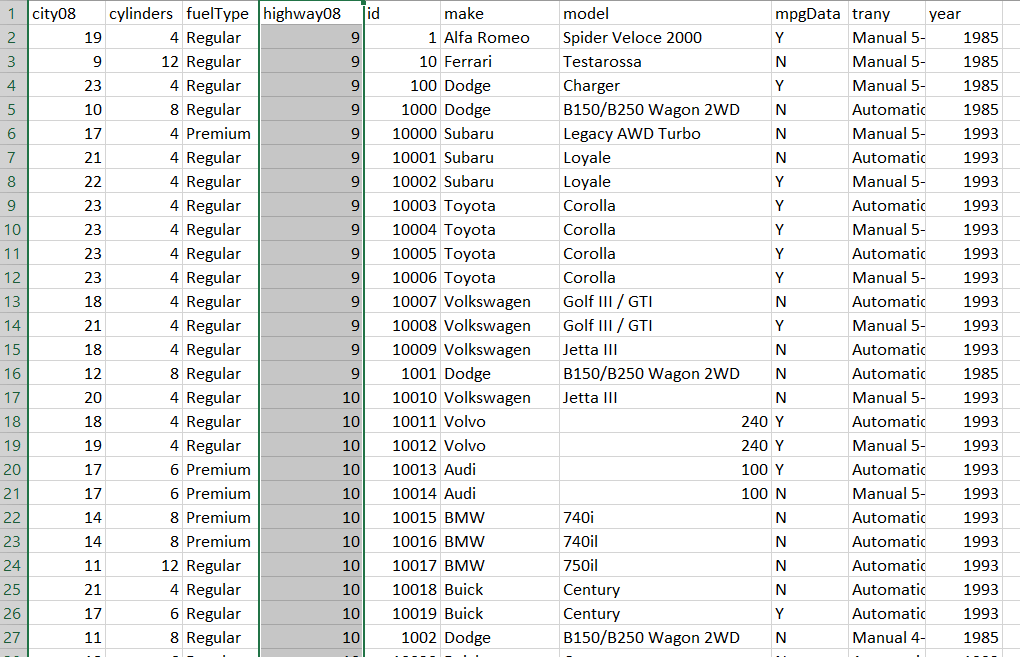
The image above is the sorted result of rows of DataFrame based on the values of the highway08 column by using the sort_values() function. This is an example of how we would be sorting the data in the spreadsheet by using the column. The sort_index() functionThe users can also sort the DataFrame by its row index or columns labels by using sort_index() function. The difference between sort_values() and sort_index() is that sort_values() sort the DataFrame based on its values in rows or columns but in .sort_index() we sort the DataFrame based on its index or columns labels: 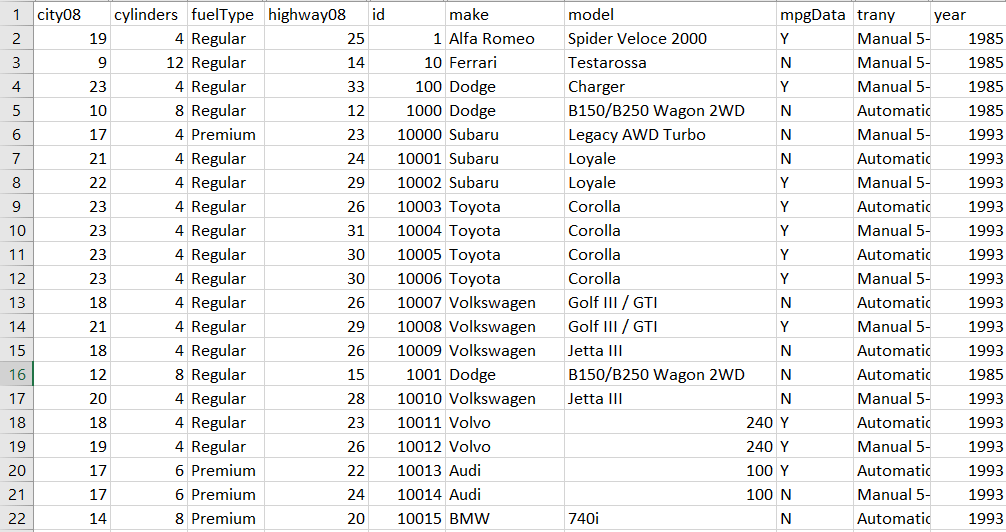
An index of the DataFrame is not considered a column, and there is probably only a single raw index. The row index of the DataFrame can be regarded as the row numbers, which most probably start from zero. Sorting the DataFrame by a Single ColumnFor sorting the DataFrame on the basis of a single column's values, we will use sort_values(). It will return the new DataFrame by default, which is sorted in ascending order. But it does not change the primary DataFrame. Sorting a Column in the Ascending OrderFor using .sort_values(), we will pass a single argument to the method which contains the name of the column that we want to sort by. In the next example, we will be sorting the DataFrame by the city08 column. This represents city Miles per Gallon for only fuel cars. For example: Output: 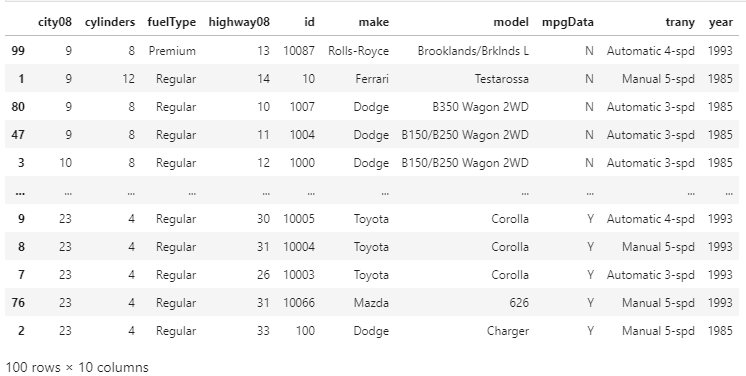
By default, this sorts out DataFrame by using the values of the column labeled as 'city08' in the ascending order. However, we did not specified the name for the argument that we passed to .sort_values(), we actually used the by-parameter, which we will explain in the next example. Changing the Sort OrderBy default, sort_values() sorts the DataFrame in the ascending order, but if we want to sort the DataFrame in the descending order, we can pass the False value to the parameter. For example: Output: 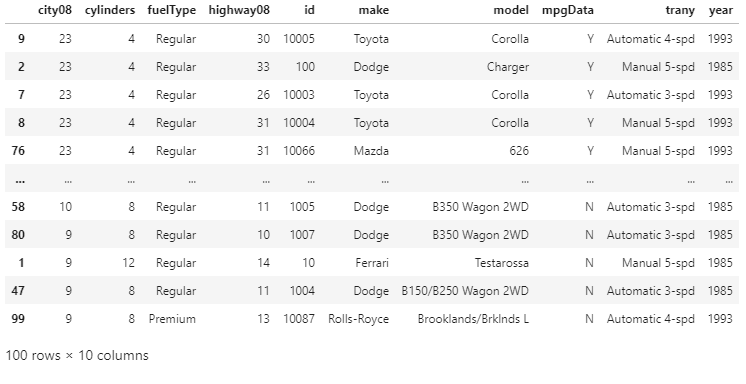
