| |

TensorFlow PlaygroundThe TensorFlow Playground is a web application which is written in d3.js (JavaScript). And it is the best application to learn about Neural Networks (NN) without math. In our web browser, we can create a NN (Neural Network) and immediately see our results. It is licensed under Apache license 2.0, January 2004 (http://www.apache.org/licenses/). Daniel Smilkov and Shan Carter create it and based on a continuation of many previous works. And its contributing members are Fernanda Viegas and Martin Wattenberg and the Big Picture and Google Brain teams for feedback and guidance. TensorFlow Playground is a web app that allows users to test the artificial intelligence (AI) algorithm with TensorFlow machine learning library. TensorFlow Playground is unfamiliar with high-level maths and coding with neural network for deep learning and other machine learning application. Neural network operations are interactive and represented in the Playground. The open-source library is designed for educational requirements. Now go to the link http://playground.tensorflow.org. 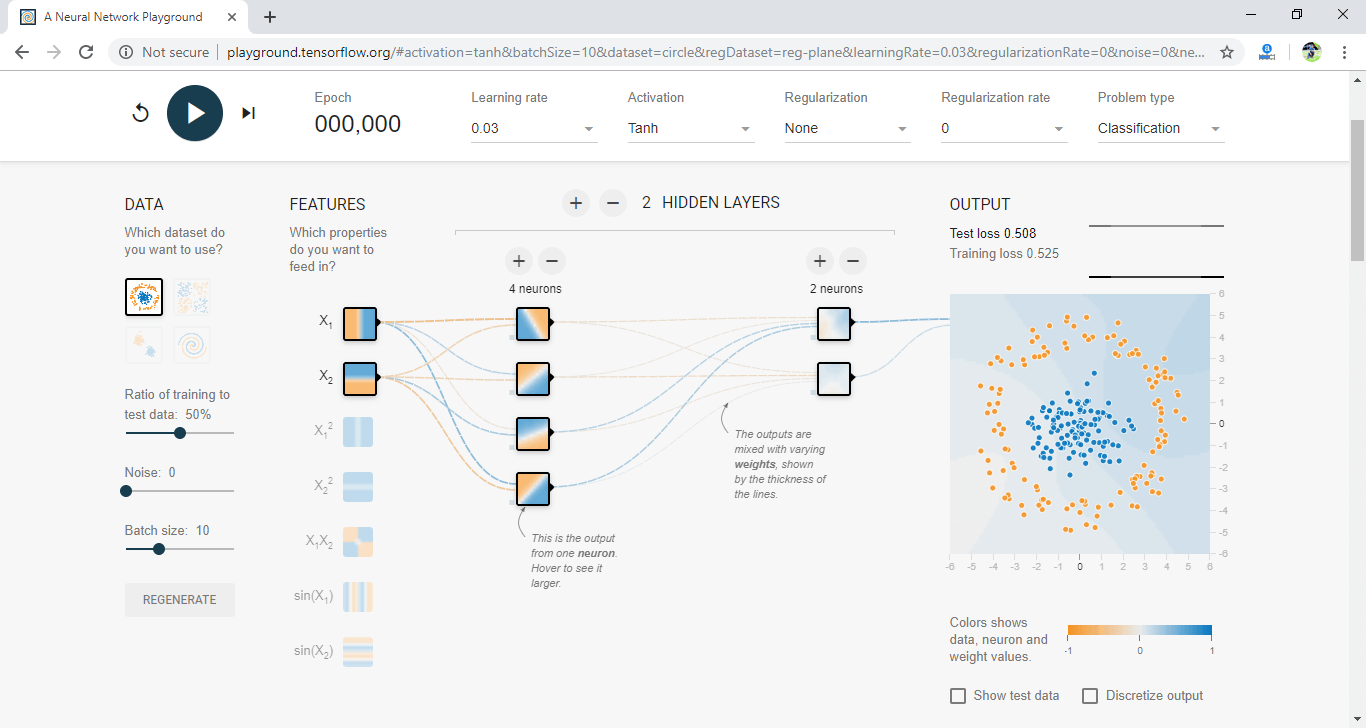
The top part of the website is Epoch, Learning rate, Activation, Regularization rate, Problem type, which are described below one by one. Every time training is conducted for the training set, and the Epoch number increases as we can see below. 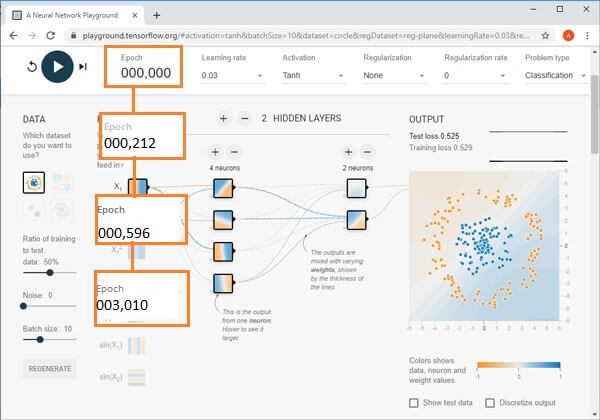
The Learning rate determines the speed of learning; therefore, we need to select the proper learning rate. 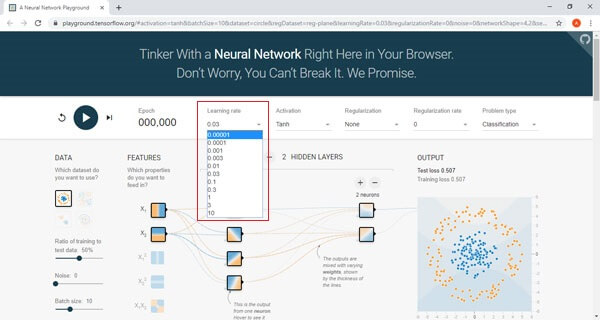
The activation function of the node defines the output of that node or set of data. A standard computer chip circuit can be a digital network of activation function which can be "ON" (1) or "OFF" (0), depending on its input. 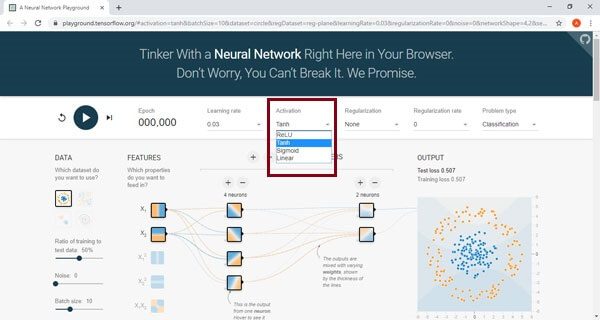
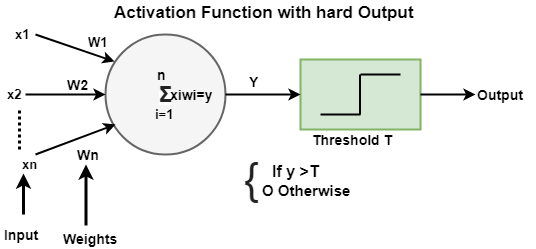
Soft Output Activation Function
