| |

Jelinski and Moranda ModelThe Jelinski-Moranda (JM) model, which is also a Markov process model, has strongly affected many later models which are in fact modifications of this simple model. Characteristics of JM ModelFollowing are the characteristics of JM-Model:
λ(ti) = ϕ [N-(i-1)], i=1, 2... N .........equation 1 Where ϕ=a constant of proportionality indicating the failure rate provided by each fault N=the initial number of errors in the software ti=the time between (i-1)th and (i)th failure. The mean value and the failure intensity methods for this model which belongs to the binominal type can be obtained by multiplying the inherent number of faults by the cumulative failure and probability density functions (pdf) respectively: μ(ti )=N(1-e-ϕti)..............equation 2 And €(ti)=Nϕe-ϕti.............equation 3 Those characteristics plus four other characteristics of the J-M model are summarized in table:
AssumptionsThe assumptions made in the J-M model contains the following:
Variations in JM ModelJM model was the first prominent software reliability model. Several researchers showed interest and modify this model, using different parameters such as failure rate, perfect debugging, imperfect debugging, number of failures, etc. now, we will discuss different existing variations of this model. 
1. Lipow Modified Version of Jelinski-Moranda Geometric ModelIt allows multiple bugs removal in a time interval. The program failure rate becomes λ(ti)=DKni-1 Where ni-1 is the cumulative number of errors found up to the (i-1)st time interval. 2. Sukert Modified Schick-Wolverton ModelSukert modifies the S-W model to allow more than one failure at each time interval. The program failure rate becomes 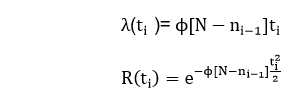
Where ni-1 is the cumulative number of failures at the (i-1)th failure interval. 3. Schick Wolverton ModelThe Schick and Wolverton (S-W) model are similar to the J-M model, except it further consider that the failure rate at the ith time interval increases with time since the last debugging. Assumptions
In the model, the program failure rate method is: λ (ti)= ϕ[N-(i-1)] ti Where ϕ is a proportional constant, N is the initial number of bugs in the program, and ti is the test time since the (i-1)st failure. 4. GO-Imperfect Debugging ModelGoel and Okumoto expand the J-M model by assuming that an error is removed with probability p whenever a failure appears. The program failure rate at the ith failure interval is λ (ti)= ϕ[N-p(i-1)] 5. Jelinski-Moranda Geometric ModelThis model considers that the program failure rate function is initially a constant D and reduce geometrically at failure time. The program failure rate and reliability method of time between failures at the ith failure interval are λ (ti)=DKi-1 Where k is Parameter of geometric function, 0<k<1 6. Little-Verrall Bayesian ModelThis model considers that times between failures are independent exponential random variables with a parameter € i=1, 2 ....n which itself has parameters Ψ(i) and α reflecting programmer quality and function difficulty having a prior gamma distribution. 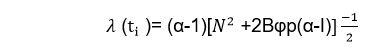
Where B represents the fault reduction factor 7. Shanthikumar General Markov ModelThis model considers that the failure intensity functions as the number of failures removed are as the given below λ SG(n, t) = Ψ(t) (N0-n) Where Ψ (t) is proportionality constant. 8. An Error Detection Model for Application during Software DevelopmentThe primary feature of this new model is that the variable (growing) size of a developing program is accommodated so that the quality of a program can be predicted by analyzing a basic segment. Assumptions This model has the following assumptions along with the JM model assumptions:
9. The Langberg Singpurwalla ModelThis model shows how several models used to define the reliability of computer software can be comprehensively viewed by adopting a Bayesian point of view. This model provides a different motivation for a commonly used model using notions from shock models. 10. Jewell Bayesian Software Reliability ModelJewell extended a result by Langberg and Singpurwalla (1985) and made an expansion of the Jelinski-Moranda model. Assumptions
11. Quantum Modification to the JM ModelThis model replaces the JM Model assumption, each error has the same contribution to the unreliability of software, with the new assumption that different types of errors may have different effects on the failure rate of the software. Failure Rate: 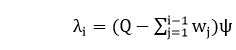
Where Q = initial number of failure quantum units inherent in a software Ψ = the failure rate corresponding to a single failure quantum unit wj= the number of failure-quantum units of the ith fault, i.e., the size of the ith failure-quantum 12. Optimal Software Released Based on Markovian Software Reliability ModelIn this model, a software fault detection method is explained by a Markovian Birth process with absorption. This paper amended the optimal software release policies by taking account of a waste of a software testing time. 13. A Modification to the Jelinski-Moranda Software Reliability Growth Model Based on Cloud Model TheoryA new unknown parameter θ is contained in the JM model parameters estimation such that θɛ [θL, θ∪]. The confidence level is the probability value (1-α) related to a confidence interval. In general, if the confidence interval for a software reliability index θ is achieved, we can estimate the mathematical characteristics of virtual cloud C(Ex, En, He), which can be switched to system qualitative evaluation by X condition cloud generator. 14. Modified JM Model with imperfect Debugging PhenomenonThe modified JM Model extends the J-M model by relaxing the assumptions of complete debugging process and types of incomplete removal:
Assumptions The assumptions made in the Modified J-M model contain the following:
List of various characteristics underlying the Modified JM Model with imperfect Debugging Phenomenon
Next TopicBasic Execution Time Model
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