We have reversed the sorting order bypassing the False value to ascending. Now we have sorted our DataFrame in descending order by the average Miles Per Gallon measured in the city conditions. In the above output, the vehicles in our DataFrame are sorted with the highest MPG values are in the first rows. Choosing the Sorting AlgorithmPandas allows the user to choose between various sorting algorithms for using it with both .sort_values() and .sort_index(). The sorting algorithms are given below:
By default, the quicksort algorithm is used for sorting on a single column. For changing this to the stable sorting algorithm, we can use the mergesort algorithm. We can do this by using the kind parameter in sort_values() or sort_index(). We can also use heapsort algorithm for soring the data, but heapsort is only recommended for worst cases, as it is slowest sorting algorithm and is not stable. For example: Output: 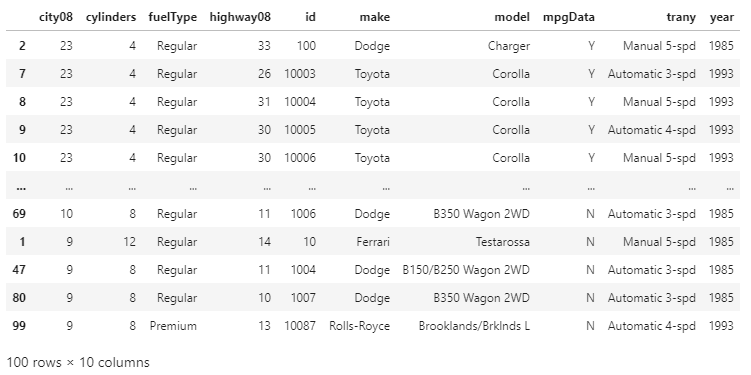
By using the kind parameter, we have set the mergesort algorithm as the sorting algorithm. The previous output used the quicksort algorithm by default. We can notice that the output of both the algorithm are different because the quicksort algorithm is not a stable sorting algorithm. Always remember that in pandas, we ignore the kind parameter when we sort on more than one column label. When we sort multiple records, which have the same key, the stable sorting algorithm can maintain the original order of these records after sorting. The cause of which it is necessary for us to use a stable sorting algorithm is we are performing multiple sorts. Sorting the DataFrame on Multiple ColumnsDuring the Data analysis, we sometimes want to sort the data based on the values of multiple columns. Suppose we have a dataset with the first and last names of the people. And we want to sort it by the first name and then the last name of the people. So that the people have the same first name which can be arranged alphabetically according to their last names. In the following example, we will sort the DataFrame on a single column named city08. The MPG in city conditions is an essential factor that can determine the desirability of the cars. And suppose we also want to look at the Miles per Gallon for the highway condition in addition to the MPG in city condition. For sorting the DataFrame by two keys, we can pass a list of column labels by parameter. For example: Output: 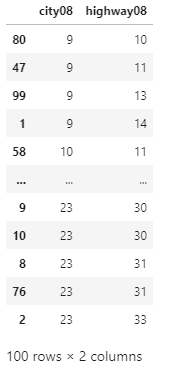