Regularization is used to avert overfitting. TensorFlow playground implements two types of Regularization: L1, L2. Regularization can increase or reduces the weight of a firm or weak connection to make the pattern classification sharper. L1 and L2 are popular regularization methods. 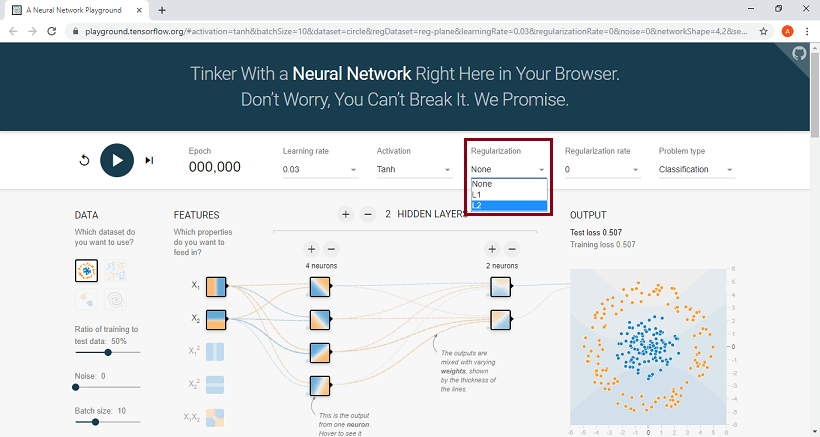
L1 Regularization
L2 Regularization
Dropout is also a regularization method. A higher regularization rate will make the weight more limited in range. 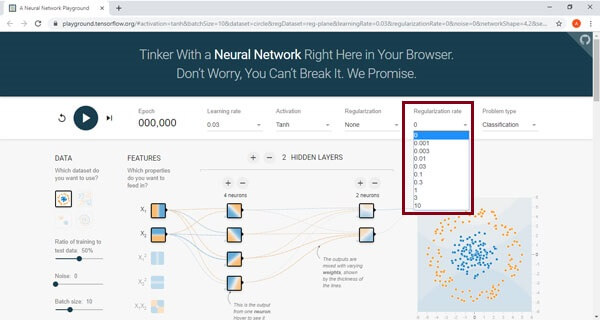
In problem type select among the two types of problems among below:
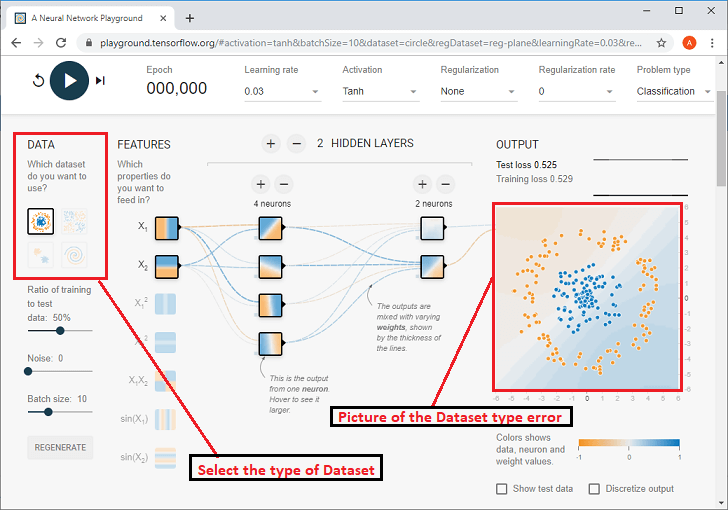
We have to see what type of problem we're going to solve based upon the dataset that we specify right here. Solve based on data set that we define below. 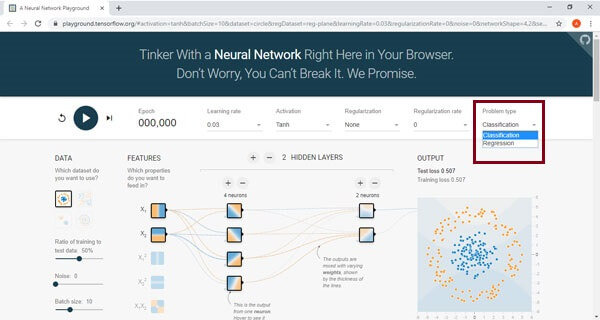
Overall, there are four types of classification, and there are two types of Regression problems that exist are given below. 
