| |

What is Databrick?This post serves as a comprehensive introduction to Azure Databricks for newcomers. We'll learn the fundamentals of Databricks in Azure, as well as how to create it via the Azure portal and the different components and internals that go with it. Systems are dealing with petabytes or even petabytes of data, which is still rising at an exponential rate. Big data is all around us, coming from various sources such as social media sites, sales, consumer data, transactional data, and so on. And, in my opinion, this data will only be valuable if we can handle it both interactively and quickly. Apache Spark is a popular framework for large data analysis and is an open-source, rapid cluster computing system. This framework helps to improve performance by processing data in parallel. It's written in Scala, a high-level programming language that also supports Python, SQL, Java, and R APIs. What is Azure Databricks and what does it have to do with Spark?Simply put, Databricks is a Microsoft Azure implementation of Apache Spark. Spark clusters, which are completely managed, are used to process big data workloads and also aid in data engineering, data exploration, and data visualization utilizing machine learning. While working on databricks, I discovered that this analytic platform is incredibly developer-friendly and adaptable, with APIs such as Python, R, and others that are simple to use. To further illustrate, imagine we've constructed a data frame in Python. Use case of Databrick?For a variety of reasons, Databricks adoption is becoming increasingly important and relevant in the big data world. Apart from supporting many languages, this service allows us to quickly interact with a variety of Azure services such as Blob Storage, Data Lake Store, SQL Database, and BI tools such as Power BI and Tableau. It's an excellent collaboration platform that allows data professionals to share clusters and workspaces, resulting in increased productivity. A few very important features of the Azure Databrick are -
