| |

Teradata Hashing AlgorithmThe hashing algorithm is a piece of code that acts as a translation table. A row is assigned to a particular AMP based on the primary index value. Teradata uses a hashing algorithm to determine which AMP gets the row. The Teradata Database hashing algorithms are proprietary mathematical functions that transform an input data value of any length into a 32-bit value referred to as a rowhash, which is used to assign a row to an AMP. Whether the input is a combination of different column values, comes from differently-sized values from a variable-length column, or is composed of different data types, the hashing algorithm's output will always be a fixed size and format. It dealing with uniformly-sized row identifiers simplifies the database's effort during storing, aggregating, sorting, and joining rows. Following is a high-level diagram on the hashing algorithm. 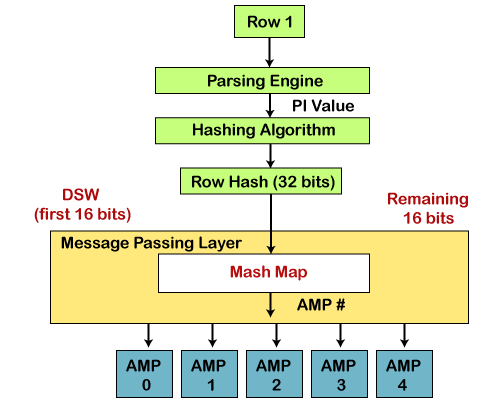
Here is the explanation of the above diagram, how to insert the data:
Hashing FunctionsTeradata SQL provides several functions that can be used to analyze the hashing characteristics of the existing indexes and candidate indexes. These functions are documented fully in SQL Functions, Operators, Expressions, and Predicates. There are four types of hashing functions available in the Teradata. 1. HASHROW: It describes hexadecimal rowhash value for an expression. The Query would give the same results if we ran again and again. The HASHROW function produces the 32-bit binary Row Hash that is stored as part of the data row. It returns maximum of 4,294,967,295 unique values. Syntax 2. HASHAMP: The HASHAMP function returns the identification number of the primary AMP for any Hash Bucket number. When no value is passed through the HASHAMP function, it returns a number less than the number of AMPs in the current system configuration. Syntax 3. HASHBUCKET: The HASHBUCKET function produces 16bit binary Hash Bucket used with the Hash Map to determine the AMP that store and retrieve the data row. The values range from 0 to 1,048,575, not counting the NULL as a possible result. Syntax 4. HASHBAKAMP: The HASHBAKAMP function returns the identification number of the Fallback AMP for any Hash Bucket number. Syntax Hash CollisionsThe Hash Collision is a situation in which the rowhash value for different rows is identical, making it difficult for a system to discriminate among the hash synonyms when one unique row is requested for retrieval from a set of hash synonyms. Minimizing Hash Collisions To minimize the Hash Collision problem, Teradata Database defines 4.2 billion hash values. The AMP software adds a system-generated 32-bit uniqueness value to the rowhash value. The resulting 64-bit value prefixed with an internal partition number is called the rowID. This value uniquely identifies each row in a system, making a scan to retrieve a particular row among several having the same rowhash a trivial task. A scan must check each of the rows to determine if it has the searched-for value and not another value with the same rowhash value. Hash MapsA hash map is a mechanism for determining which AMP a row is stored on, or, in the case of the Open PDE hash map, the destination AMP for a message sent by the Parser subsystem. Each cell in the map array corresponds to a hash bucket, and each hash bucket is assigned to an AMP. Hash map entries are maintained by the BYNET.
Next TopicTeradata Join Strategies
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