Here Blue and orange dots form data sets implies that Orange dot has the value -1. Blue dot value is +1 Using the Ratio of training of test data, the percentage of the training set be controlled using the control module over here. 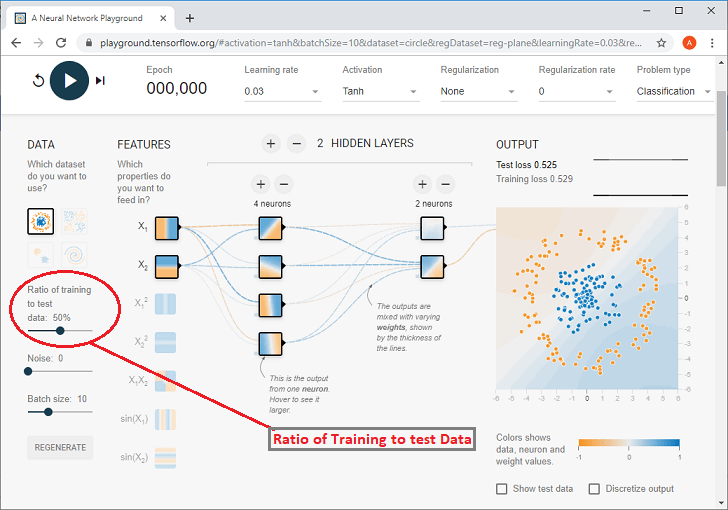
For Example: If it's 50%, the dots are the same as it is because that was its default setting, but if we change the control to make that 10%. Then we can see that dots over there becoming much less like the given figure. 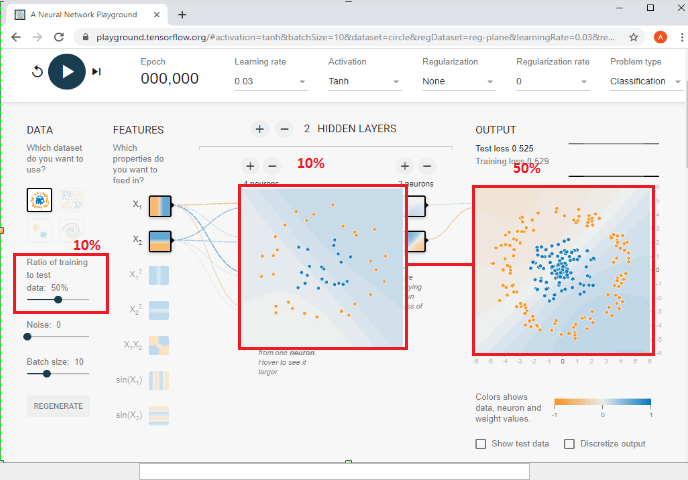
The Noise level of the data set can be controlled. We can do that using the control module. The data pattern becomes more unreliable as the noise increases. When the noise is zero, then the problem is clearly distinguished in its regions. However, by making it over to 50, we can see that the blue dots and the orange dots get all mixed up, and making it impose to allocate. 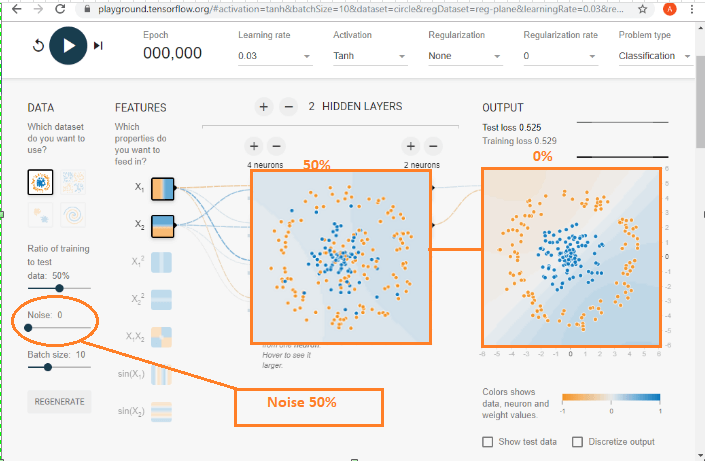
The batch size determines the data rate to use for each training iteration, and we control this according to the below screenshot. We can control it using below. 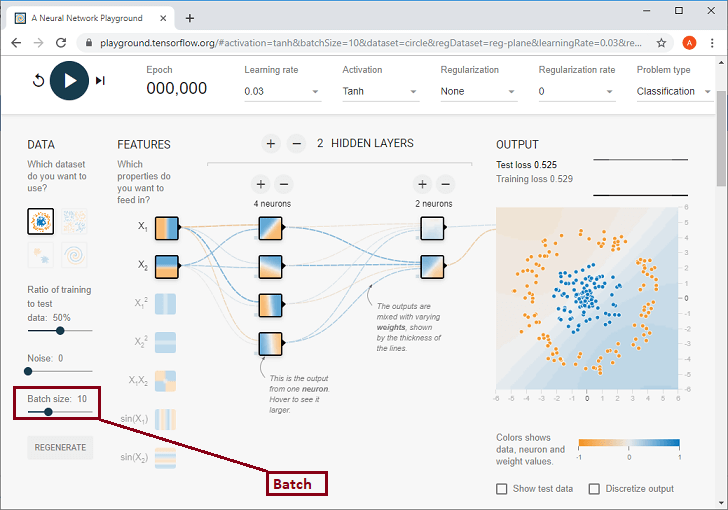
Now, we need to make the Feature selection. Feature Selection will use x1 and x2 which are given here;
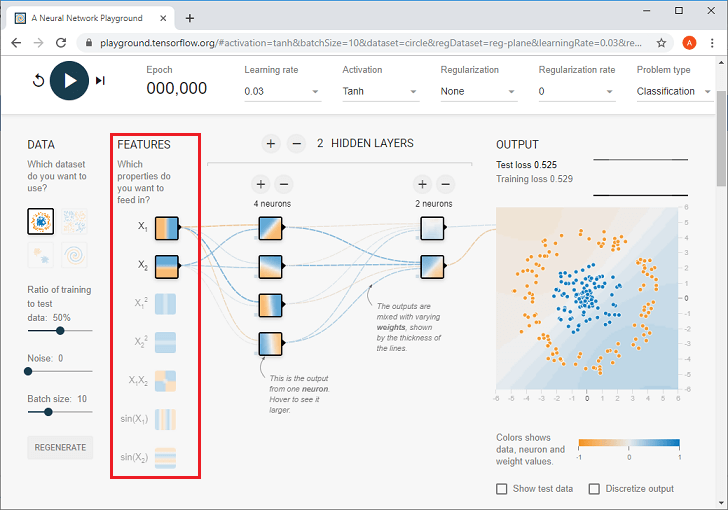
Example of x1 and x2- The dot has approximately an x1 value of 3.1 and x2 value of 4, like, we can see in the below diagram. 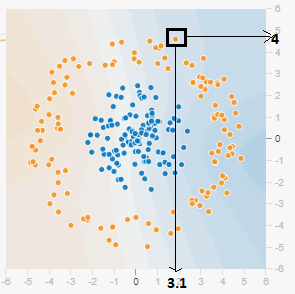
