| |

Teradata Join StrategiesTeradata Join Strategies are utilized by the optimizer to choose the minimum cost plan and better performance. The strategy will be chosen based on the available information to the optimizer, such as Table size, PI information, and Stats Information. Teradata joins strategies are the following types:
Merge Join StrategiesMerge Join method takes place when the join is based on the equality condition. Merge Join requires the joining rows to be on the same AMP. Rows are joined based on their row hash. Merge Join uses four different merge join strategies based on the redistribution to bring the rows to the same AMP. Strategy 1 The 1st merge join will utilize the Primary Index on both tables in the join condition. 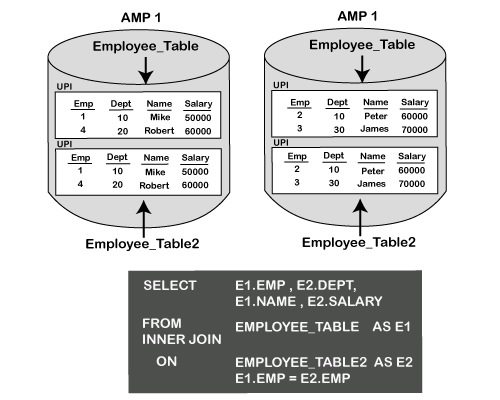
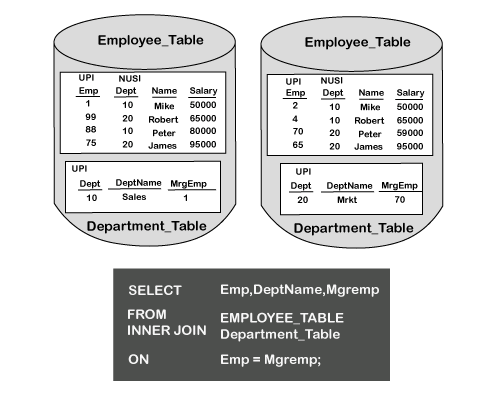
The inner join above focuses on returning all rows when there is a match between the two tables. The ON clause is essential because this join establishes the join (equality) condition. 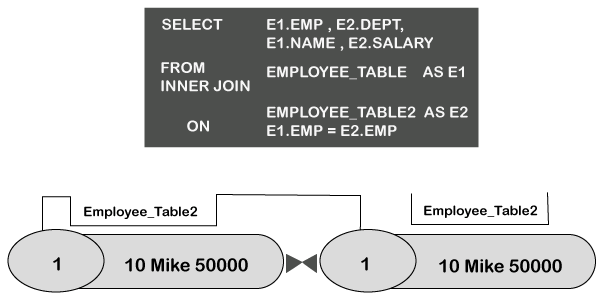
Each matching row is joined where Emp = Emp is stated from the ON Clause in the JOIN. EMP is the Primary Index for both tables. This first merge join type is extremely efficient because both columns in the ON clause are the Primary Indexes of their respective tables. When this occurs, NO data has to be moved into the spool, and the joins can be performed in what is called AMP LOCAL. Teradata can perform this join with rapid speed and fewer data to be moved to complete a join. Strategy 2 This strategy is used when a join is performed on a Primary Index column of one table to a non-primary indexed column of another table. 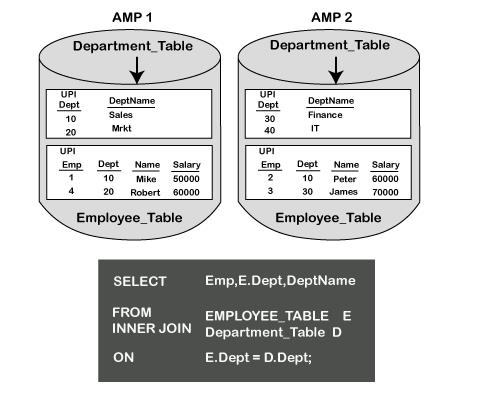
Two tables are being joined based on the DEPT column. In the department table, the Primary Index column is DEPT. The employee table has EMP as the Primary Index column. The primary objective is to bring the rows together from each table on the same AMPs. There are several options that the Teradata Optimizer could choose to complete this task, such as:
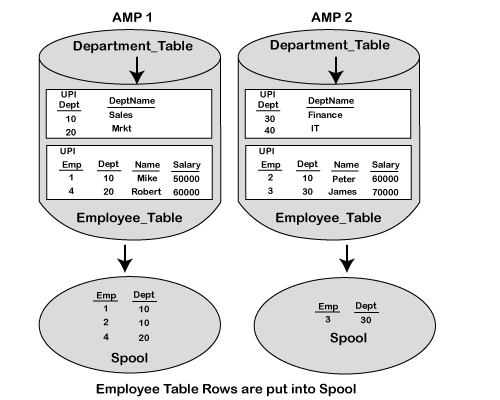
Strategy 3 This is used where neither table is being joined on the Primary Index of either table. In this case, Teradata will redistribute both tables into the spool and sort them by hash code. When we want to redistribute and sort by hash code, we merely hash the non-primary index columns and move them to the AMPs spool where they are sorted by hash. Once this is accomplished, then the appropriate rows are together in spool on all the AMPs. 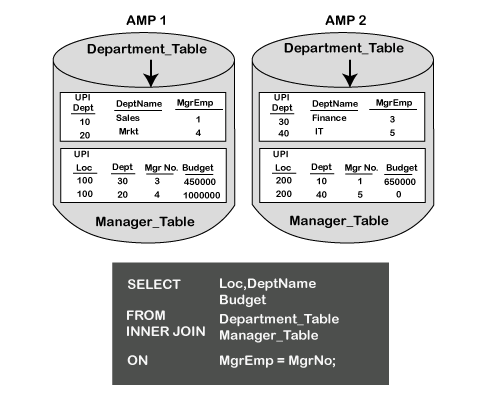
The Primary Index of the department table is DEPT, and the Primary Index for the manager table is LOC. In this case, both columns being utilized in this join equality are not part of the Primary Index columns. Rows from both tables will need to be rehashed and redistributed into SPOOL because neither column selected in the ON Clause is the Primary Index of the respective tables. Therefore, both tables are redistributed based on the ON clause columns. 