Create an Azure Databricks serviceTo create Databricks, we'll need an Azure subscription, just like any other Azure resource. We can have a free subscription by going to the azure website and get a trail for free. Sign in to the Azure portal and search for databricks in the Create a resource box: 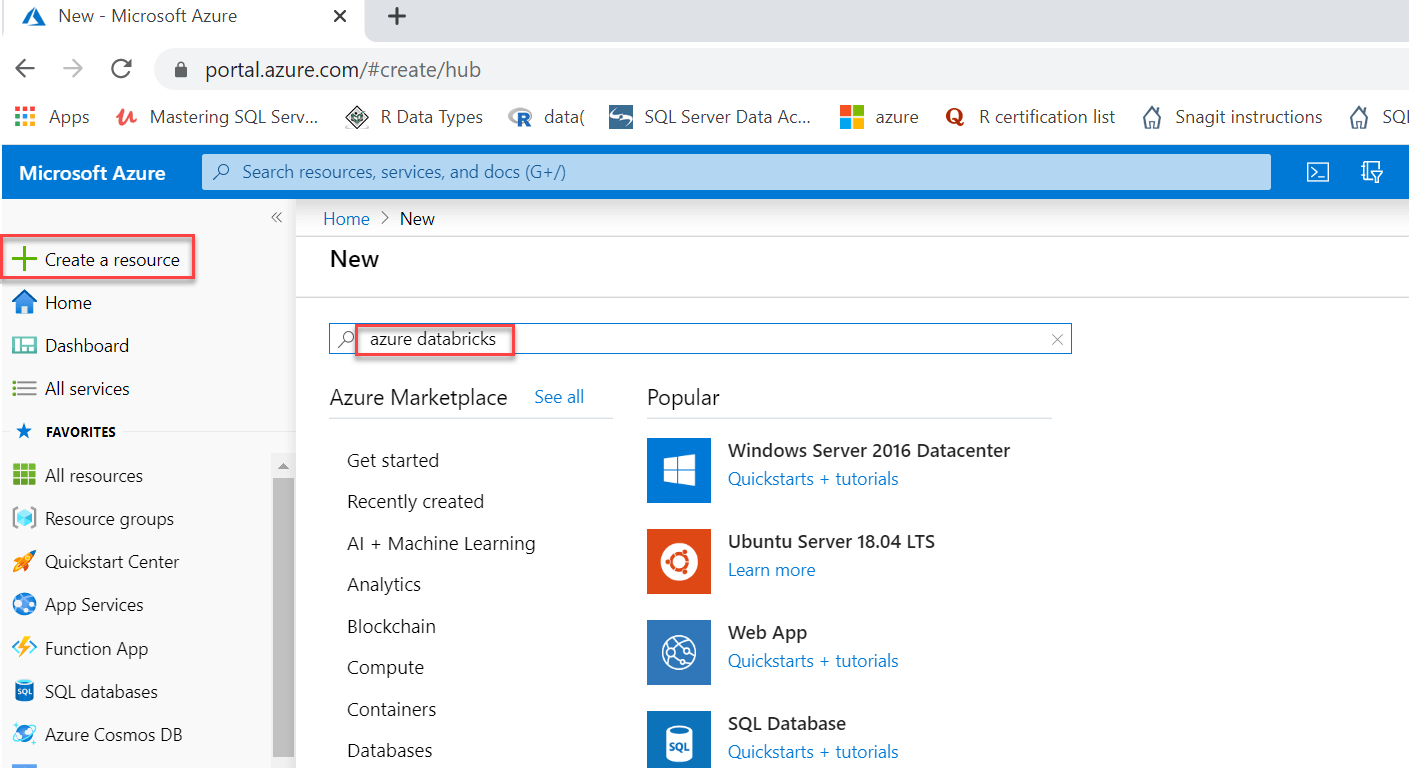
As indicated below, click the Create button: 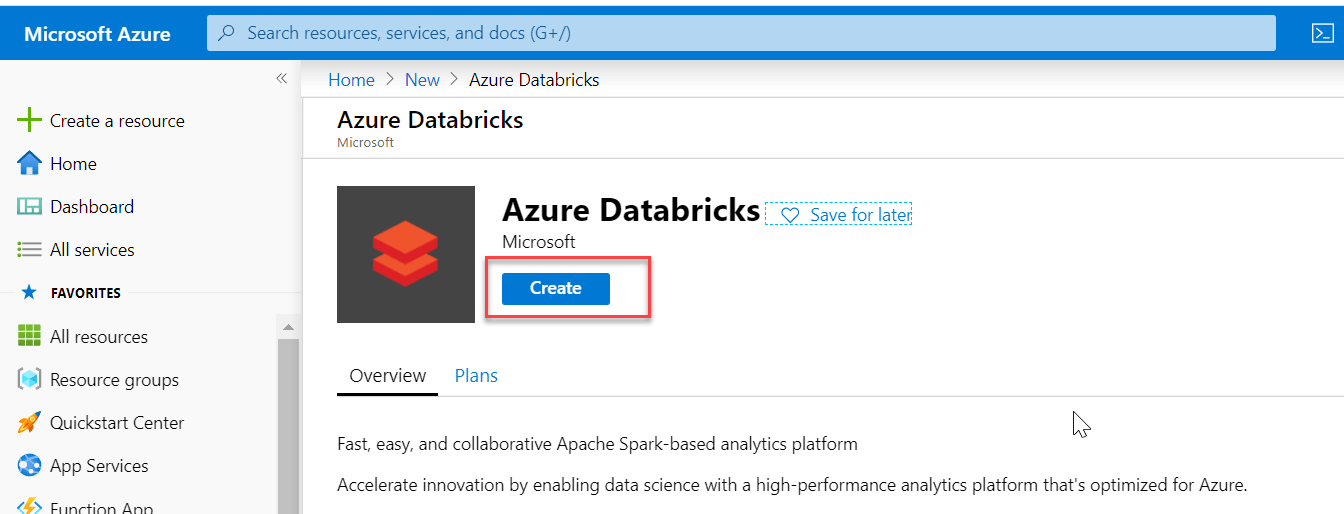
We will be directed to the next screen. We need to enter the following information:
And then after that click on the Create button to make this service: 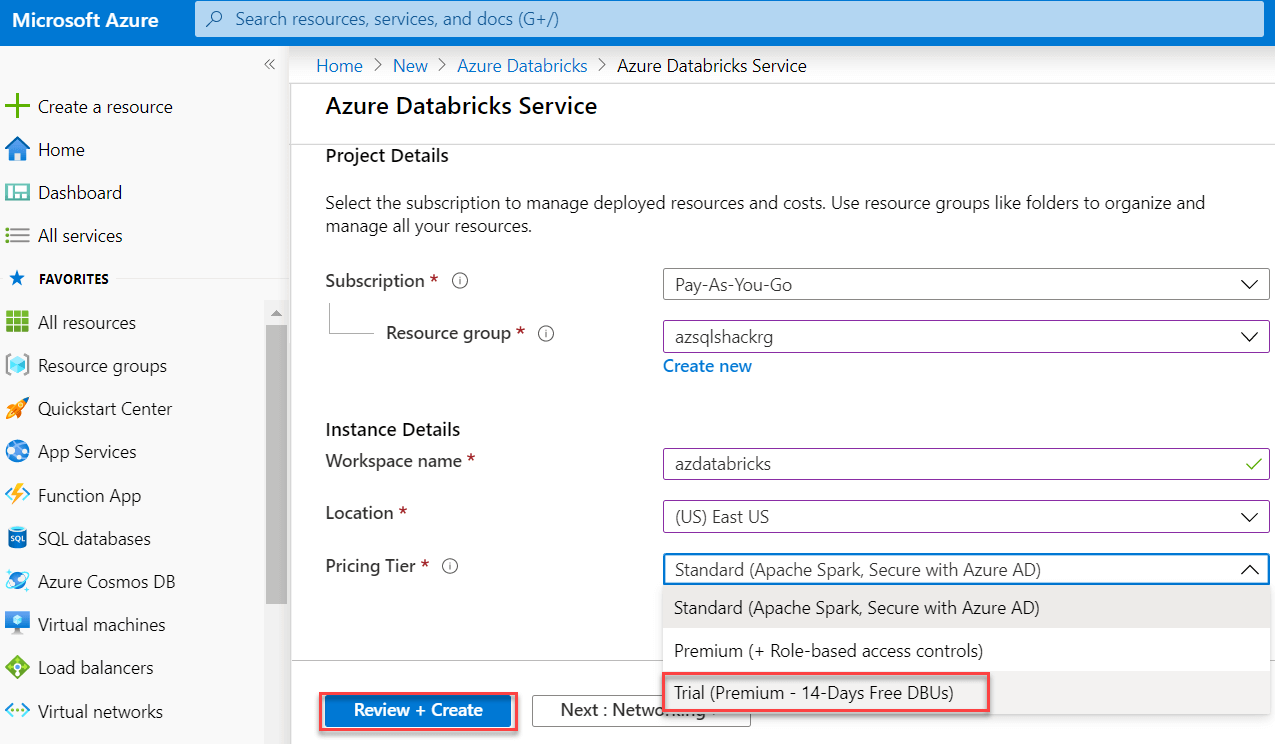