The hidden layer structure is listed below, where we can have up to six hidden layers can be set. If we want to control the number of hidden layers by adding a hidden layer, then click on the plus sign. And also we can have added up to eight neurons per hidden sheet and control this by clicking on plus sign to add a neuron to a hidden layer. 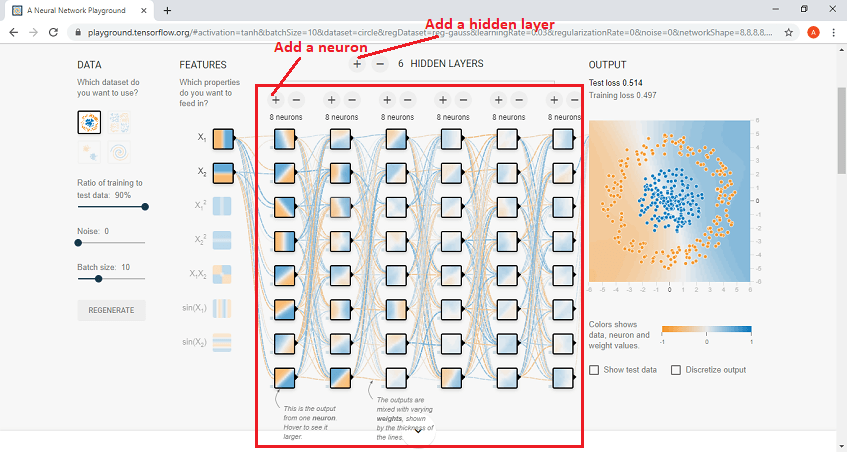
By pressing the arrow button starts the NN (Neural Network) training where Epoch will increase by one, and backpropagation is used to train the neural network. If we need to refresh the overall practice, then we can do that by clicking on the refresh button. 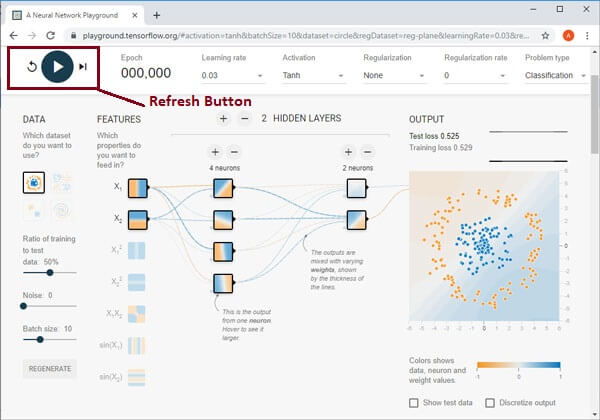
The NN (Neural Network) minimizes the Test Loss and Training Loss. The Test Loss and Training loss change will be presented in small performance curves that will be located on the right side below. The Test Loss will have a white performance curve, and the Training Loss will have a grey performance curve. If the loss is reduced, the curve will go down. 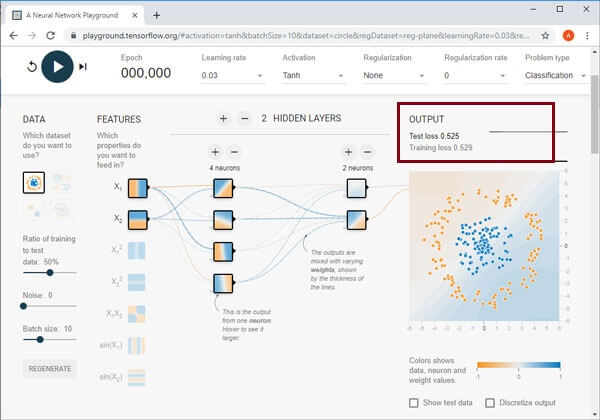
Neural Network Model/ PerceptronA neural network model or Perceptron is a network of simple components called neurons that receive input, change their internal state according to the data. And produce output (0 and 1) depending on the data and activation. We have only one input and output, and at best, one hidden layer in the most accessible neural network called shallow neural network. 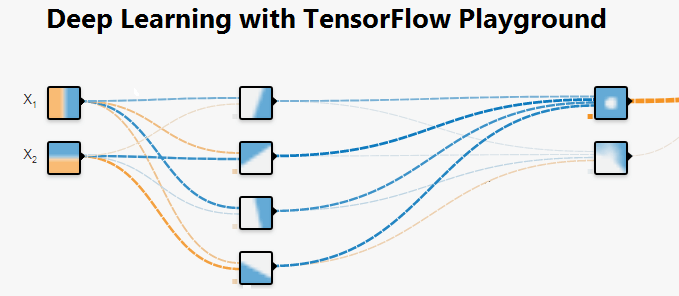