Here, by specifying a list of the column labels city08 and highway08, we have sorted the two columns by using sort_values(). In the next example, we will explain how we can specify the sort order and why it is important for the users to pay attention to the list of the column labels they use. Sorting by Multiple Columns in Ascending OrderFor sorting the DataFrame on multiple columns, we must have to provide a list of the column labels. Suppose, for sorting the DataFrame by make and model. We should create the following list and then pass them to the sort_values(). For example: Output: 
Now, our DataFrame is sorted in ascending order by make column. If there are two or more same makes, then the DataFrame will be sorted by the model column. The DataFrame will be sorted according to the order of the column labels we have specified in our list. Changing the Columns Sort OrderAs we are sorting the DataFrame by using multiple columns, we can also specify the order by which we want our columns to get sorted. If we want to change the sorting order of our DataFrame from the last example, then we can change the order of the column labels in the list that we have passed to the by parameter. For example: Output: 
Here, now our DataFrame is sorted in ascending order by the model columns, if there are two or more identical model, then the DataFrame will be sorted by the make column. We can notice that when we change the order of the columns, then the order in which the values are sorted will also change. Sorting by Multiple Columns in Descending OrderTill now, we have sorted the multiple columns in ascending order. In the following example, we will sort the multiple columns in descending order. For sorting the DataFrame in descending order, we will set the ascending value to False. For example: Output: 