The next step in this process is to redistribute the rows and locate them to the matching AMPs. When this is completed, the rows from both tables will be located in two different spools. The rows in each spool will be joined together to bring back the matching rows. Merge Join Strategy 4 The fourth merge join strategy is called the big table - small table join. If one of the tables being joined is small, then Teradata may choose a plan that will duplicate the smaller table across all the AMPs. The key to this strategy is that regardless of the table is part of the Primary Index Column or not, Teradata could still choose to duplicate the table across all the AMPs. 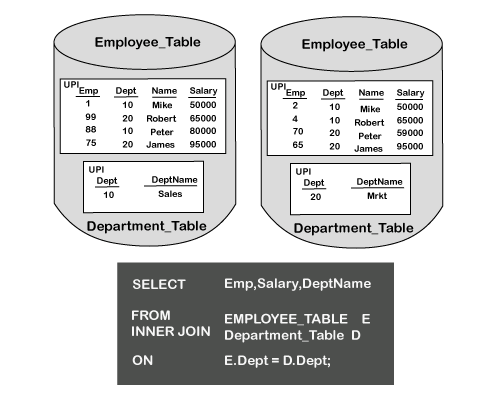
The two tables involved in the join are the Employee table and the Department table. The Dept column is the join equality that is making the match between the two tables. The DEPT column is the Primary Index Column in the Department table. The Employee table has the Emp column as the Primary Index. The Department table is small. To join these two tables together:

Nested JoinA nested join is designed to utilize a unique index type (Either Unique Primary Index or Unique Secondary Index) from one of the tables in the joint statement to retrieves a single row. Then it matches that row to one or more rows on the other table being used in the join. 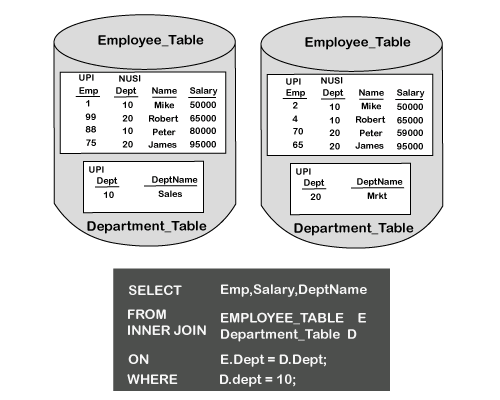
The nested join has the join equality (ON) condition based on the Dept column. The Dept column is the Primary Index Column on the department table. The Dept column is the Secondary Index Column in the employee table. The nested join can move a single row into the spool and then matching that row with another table that contains several matches. Analysis of this join statement indicates a new clause has been added to this statement. This is known as the WHERE option. When utilized, the WHERE option allows for a single row to be retrieved from a table. A nested join will always use a unique index to isolate that single record and then join that record to another table. The other table may use an index, or it may not. The utilization of indexes in join statements will improve performance and utilize fewer resources, as shown in the below diagram. 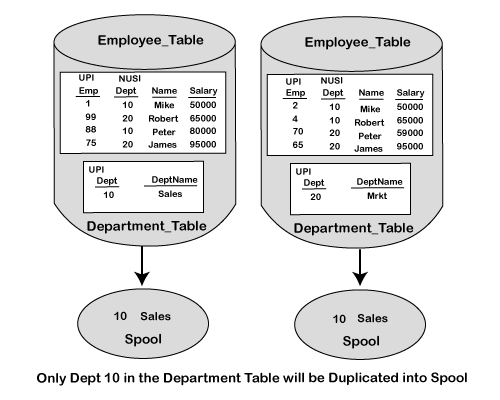
Since there is only one row in the department table with a match for department =10, which is based on the AND option in the join statement, the Teradata Optimizer will choose a path to move the department table columns into the spool and duplicate them across all the AMP. After completed, the matches will proceed with that single record (10 and SALES) to the second table, which did not move from the base AMP. Nested Joins are great in an OLTP Environment because of the usage of both Unique and Non-Unique Indexes. Row Hash JoinThe Hash Join is part of the Merge Join. The key to a Merge Join is based on equality condition, such as E.Dept = D.Dept in the ON clause of the join statement. A Hash Join can only occur if one or both of the tables on each AMP can fit entirely inside the AMP's memory. 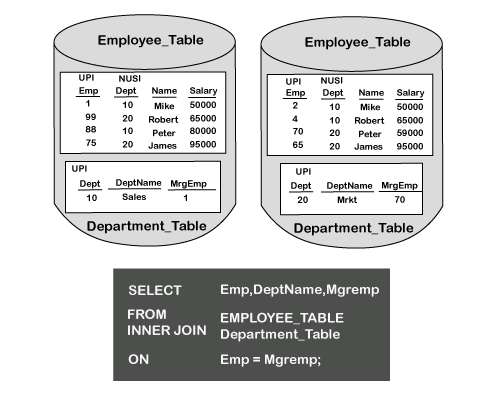