All colors mean in the PlaygroundOrange and blue are used to visualization differently, but in real orange shows negative values and blue shows positive values. The data points are colored orange or blue, which correspond to a positive one and a negative one. In hidden layers, the lines are colored by the weights of the connections between the neurons. Blue shows the actual weight and orange shows the negative weight. In the output layer, the dots are colored orange or blue depending on original values. The background color shows what the network is predicting for a particular area. Use CasesWhy can we increase neurons in the hidden layer?We can start with the basic model (Shallow neural network) in a single neuron in the hidden layer. Let's pick the dataset 'Circle,' features' X1' and 'X2', 0.03 learning rate, and 'ReLU' stimulation. We would press the run button and wait for the completion of a hundred epochs and then click on 'pause.' 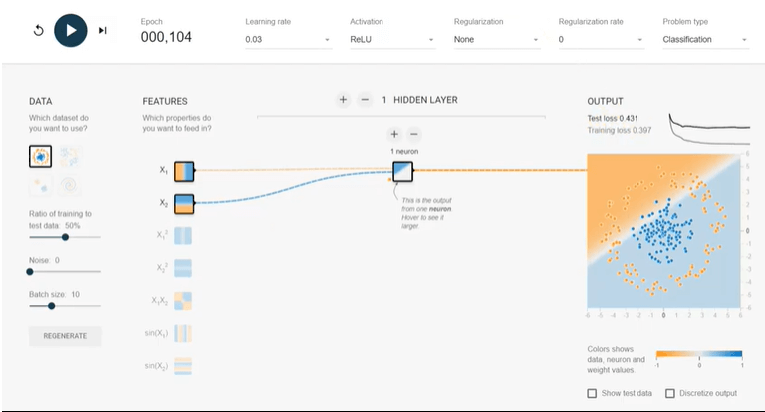
The training loss and test are more than 0.4, after fulfillment of 100 epochs. Now we will add four neurons in the hidden layer using the add button and run again. Now, our test and training loss is then 0.02, and the output is very well classified in two classes (orange and blue colors). The addition of neural in hidden layer provides flexibility