Here, we can notice that in the DataFrame the make column is sorted in the reverse alphabetical order, and the model column's values are sorted in the descending order for any cars with the same make. With the textual data, the sorting is a sensitive case, which means that the capitalized text will appear first in the ascending order and last in the descending order. Sorting by Multiple Columns with Different Sort OrdersWith Pandas in Python, we can sort by using multiple columns and having those columns by using different ascending arguments and that too in just a single function call. If the user wants to sort the columns in ascending order and some columns in descending order, then they have to pass the list of Booleans to ascending. In the following example, we will sort our DataFrame by make, model, and city08 columns, and the first two columns should be sorted in ascending order, and the city08 column should be sorted in descending order. For doing so, we will pass the list of column labels by parameter and the list of Booleans to ascending. For example: sOutput: 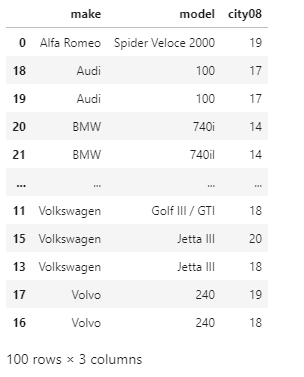
Here, now our DataFrame is sorted by make and model columns in ascending order, and the city08 column is sorted in ascending order. This is helpful as by this the group of cars in the categorical order, and this shows the highest Miles per Gallon cars first. Sorting the DataFrame on Its IndexBefore starting with how to sort on the index, let's understand what an index represents. The DataFrame has an .index property, which is a numerical representation of the location of rows by default. The index is like the row numbers. The index helps in quick row lookup and identification. Sorting by Index in Ascending OrderWe can sort the DataFrame on the basis of its rows index by using the sort_index() function. Sorting by column values like we did in the previous examples reorders the rows in our DataFrame, so the index becomes disorganized. It can also happen when the user filters the DataFrame or when they add or drop the rows. For illustrating the use of .sort_index(), let's start by creating a new sorted DataFrame by using .sort_values() function. Example: Output: 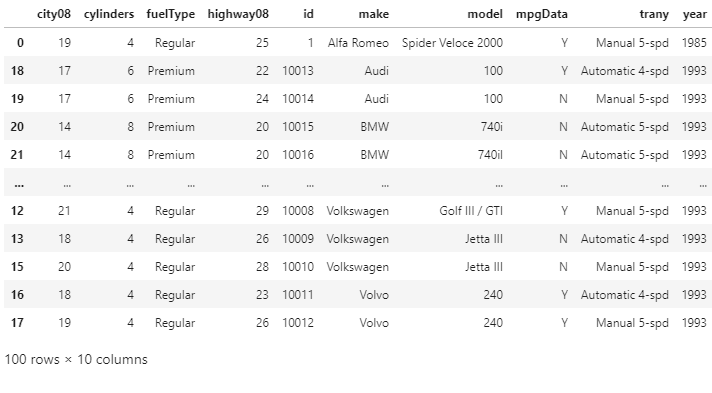
Here, we have created the DataFrame, which is sorted by using multiple values. We can also notice that how the row of the index is not in any particular order. For getting our new DataFrame back to the original order, we can use the sort_index() function. Example: Output: 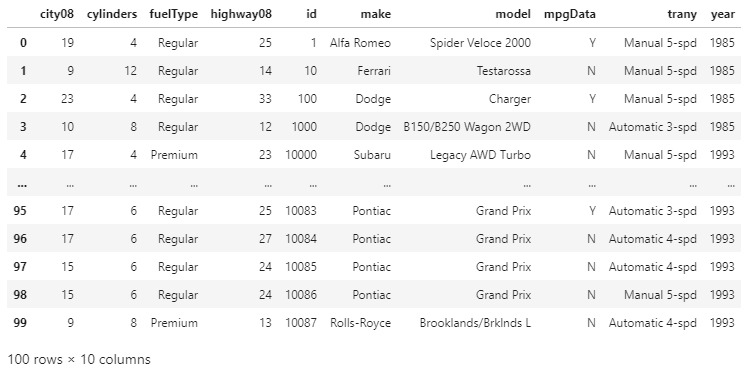
