| |

PDFBox Reading TextOne of the main features of PDFBox library is its ability to quickly and accurately extract text from an existing PDF document. In this section, we will learn how to read text from an existing document in the PDFBox library by using a Java Program. The PDF document may contain text, animation, and images etc as its text contents. We can extract text from the existing PDF document by using getText() method of the PDFTextStripper class. Follow the steps below to read text from the existing PDF document- Load PDF DocumentWe can load the existing PDF document by using the static load() method. This method accepts a file object as a parameter. We can also invoke it using the class name PDDocument of the PDFBox. Instantiate PDFTextStripper classPDFTextStripper class is used to retrieve text from a PDF document. We can instantiate this class as following- Retrieve TextgetText() method is used to read the text contents from the PDF document. In this method, we need to pass the document object as a parameter. This method returns the text as a string object. Close DocumentAfter completing the task, we need to close the PDDocument class object by using the close() method. Example-This is a PDF document,in which we are going to extract its text content by using PDFBox library of a Java program. 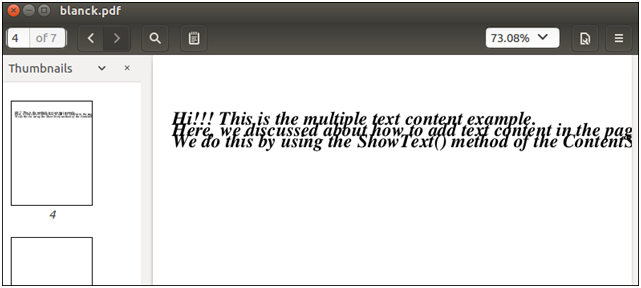
Java Program-Output: After successful execution, the above program retrieves the text from the PDF document as shown in the following output. 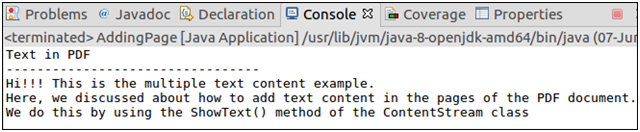
Next TopicPDFBox Extracting Phone Numbers
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








