| |

SQL Server Window FunctionsWe are all well-known for the regular aggregate function that performs calculations on the table and works with a GROUP BY clause. However, only a small percentage of SQL users use Window functions, and these are functions that work on a group of rows and display a single aggregated value for every row. This article will discuss in detail the window functions in SQL Server. What is window functions?Window functions are used to perform a calculation on an aggregate value based on a set of rows and return multiple rows for each group. The window word represents the group of rows on which the function will be operated. This function performs a calculation in the same way that the aggregate functions would perform. Unlike aggregate functions that operate on the entire table, Window functions do not give a result to be combined into a single row. It means that window functions work on a group of rows and return a total value for each row. As a result, each row retains its distinct identity. The below pictorial representations explain the difference of aggregate function and window function in SQL Server: 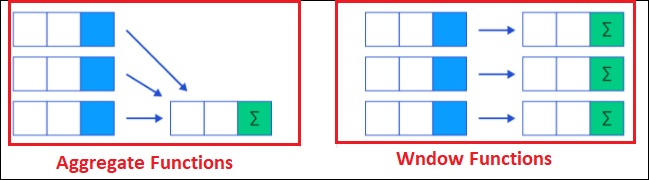
Window Functions TypesSQL Server categorizes the window functions into mainly three types:
Syntax The following are the basic syntax for using a window function: Parameter Explanation Let us understand the arguments used in the above syntax: window_function: It indicates the name of your window function. ALL: It is an optional keyword that is used to count all values along with duplicates. We cannot use the DISTINCT keyword in window functions. Expression: It is the name of the column or expression on which window functions is operated. In other words, it is the column name for which we calculate an aggregated value. OVER: It specifies the window clauses for aggregate functions. It mainly contains two expressions partition by and order by, and it always has an opening and closing parenthesis even there is no expression. PARTITION BY: This clause divides the rows into partitions, and then a window function is operated on each partition. Here we need to provide columns for the partition after the PARTITION BY clause. If we want to specify more than one column, we must separate them by a comma operator. SQL Server will group the entire table when this clause is not specified, and values will be aggregated accordingly. ORDER BY: It is used to specify the order of rows within each partition. When this clause is not defined, SQL Server will use the ORDER BY for the entire table. ExampleLet us understand the concept of window function through an example. First, we will create a table named "product_sales" using the following statement: Next, we will fill records into this table using the INSERT statement as below: We can verify the inserted records using the SELECT statement. We will see the below output: 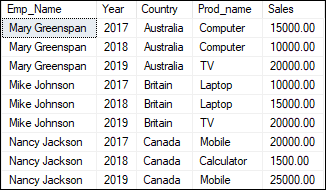
Now we will demonstrate all window functions using this table. Aggregate Window FunctionSUM() It is an aggregate function that performs the addition of the specified field for a specified group or the entire table when we have not specified any group. Here we will examine this function in both ways, either regular aggregate function or window aggregate function. The below statement explains the regular aggregate function that adds the order amount for each country: Executing the statement, we see that this function groups multiple rows into a single output row. It causes individual rows to lose their identity. 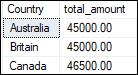
The below statement explains the window aggregate function that maintains the row identity. It also displays the aggregated value for each row. Executing the query will return the below output. Here we can see that it aggregates the data for each country and displays the sum of total sales for each of them. It also inserts another column for the total sales as grand_total so that each row retains its identity. 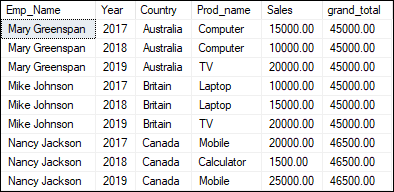