Now, the index of our DataFrame is in ascending order. In sort_index() the default argument for the ascending order is True just like in sort_values(). We can change it to the descending order bypassing the false value. Sorting on the index will not have any impact on the data as the values are unchanged. It is useful for the users who want to assign the custom index by using sort_index(). Suppose we want to set the custom index with the make and model columns, then we have to pass a list to set_index(). Example: Output: 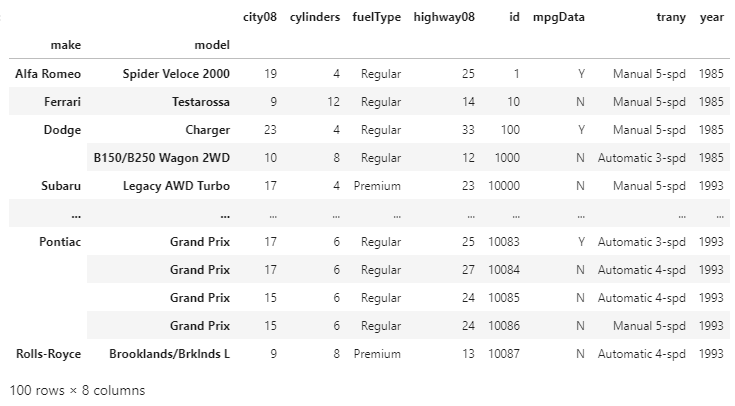
By using this method, we can replace the default integer-based row index with the two axis labels. This is considered as a hierarchical Index or a MultipleIndex. The DataFrame is now indexed by more than one key, which can be sorted by using .sort_index(). Example: Output: 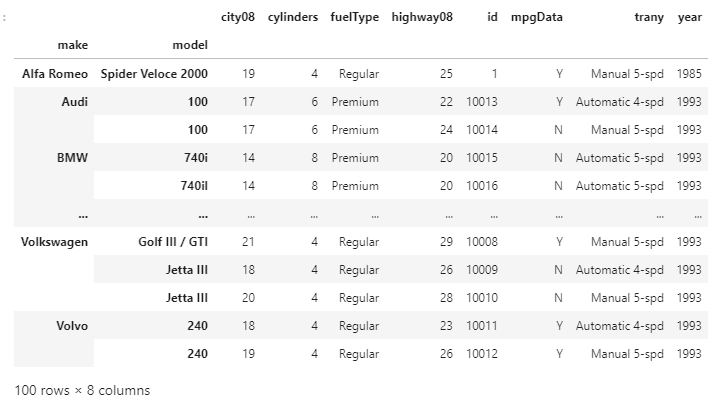
First, we have assigned a new index to our DataFrame by using the make and model columns, then we have sorted the index by using the .sort_index() function. Sorting by Index in Descending OrderNow, we will sort our DataFrame by its index in descending order. For getting the output in descending order, we have to set the value of the ascending to the False, same as we did in the .sort_values(). Example: Output: 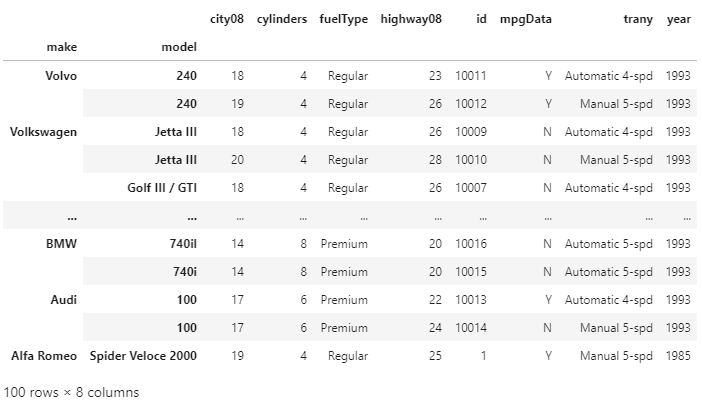
Now, our DataFrame is sorted by its index in descending order. There is one difference between the .sort_index() and .sort_values() and that is the sort_index() has no parameter as it sorts the DataFrame on the row index by default. Exploring Advanced Index-Sorting ConceptsThere are many situations that occur while analyzing the data when the user wants to sort on the hierarchical index. We have already seen how we can use make and model columns in the MultiIndex. For this dataset, we can also use the id column as an index. Let's set the id column as the index, and it would be helpful for linking the related datasets. For example, the emission Dataset of EPA also uses the id for representing vehicle records IDs. It will link the emission dataset to the fuel economy