| |

Teradata ArchitectureThe architecture of Teradata is a Massively Parallel processing architecture. The Teradata system has four components.
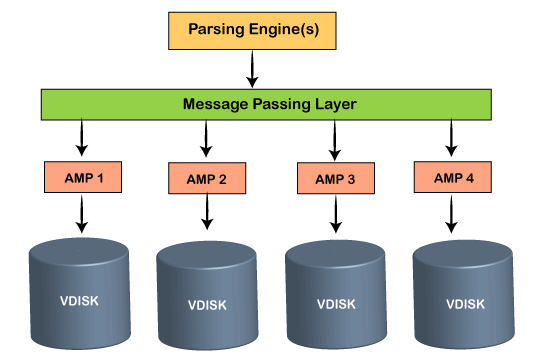
Based on the principal function of the Teradata system, the architecture can be categorized into two sections, such as:
Storage ArchitectureThe storage architecture consists of the above two components of the Teradata architecture. When the client runs queries to insert records, the Parsing engine sends the files to BYNET. BYNET retrieves the files and sends the row to the target AMP. AMP stores these records on its disks. 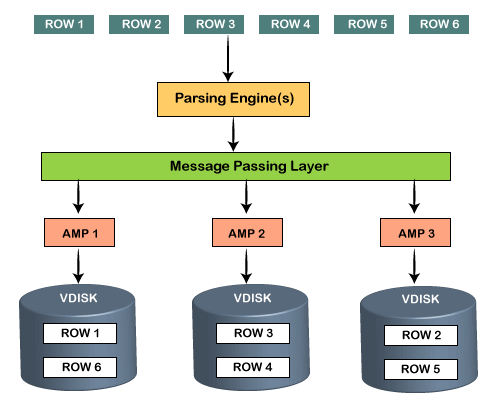
1. Parsing EngineWhen a user fires an SQL query, it first gets connected to the Parsing Engine. The processes, such as planning and distributing the data to AMPS, are done here. It finds out the best optimal plan for query execution. Parsing Engine performs the following processes, such as:
2. AMPAccess Module Processor is a virtual processor that connects to PE via BYNET. Each AMP has its disk and is allowed to read and write in its disk. This is called as 'SHARED NOTHING ARCHITECTURE'. When the query is fired, then Teradata distributes the rows of a table on all the AMPs. The AMP executes any SQL requests in the following steps, such as:
Retrieval ArchitectureThis architecture section consists of reaming two components of the Teradata architecture. When the client runs queries to retrieve records, the Parsing engine sends a request to BYNET. BYNET sends the retrieval request to appropriate AMPs. Then AMPs search their disks in parallel and identify the required records and forwards to BYNET. BYNET sends the records to Parsing Engine, which in turn will send to the client. 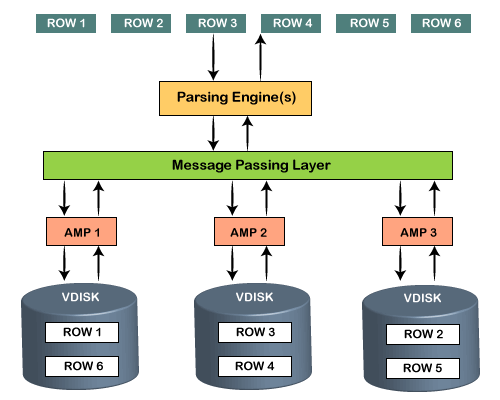
1. BYNETThe BYNET acts as a channel between PE and AMPs. There are two BYNETs in Teradata 'BYNET 0' and 'BYNET 1'.
2. DiskTeradata offers a set of Virtual Disks for each AMP. The storage area of each AMP is called as Virtual Disk or Vdisk. Here are the following steps for executing the query, such as: Step 1: The user raises the question which is sent to PE. Step 2: PE checks the security and syntax, and finds out the best optimal plan to execute the query. Step 3: The table rows are distributed on the AMP, and the data is retrieved from the disk. Step 4: The AMP sends back the data through BYNET to PE. Step 5: PE returns the data to the user.
Next TopicTeradata Installation
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








