| |

MNIST Dataset in CNNThe MNIST (Modified National Institute of Standards and Technology) database is a large database of handwritten numbers or digits that are used for training various image processing systems. The dataset also widely used for training and testing in the field of machine learning. The set of images in the MNIST database are a combination of two of NIST's databases: Special Database 1 and Special Database 3. The MNIST dataset has 60,000 training images and 10,000 testing images. The MNIST dataset can be online, and it is essentially a database of various handwritten digits. The MNIST dataset has a large amount of data and is commonly used to demonstrate the real power of deep neural networks. Our brain and eyes work together to recognize any numbered image. Our mind is a potent tool, and it's capable of categorizing any image quickly. There are so many shapes of a number, and our mind can easily recognize these shapes and determine what number is it, but the same task is not simple for a computer to complete. There is only one way to do this, which is the use of deep neural network which allows us to train a computer to classify the handwritten digits effectively. 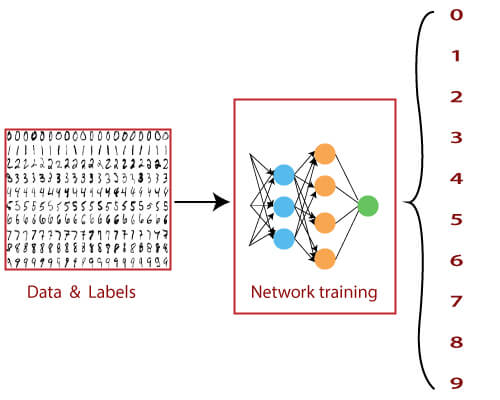
So, we have only dealt with data which contains simple data points on a Cartesian coordinate system. From starting till now, we have distributed with binary class datasets. And when we use multiclass datasets, we will use the Softmax activation function is quite useful for classifying binary datasets. And it was quite effective in arranging values between 0 and 1. The sigmoid function is not effective for multicausal datasets, and for this purpose, we use the softmax activation function, which is capable of dealing with it. The MNIST dataset is a multilevel dataset consisting of 10 classes in which we can classify numbers from 0 to 9. The major difference between the datasets that we have used before and the MNIST dataset is the method in which MNIST data is inputted in a neural network. In the perceptual model and linear regression model, each of the data points was defined by a simple x and y coordinate. This means that the input layer needs two nodes to input single data points. In the MNIST dataset, a single data point comes in the form of an image. These images included in the MNIST dataset are typical of 28*28 pixels such as 28 pixels crossing the horizontal axis and 28 pixels crossing the vertical axis. This means that a single image from the MNIST database has a total of 784 pixels that must be analyzed. The input layer of our neural network has 784 nodes to explain one of these images. 
Here, we will see how to create a function that is a model for recognizing handwritten digits by looking at each pixel in the image. Then using TensorFlow to train the model to predict the image by making it look at thousands of examples which are already labeled. We will then check the model's accuracy with a test dataset. MNIST dataset in TensorFlow, containing information of handwritten digits spitted into three parts:
Now before we start, it is important to note that every data point has two parts: an image (x) and a corresponding label (y) describing the actual image and each image is a 28x28 array, i.e., 784 numbers. The label of the image is a number between 0 and 9 corresponding to the TensorFlow MNIST image. To download and use MNIST dataset, use the following commands: 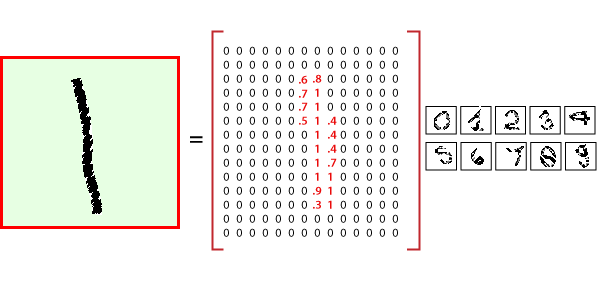
Softmax Regression in TensorFlowThere are only ten possibilities of a TensorFlow MNIST to be from 0 to 9. Our aim is to look at an image and say with the particular probability that a given image is a particular digit. Softmax is used when there is a possibility as the regression gives us values between 0 and 1 that sum up to 1. Therefore, our approach should be simple. 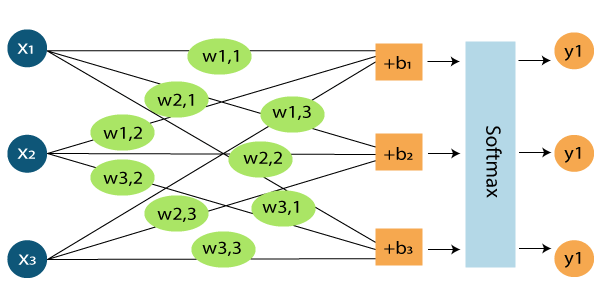
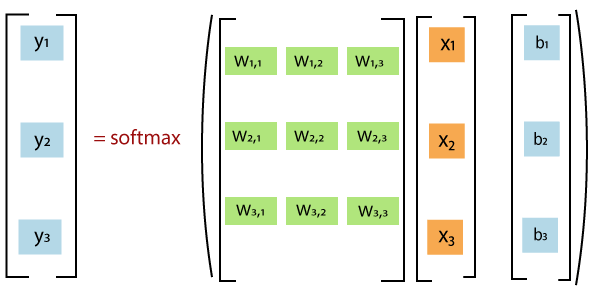
We classify a TensorFlow MNIST image to be in a specific class and then represent it as a probability of being correct or not. Now, it's totally up to all objects in a particular class, and we can do a weighted sum of the pixel intensities. We also need to add a bias to concur that some things are more likely independent of the input. Softmax normalizes the weights and adds them hypothesis has a negative or a zero weight. Implementation of MNIST Dataset in TensorFlowThe benefit of using TensorFlow MNIST dataset classification is that it lets us describe a graph of interacting operations that run entirely outside Python. First, we import the TensorFlow library using Then we create a placeholder, a value that we'll input when we ask the library to run a computation using We should then add weights and biases to our model. Using Variable, which is a modifiable tensor that has a scope in the graph of interacting operations. Notice that shape of W is [784, 10] as we want to produce 10- dimensional vectors of evidence for different classes by multiplying 784-dimensional image vectors by it. We can add b to the output as it has a shape of [10]. TensorFlow MNIST- TrainingWe define a model by multiplying the feature matrix with the weight and add a bias to it, then running it through a softmax function. We use a cost function or a mean squared error function to find the deviation of our results from the actual data. The less the error, the better is the model. Another very common function is the cross-entropy when measures how inefficient our predictions are. The function is described below, where y represents the predictions and y' is the actual distribution. We implement it by adding a placeholder. Then defining the cross-entropy by Now that we have successfully defined our model, it's time to train it. We can do this with the help of gradient descent and backpropagation. There are many other optimization algorithms available as well, such as logistic regression, dynamic relaxation, and many more. We can use gradient descent with a learning rate of 0.5 for cost function optimization. Before training, we need to start a session and initialize the Variable we created earlier. This starts an interactive session and variables are initialized by Now, we have to train the network. We should change the number of epochs to suit our model. Checking Accuracy with Test DatasetWe check the accuracy by comparing our results with a test dataset. Here, we can make use of tf.argmax function, which lets us know the index of the highest value in a tensor along a particular axis. This gives us the list of Booleans, and then we take the mean after converting to floating-point numbers. Then, we can print out the accuracy by |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