to assign different weight and parallel computation. However, adding neurons after a certain extent will be expensive with little benefit. Why we use a non-linear activation function for classification problems?In the neural network, we use non-linear activation functions for the classification problem because our output label is between 0 and 1, where the linear activation function can provide any number between -∞ to +∞. In the result, the output will not be converged at any time. 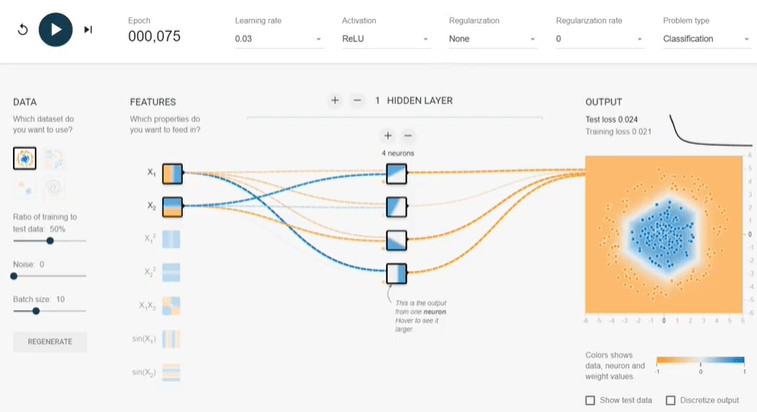
In the above diagram, we ran the same model but linear activation, and it is not converging. The test and training efficiency is more than 0.5 after 100 epochs. Why can we increase the hidden layers in the Playground?Now, we add one more hidden layer with double neurons and press the run button. Our test and accuracy reduced below 0.02 in only 50 epoch and almost half as compared to any single hidden layer model. And similar to neurons, adding hidden layers will not be the right choice for all cases. It becomes expensive without adding any benefit. It is very well explained in the picture. Even if 100 epoch running, we couldn't achieve a good result. 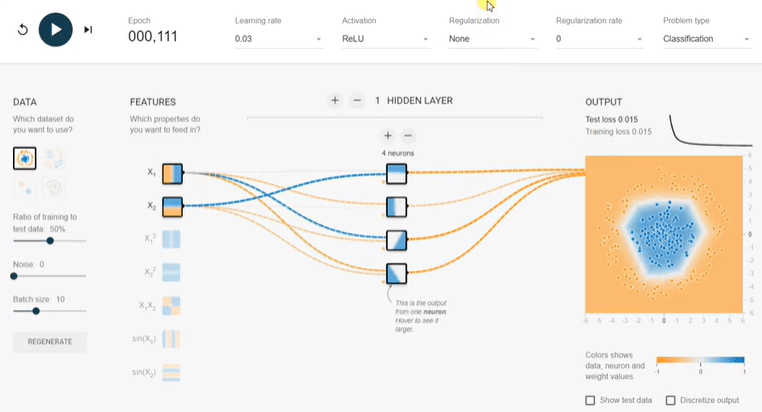
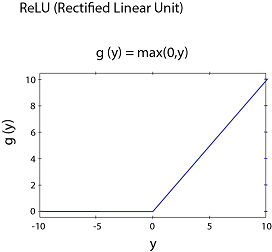
Why ReLU activation is an excellent choice for all the hidden layers because the derivative is 1 if z is positive and 0 when z is negative. We will run the training different activation functions (ReLU, sigmoid, tanh, and linear), and we will see the impact. 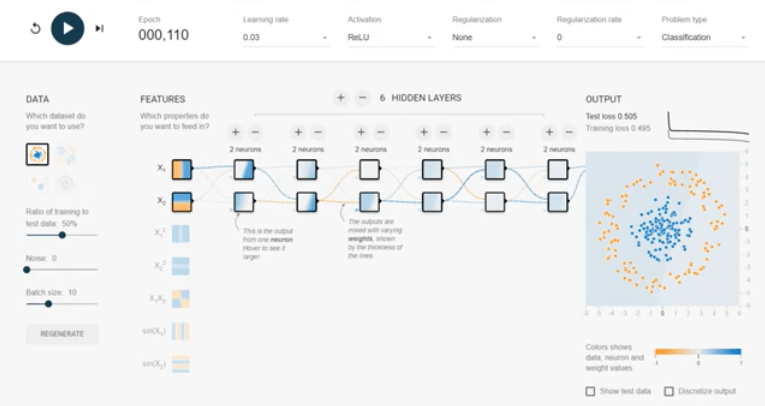
