| |

R integration with HadoopWhat is Hadoop?Hadoop is an open-source framework which was founded by the ASF - Apache Software Foundation. It is used to store process and analyze data that are huge in volume. Hadoop is written in Java, and it is not OLAP (Online Analytical Processing). It is used for batch/offline processing. It is being used by Facebook, Google, Twitter, Yahoo, LinkedIn, and many more. Moreover, it can be scaled up just by adding nodes in the cluster. Why integrate R with Hadoop?R is an open-source programming language. It is best suited for statistical and graphical analysis. Also, if we need strong data analytics and visualization features, we have to combine R with Hadoop. The purpose behind R and Hadoop integration:
R Hadoop Integration MethodHadoop and R complement each other very well in terms of big data visualization and analytics. There are four ways of using Hadoop and R together, which are as follows: 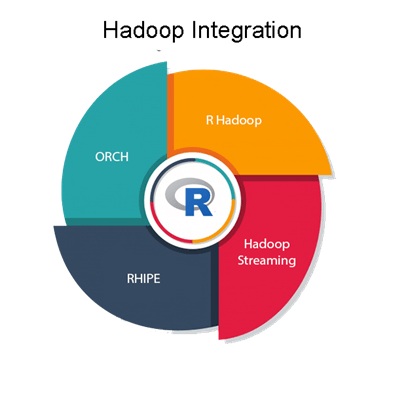
R HadoopThe R Hadoop methods are the collection of packages. It contains three packages i.e., rmr, rhbase, and rhdfs. The rmr package For the Hadoop framework, the rmr package provides MapReduce functionality by executing the Mapping and Reducing codes in R. The rhbase package This package provides R database management capability with integration with HBASE. The rhdfs package This package provides file management capabilities by integrating with HDFS. Hadoop StreamingHadoop Streaming is a utility that allows users to create and run jobs with any executable as the mapper and/or the reducer. Using the streaming system, we can develop working Hadoop jobs with just enough knowledge of Java to write two shell scripts which work in tandem. The combination of R and Hadoop appears as a must-have toolkit for people working with large data sets and statistics. However, some Hadoop enthusiasts have raised a red flag when dealing with very large Big Data excerpts. They claim that the benefit of R is not its syntax, but the entire library of primitives for visualization and data. These libraries are fundamentally non-distributed, making data retrieval a time-consuming affair. This is an inherent flaw with R, and if you choose to ignore it, both R and Hadoop can work together. RHIPERHIPE stands for R and Hadoop Integrated Programming Environment. Divide and Recombine developed RHIPE for carrying out efficient analysis of a large amount of data. RHIPE involves working with R and Hadoop integrated programming environment. We can use Python, Perl, or Java to read data sets in RHIPE. There are various functions in RHIPE which lets HDFS interact with HDFS. Hence, this way we can read, save the complete data which is created using RHIPE MapReduce. ORCHORCH is known as Oracle R Connector. This method is used to work with Big Data in Oracle appliance particularly. It is also used on a non- Oracle framework like Hadoop. This method helps in accessing the Hadoop cluster with the help of R and also helps to write the mapping and reducing functions. It allows us to manipulate the data residing in the Hadoop Distributed File System.
Next TopicR Packages
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