dataset. Now, by sorting the index of both datasets in DataFrames can speed up the use of other functions like merge(), join() and concat(). Sorting the Columns of the DataFrameWe can also use the column labels of the DataFrame for sorting the row values. With the optional parameter axis set to 1 in sort_index(), we can sort the DataFrame by the column label. Instead of the actual data, the sorting algorithm is applied to the axis labels. It will be helpful for the visual review of the DataFrame. How to work with the DataFrame axisWhen the user uses the .sort_index() without passing any explicit argument. By default, it uses the axis = 0 argument. The axis of the DataFrame refers to both the index (axis = 0) and the columns (axis = 1). The user can use both the axis for selecting and indexing the data in the DataFrame and also for sorting the data. Using Column Labels for sortingWe can also use the column labels as the sorting key of the DataFrame for the sort_index function. Let's set the axis to 1 for sorting the columns of our DataFrame on the basis of the column names. Example: Output: 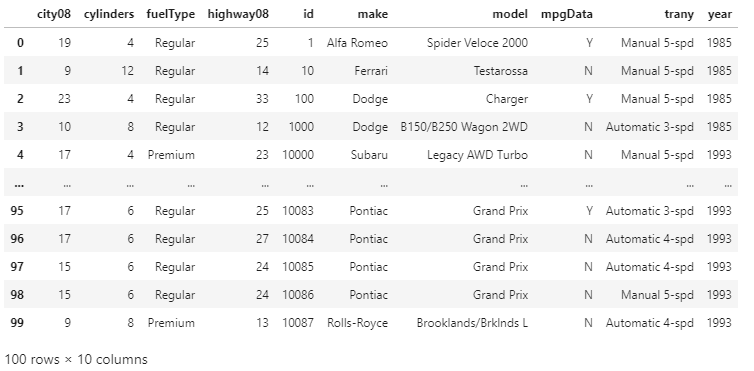
The columns of the DataFrame are sorted from left to right in ascending alphabetical order. Now, suppose we want to sort the columns in descending order, then we just have to set the ascending value equals to False. Example: Output: 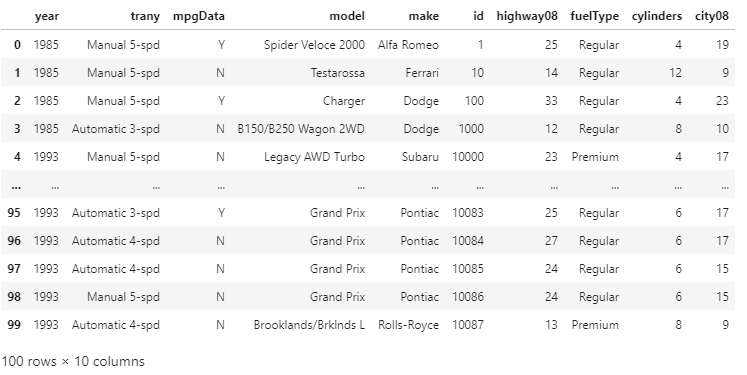
By using axis = 1 in the .sort_index() function, we have sorted the columns of our DataFrame in both ascending and descending order. This can be more useful in other datasets, which have the column labels corresponding to the months of the year. In that scenario, arranging our data in ascending or descending order by months will make sense. Conclusion:In this article we have discussed how to use sort_values() and sort_index() for sorting the data efficiently in the DataFrame. How to sort the pandas DataFrame by the values of one or more columns and use the ascending parameter for changing the sort order and how we can sort the DataFrame by its index by using the .sort_index() function.
Next TopicDrop Columns in pandas
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