Why the ReLU activation the right choice for hidden layers?Rectified linear unit (ReLU) is an elected choice for all hidden layers because its derivative is one if z is positive and 0 when z is negative. On another way, both sigmoid and tanh functions are not suitable for hidden layers because if z is very large or small. Then the scope of the task becomes very small, which slows down into the gradient descent. 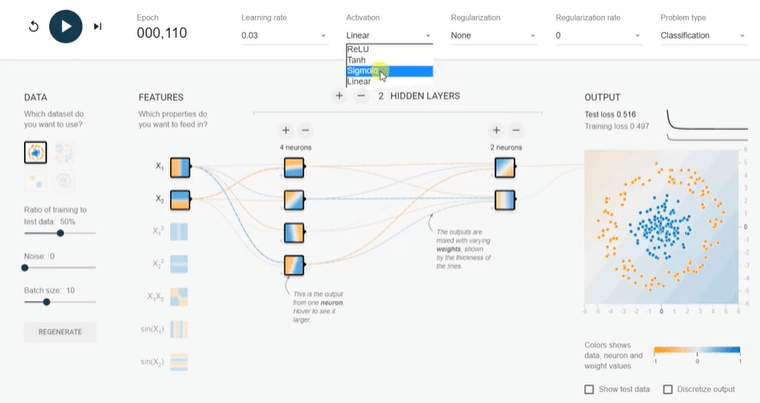
In the above figure, it is clear that ReLU outperforms all other activation functions. Tanh performs very well with our selected data set but not as efficient as ReLU function. This is the main reason that ReLU is so prevalent in deep learning. The action of adding/reducing or changing any input featuresAll available features do not help to the model the problem. Using all features or unrelated features will be expensive and may impact on final accuracy. In real-life applications, it takes a lot of trial and error to figure out which methods are most useful for the problem. We will explore different functions in our model. 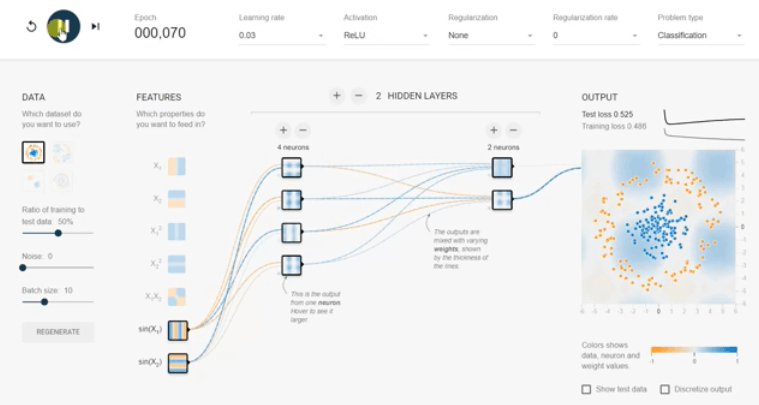
Next TopicTensorFlow Basics
|
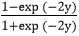
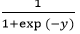
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