After it's been created, go to the notification tab and select "Go to resource" to open the service we just established: 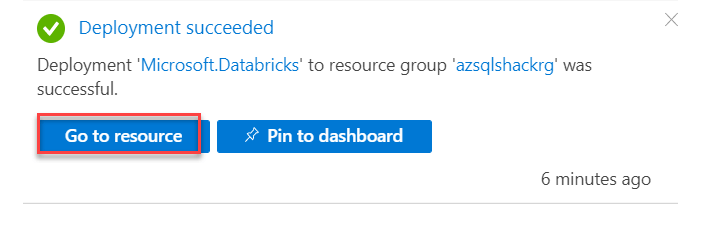
On the portal, we may see information about our databricks service such as the URL, price details, and so on. To visit the Azure Databricks site, click Launch Workspace; this is where we will create a cluster: 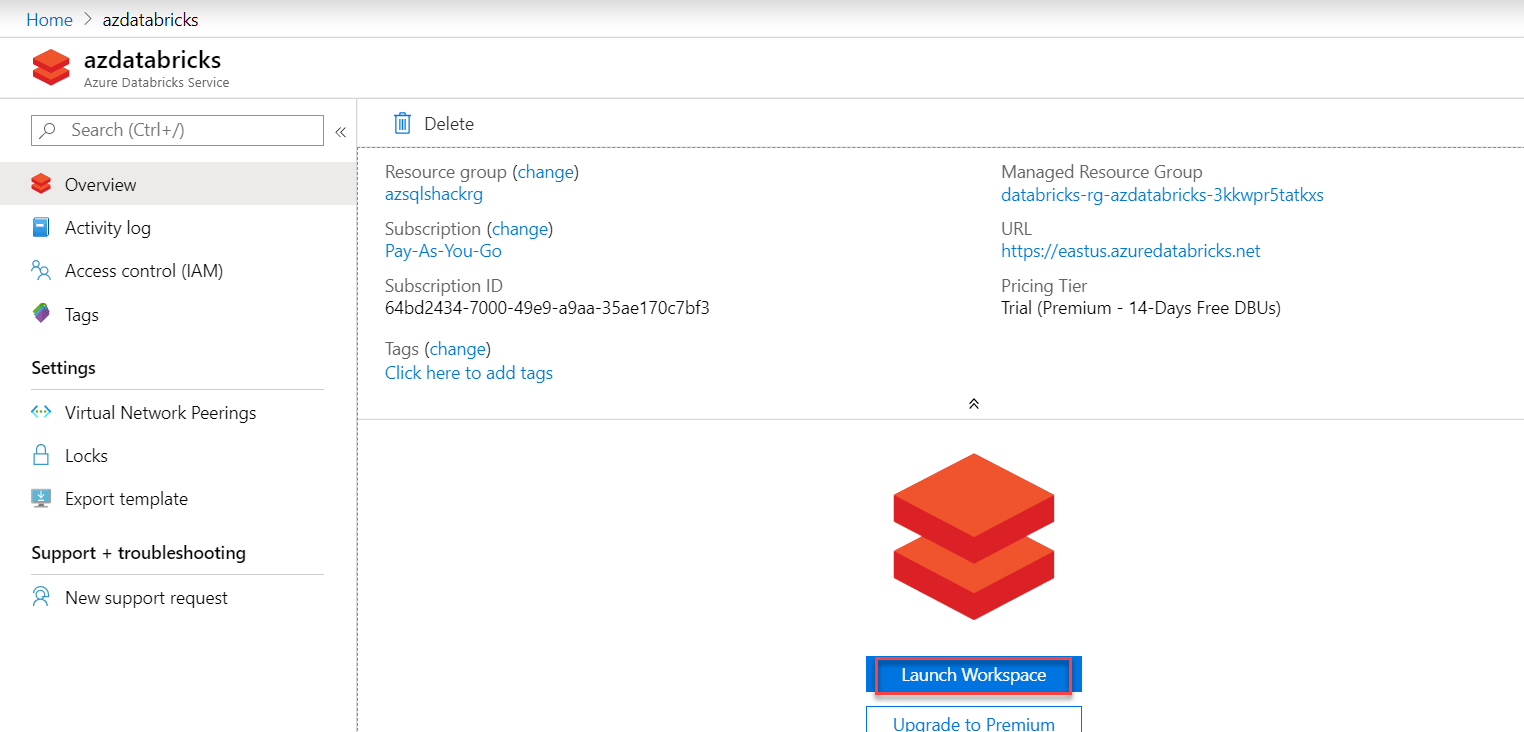
To use Databricks Workspace, we'll need to sign in again. The Databricks home page of the Databricks portal is seen in the screenshot below. We may create notebooks and manage our papers on the Workspace tab. We can construct tables and databases using the Data tab below. We can also use Cassandra, Kafka, Azure Blob Storage, and other