AVG() This function returns the average value of the specified column. It works in exactly the same way with a window function. The below example will produce the average sales for each country and each year. Here we have specified more than one average by specifying multiple fields in the partition list. Executing the statement will return the below output where we can see that on average, we have received a sale amount of 15000 for Australia country. 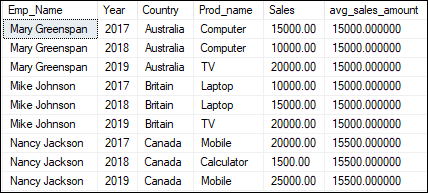
MIN() This function returns the minimum value for a specified group. When we have not defined the group, it will return the minimum value for the entire table. The below example will return the smallest sales amount for each country: Executing the query will produce the below output where we can see the minimum sales amount for each country: 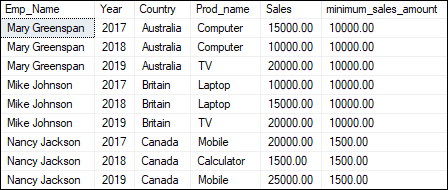
MAX() This function returns the maximum value for a specified group. When we have not defined the group, it will return the maximum value for the entire table. The below example will return the highest sales amount for each country: Executing the query will produce the below output where we can see the highest sales amount for each country: 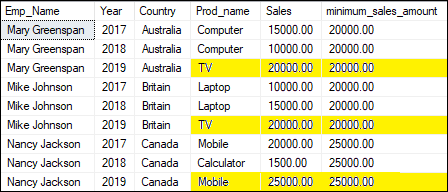
COUNT() The count function will return the total number of rows or records present in the table or group. The regular aggregate function uses the DISTINCT keyword not to count the duplicates rows. But the window count function does not support this keyword. If we use this keyword with the window function, SQL Server throws an error. Suppose we want to see how many employees order the product in the year 2018. We cannot directly count all employees as the same employee has ordered multiple products in the same year. For example, COUNT(emp_name) will produce the incorrect result because it can count duplicates also. COUNT(DISTINCT emp_name) will produce the correct result because it always counts each employee only once. This statement is executed successfully as it is a regular aggregate function: This statement will produce an error as it is a window aggregate function: Here is the error: 
The below statement will return the total product sales in each country using the window count function: Here is the result: 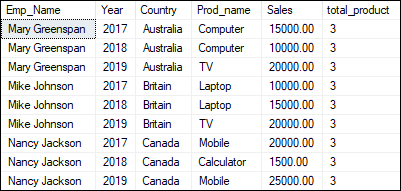
Ranking Window FunctionsThe RANKING function ranks the values in a defined column and categorizes them based on their rank. The following are the ranking functions supported in SQL Server: RANK(), DENSE_RANK(), ROW_NUMBER(), and NTILE(). Let us discuss each function in detail based on the table named "rank_demo" that contains the below data: 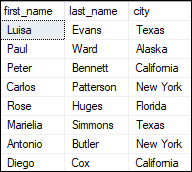
RANK() It's used to generate a unique rank for each row in a table based on the specified value. If this function gets the two records with the same value, it will assign the same rank to both records and skip the next ranking. For example, if rank 2 has two identical values, the rank function provides the same rank 2 to both records and skip the next rank 3. Now, the next rank will be assigned with rank 4. The below statement explains the RANK() function by assigning numbering to each row based on the city: This query returns the below output where we see that the same rank (2) is assigned to two identical records having equal city names. The next number in the ranking will be its previous rank plus a number of duplicate numbers, i.e. 4. 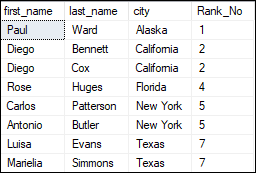
DENSE_RANK() It works the same as the RANK() function except that it does not skip any rank. It always assigns rank in consecutive order. It means that when two records are found equal, this function will assign the same rank to both records and the next rank being the next sequential number. The below query explains this function practically to assign a rank number for each row based on the city: This query will return the below output where we can see that the duplicate values have the same rank, and the next rank is given to the next record without skipping a rank value. 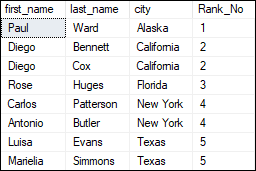
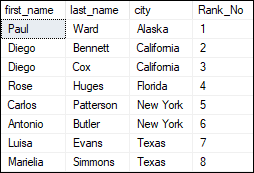
