| |

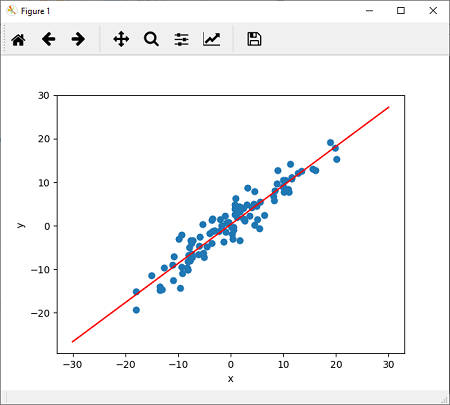
Training of Linear ModelWe plotted our linear model given the random parameters that were assigned to it. We found that it does not fit our data well. What we have to do. We need to train this model so that the model has the optimal weight and bias parameters and fit this data. There are the following steps to train a model: Step 1 Our first step is to specify the loss function, which we intend to minimize. PyTorch provides a very efficient way to specify the lost function. PyTorch provides MSELoss() function, known as mean squared loss, to calculate loss as Step 2 Now, our next step is to update our parameters. For this purpose, we specify the optimizer that uses the gradient descent algorithm. We use SGD() function known as stochastic gradient descent for optimization. SGD minimizes the total loss one sample at a time and typically reaches convergence much faster as it will frequently update the weight of our model within the same sample size. Here, lr stands for learning rate, which is initially set to 0.01. Step 3 We will train our model for a specified number of epochs (We calculated the error function and backpropagated the gradient descent of this error function to update the weight). And now, for every epoch, we have to minimize the error of our model system. The error is simply a comparison between the prediction made by the model and the actual values. Step 4 Now, at last, we plot our new linear model by simply calling plotfit () method. Complete CodeProgram Output: 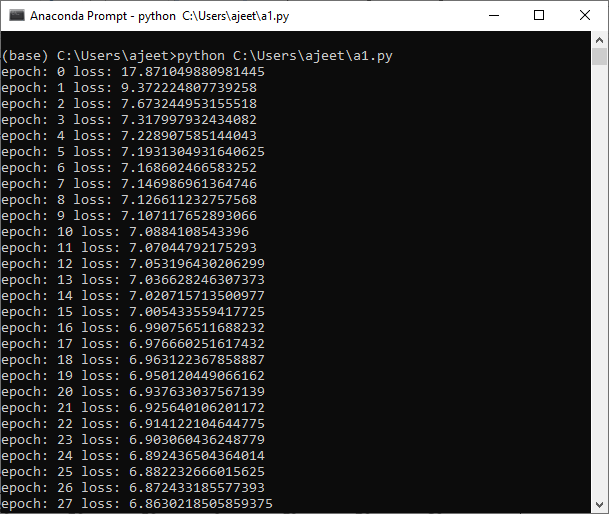
Next TopicPerceptron
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