The Hash Join process is where the smaller table is sorted by row hash and duplicated on every AMP. Here the key is a smaller table that is required to be held entirely in each AMP's memory. Teradata will use the join column of the larger table to search for a match. The row hash join is extremely efficient because it eliminates the sorting, redistribution, and copying of the larger table into the spool. The rows that are duplicated into the AMP's memory yield increased performance because the rows never go into a spool. Rows that go into spool always have to involve disk activity. Product JoinsProduct Joins compare every row of one table to every row of another table. They are called product joins because they are a product of the number of rows in table one multiplied by the number of rows in table two. For example, if one table had six rows and the other had six rows, then the Product Join would compare 6 x 6 rows with a potential of 36 rows. Many times, product joins are major mistakes because all rows in both tables will be compared. Teradata tables have the potential to contain millions of rows. If a user accidentally writes a product, join against two tables that have 1 million rows each. The result set would return One Trillion Rows. To avoid a product join, check the syntax to ensure that the join is based on an EQUALITY condition. In the above example, the equality statement reads "WHERE EMP Like '_b%' because this clause is not based on a common domain condition between the two tables e.dept = d.dept, the result is a product join. Another cause of a product join is when aliases are not used after being established. So firstly, ensure the WHERE clause is not missing in the join syntax. Cartesian product JoinA Cartesian Product Join will join every row in one table to every row in another table. The only thing that decides the number of rows will be the total number of rows from both tables. If one table had 5 rows and another had 10 rows, then we will always get 50 rows returned. Most of the time, a Cartesian Product Join is a major problem because all rows in both tables will be joined. To avoid a Cartesian Product Join, check the syntax to ensure that the join is based on an EQUALITY condition. In the above example, the WHERE clause is missing because this clause is missing, a common domain condition between the two tables (e.dept = d.dept). Another cause of a product join is when aliases are not used after being established. Exclusion JoinExclusion Joins have one primary function. They exclude rows during a join. In the above example, the join utilizes the NOT IN statement. Exclusion joins are used for finding rows that don't have a matching row in the other table. Queries with the NOT IN operator are the types of queries that always provide exclusion joins results. In this case, this query will find all the employees who belong to department 10 who are NOT managers. These joins will always involve a Full Table Scan because Teradata will need to compare every record to eliminate rows that will need to be excluded. This type of join can be resource-intensive if the two tables in this comparison are large. The biggest problem with the Exclusion Joins is when the NOT IN statement is used because the NULLs are considered unknowns, so the data returned in the answer will be NULLs. There are two ways to avoid this problem:
Next TopicTeradata Views
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