data sources. In the vertical list of options, select Clusters: 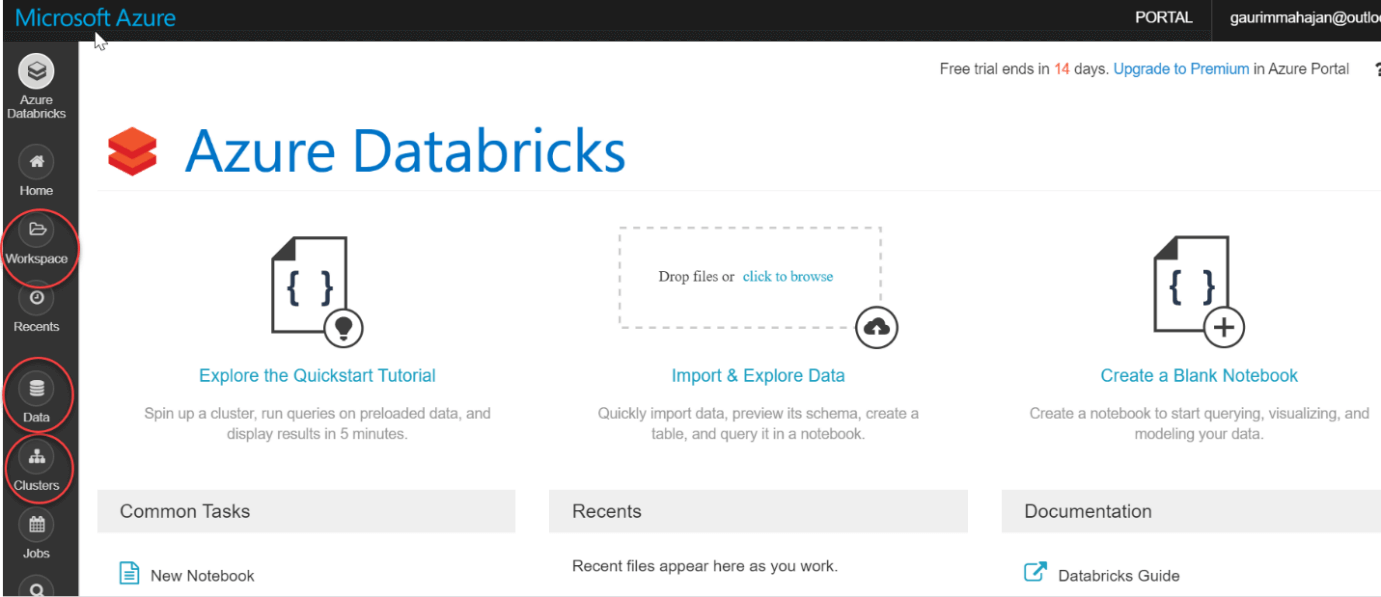
Now, here create a Spark cluster, for more detail click have a look on the image below. Databricks are developed in a fully managed Apache Spark environment. And they consist of a very special feature of auto-scaling which is totally based on business needs. On the Clusters page, go to the bottom and click Create Cluster: 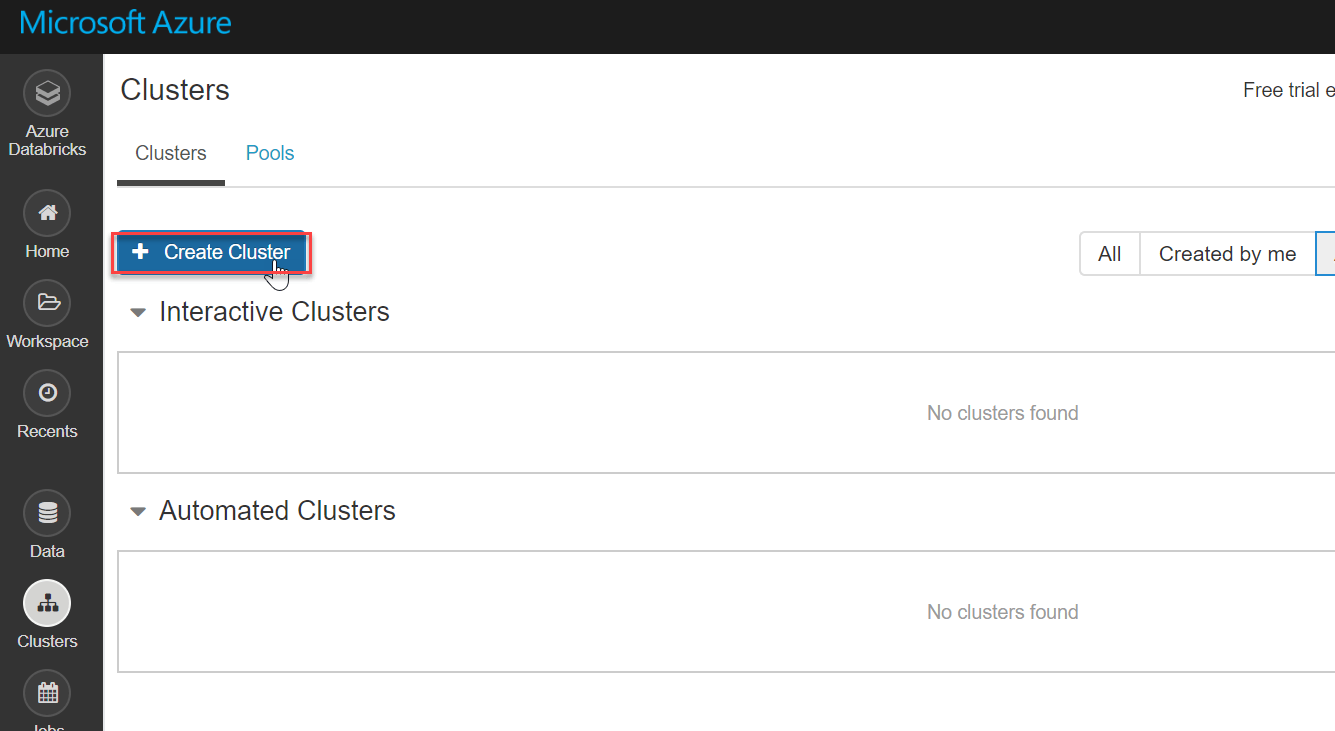
Several setup options for creating a new databricks cluster are shown in the following screenshot. The setting that I am using for the creation of the cluster are -