ROW_NUMBER() It is used to assign a unique sequential number to each record within the partition. It always starts with one and increases by one until all the records in a partition are not reached. It will be reset when one partition ranking is completed and goes to the next partition. Example of ROW_NUMBER() without PARTITION BY The below query assigns the number to each row based on the city: It returns the following output:
Example of ROW_NUMBER() with PARTITION BY The below statement partition the table based on the city, which means the row number is reset for each city and restarts at 1 again. It is also ordering the records on the basis of the first_name column. It returns the below output: 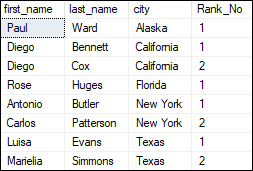
NTILE() This window function distributes rows into a pre-defined number (N) of approximately equal groups. Each row group is assigned a rank depending on the defined condition, and the numbering begins with the first group. It enables us to determine which percentile (or quartile, or other subdivision) a particular row belongs to. It implies that if we have 20 records and want to divide them into five quartiles based on a specific value field, we can easily do so and see how many rows are in each quartile. The following statement will divide the table into 3 quartiles based on the city column: Executing the statement will return the below output where we see each group have three quartiles: 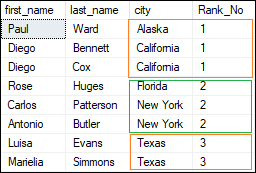
PERCENT_RANK() This function evaluates a percentile rank (relative rank) for rows within a partition of a result set. It gives the result between 0 and 1. If it finds the NULL value, it treats them as the lowest possible value. This function evaluates the rank with the help of the below formula for each record: Here, rank indicates the numbering of each row returns by rank() function, and total_rows are the total number of rows found in the partition. The following example will calculate the rank value for each row order by country name: Executing the statement will return the expected output: 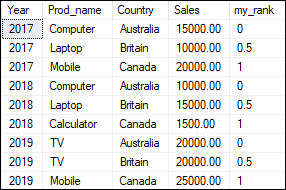
Value Window FunctionsSQL Server used this function to get the first, last, previous, and next values in a table. It mainly contains these functions: LAG(), LEAD(), FIRST_VALUE(), and LAST_VALUE(). LEAD and LAG Function The LEAD and LAG functions are used to get the preceding and succeeding values of specified rows from the current row within its partition. Let us take the above product_sales table to demonstrate these functions. The following example returns the sales and next sales detail of each employee. It first split the result set based on the year and then sorted each partition using the country column. After that, we have to use the LEAD() function on each partition to get the next sales detail. Executing the statement will display the expected result: 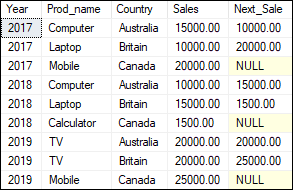
The following example returns the sales and previous sales detail of each employee. It first split the result set based on the year and then sorted each partition using the country column. After that, we have to use the LAD() function on each partition to get the previous sales detail. Executing the statement will display the expected result: 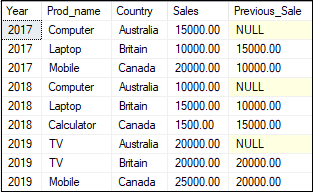
FIRST_VALUE() and LAST_VALUE() These functions are used to find the first and last record in the table or a partition if the PARTITION BY clause is specified. Here we should note that these functions are mandatory to use the ORDER BY clause. Let us see how these functions work in SQL Server through practical examples. The following example will find the first and last sales of each country in a given table: Executing the query will display the expected result as shown below: 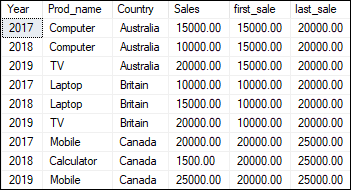
Conclusion This article will explain all window functions used in the SQL Server that work on a set of rows and return a single aggregated value for every row.
Next TopicSQL Server Date Functions
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








