Statistics in SPSS
- In this section, we are going to learn fundamental or statistics. Statistics is a branch of mathematics that is used for organization and interpretation of the numerical data. When it comes to the data organization, the kind of statistics we used are known as descriptive statistics.
- So descriptive statistics is basically used to describe the situation or the event, or whatever the property that we are measuring. For example, suppose we are discussing the marks obtained by the student in the examination, we might be interested in the average marks scored by the student, or the spread or division of the marks. So mean, median, standard deviation, percentile, etc. they all examples of descriptive statistics.
- We also use SPSS to calculate the descriptive statistics, but most often, we work with the interpretation of numerical data, and we try to draw certain inferences based on the available data. So apart from interpretation, we should use inference. The practical use of statistics is to draw inference from the numerical data.
- Now, when it comes to drawing inferences, we have to go by two approaches that depend upon the nature of our data. So we can have two types of approaches here known as parametric statistics and non-parametric statistics.
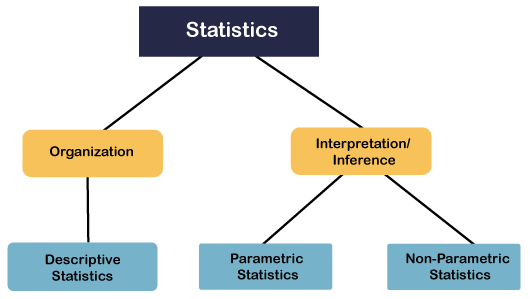
- Parametric statistics refer to the kind of stats that is used to certain assumptions about the population parameters. Parameters can be mean, standard, deviation, homogeneity of variance, randomness of the selection, and dependence of samples. So if these assumptions are fulfilled, we use a kind of stat (statistics) known as a parametric stat.
- Our t-test, z score, regression, linear regression are examples of the parametric stat, but when these assumptions are violated, we use a kind of stat known as a non-parametric stat. For example, mann whitney u test or most popular chi square test. These are the test we use when our data fails to meet one of the four assumptions recommended for the parametricity.
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








