| |

TensorFlow Audio RecognitionAudio recognition is an interdisciplinary subfield of computational linguistics that develops methodologies and technologies that enables the recognition and translation of spoken language into text by computers. Speech recognition is commonly used to operate a device, perform commands, and write without the help of keyboard, mouse, or press any buttons. These days, it is done on a computer with ASR (automatic speech recognition) software programs. Many ASR programs require the user to "training" the ASR programs to recognize its voice so that it can more accurately convert the speech to text. For example, we can say "open Google chorme," and the computer would open the internet browser chrome. The first ASR device is used in 1952 and recognized single digits spoken by any user. In Today's Time, ASR programs are used in many industries, including military, healthcare, telecommunications, and personal computing. Example where we may have used voice recognition:Google voice, automated phone systems, Digital voice, digital assistant, car Bluetooth. Types of voice recognition systemsAutomatic speech recognition is an example of voice recognition. Below are some other examples of voice recognition systems.
Training in TensorFlow Audio RecognitionTo start the training process in TensorFlow Audio Recognition, represent to the TensorFlow source and wr the following: This command can download the speech dataset, which consists of 65k. Wav audio files where people see 30 different words. Confusion Matrix in TensorFlowThe first 400 steps, will give us: We see that the first section is a matrix. Every column represents a set of samples which were estimated to each keyword. In the above matrix, the first column represents all the clips that are predicted to be silence, the second representing the unknown words, the third "yes", and so on. TensorBoard in TensorFlowWe visualize the training progress using TensorBoard. The events are saved to /tmp/retrain_logs, and loaded using the below syntax: 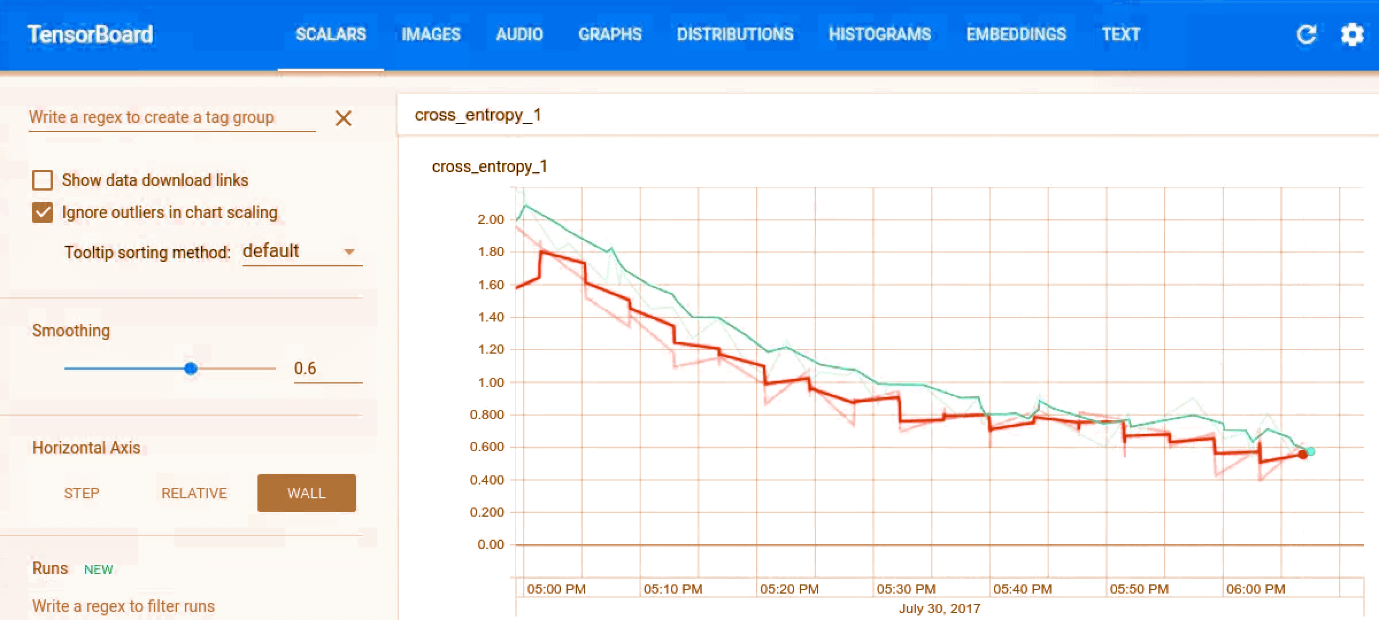
Finished Training in Audio RecognitionAfter some hours of training, the script completes about 20,000 steps, printing out the final confusion matrix, and the accuracy percentage We can export to mobile devices in a compact form using the given code: Working of Speech Recognition ModelIt is based on the kind of CNN that is very familiar to anyone who's worked with image recognition like we already have in one of the previous tutorials. The audio is a 1-D signal and not be confused for a 2D spatial problem. Now, we have to solve the issue by defining a time slot in which our spoken words should fit, and changing the signal in that slot into an image. We can do this by grouping the incoming audio into short segments and calculating the strength of the frequency. Each segment is treated like a vector of numbers, which are arranged in time to form a 2D array. This array of values can be treated like a one-channel image, is also known as the spectrogram. We can view what kind of images an audio sample produce with: /tmp/spectrogram.png will show us: 
This is a 2d, one-channel representation so that we tend it like an image too. The image which produced is then fed into a multi-layer convolutional neural network, with a fully-connected layer followed by a softmax at the end. Command Recognition in TensorFlow
Unknown Class Our app may hear sounds that are not a part of our training set. To make the network learn which sound to boycott, we need to provide clips of audio that are not a part of our classes. To do this, we can create boo, meow, and fill them with noises from animals. The speech commands dataset includes 20 words in its unknown classes, including the digits, zero through nine along with random names. Background Noise There are background noise in any captured audio clip. To build a model that's resistent to this such noises, we need to train the model against recorded audio with identical properties. The files in the speech command dataset were recorded on multiple devices and in different surroundings, so that help for the training. Then, we can randomly choose small extracts from the files along mixed at a low volume into clips during training. Customizing The model used for the script, which is enormous, using 940k weight parameters that will have too many calculations to run at speeds on devices with limited resources. The other options to counter this are: low_latency_conv: The accuracy is lower than conv, but the amount of weight parameters is nearly the same, and it is much faster We should specify-model-architecture=low_latency_conv to use this model on the command line. We should add parameters as the learning rate=0.01 and steps=20,000. low_latency_svdf: The accuracy is lower than conv but it only uses 750k parameters and has an optimized execution. Typing-model_architecture=low_latency_svdf on the command line to use the model, and specifying the training rate and the number of steps along with:
Next TopicTensorFlow APIs
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








