| |
DS Tutorial
DS Array
DS Linked List
DS Stack
DS Queue
DS Tree
DS Graph
DS Searching
DS Sorting
Differences
Misc
DS MCQ

Remove the loop in a Linked ListIn this topic, we will learn how to remove the loop from the linked list. Till now, we have learnt how to detect and start of the loop by using Floyd's algorithm. The Floyd's algorithm will also be used to remove the loop from the linked list. Let's understand through an example. 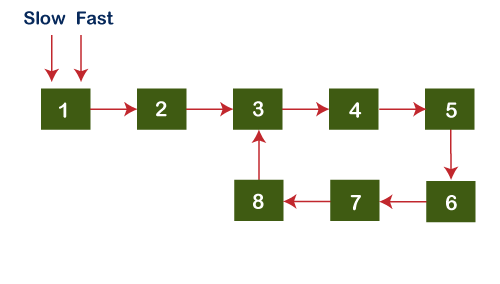
As we know that slow pointer increments by one and fast pointer increments by two. In the above example, initially, both slow and fast pointer point to the first node, i.e., node 1. The slow pointer gets incremented by one, and fast pointer gets incremented by two, and slow and fast pointers point to nodes 2 and 3, respectively, as shown as below: 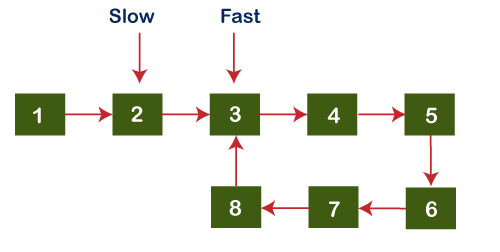
Since both the pointers do not point to the same node, we will increment both fast and slow pointers again. Now, slow pointer points to the node 3 while the fast pointer points to node 5 shown as below: 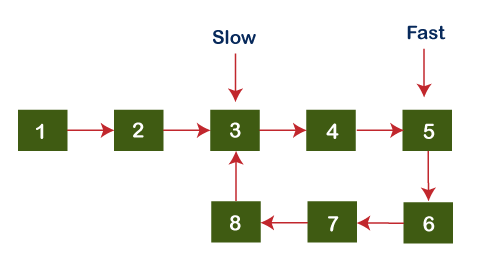
Since both the pointers do not point to the same node, we will increment both fast and slow pointers again. Now, the slow pointer points to node 4 while the fast pointer points to node 7 shown as below: 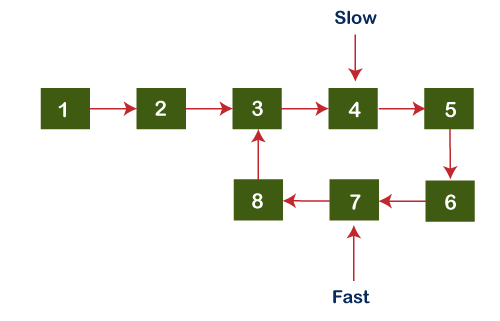
Since both the pointers do not point to the same node, we will increment both fast and slow pointers again. Now, the slow pointer points to node 5, and the fast pointer points to node 3 shown as below: 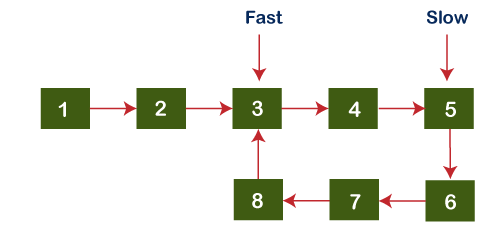
Since both the pointers do not point to the same node, we will increment both fast and slow pointers again. Now, slow pointer points to node 6 while the fast pointer points to the node 5 shown as below: 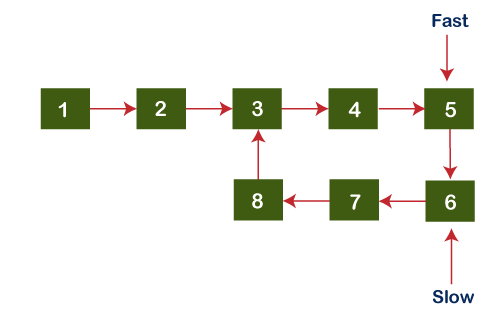
Again, both the pointers (slow and fast) are not pointing to the same node, so we will increment both fast and slow pointers again. Now, the slow pointer points to node 7, and the fast pointer also points to node 7 shown as below: 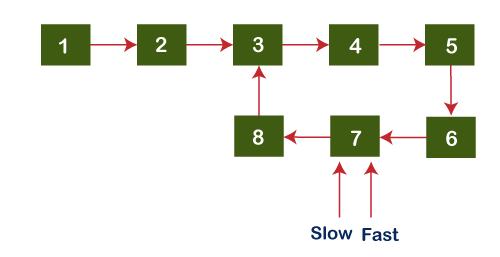
As we can observe in the above example both slow and fast pointers meet at node 7. We create one pointer named p1 that points to the node 7 where both the pointers meet, and we also create one more pointer named p2 that points to the first node as shown in the below figure: 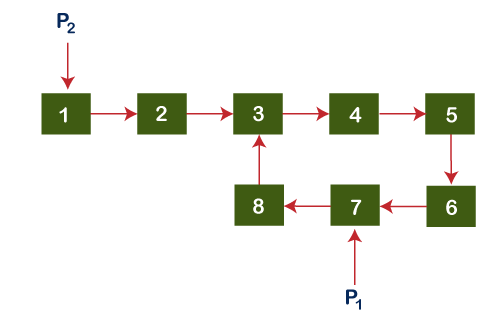
To remove the loop, we will define the following logic: The above logic is defined to remove a loop from the linked list. The while loop will execute till the p1.next is not equal to p2.next. When p1.next is equal to p2.next, the control will come out of the while loop, and we set the p1.next equal to Null. This statement breaks the link, which is creating the loop in the linked list. Implementation of removing a loop in COutput 
Next TopicImplement two stacks in an array
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