I'm not enabling auto-scaling because this is a demonstration, and I'm also not activating the option to terminate this cluster if it is inactive for 120 minutes. Finally, on the New Cluster page, click the Create Cluster button to start it up: 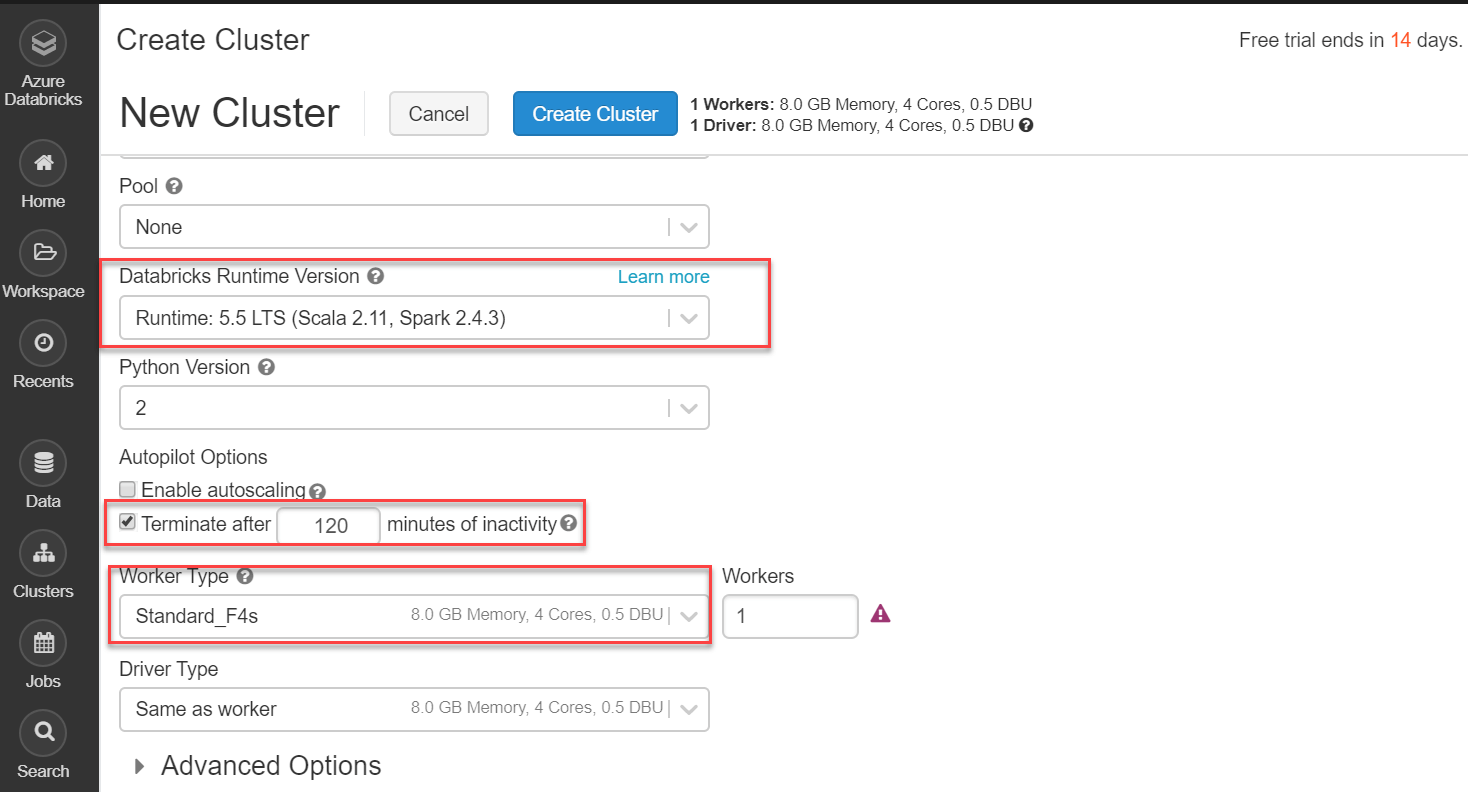
Basically, we may set up our cluster as we like. On this Microsoft reference page, many cluster configurations, including Advanced Options, are detailed in great depth. The cluster's status is shown as Pending in the screenshot below. As it is being created in the cloud infrastructure ,it will still take a bit of time to get created. 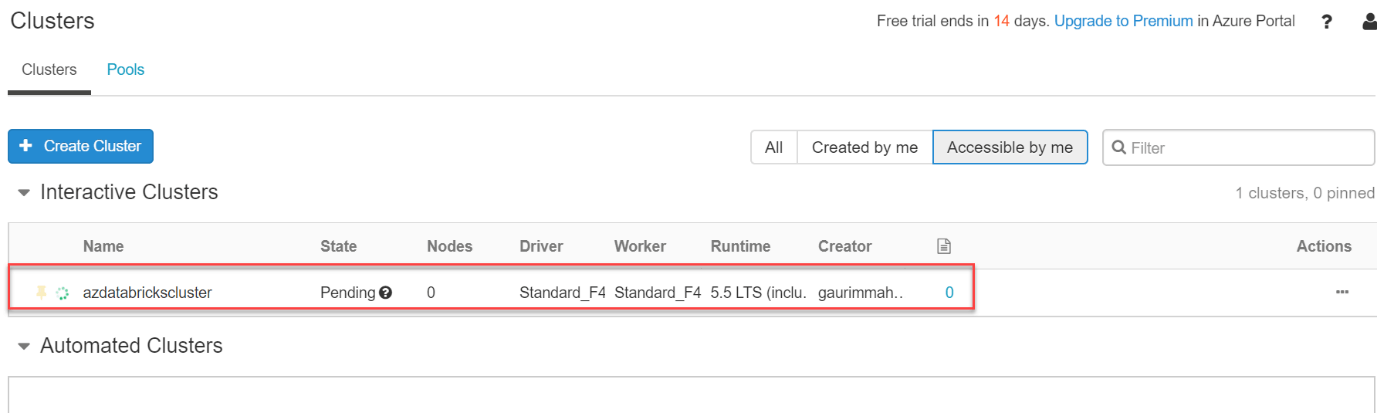
Wohh! We have successfully created a cluster which is up and running. 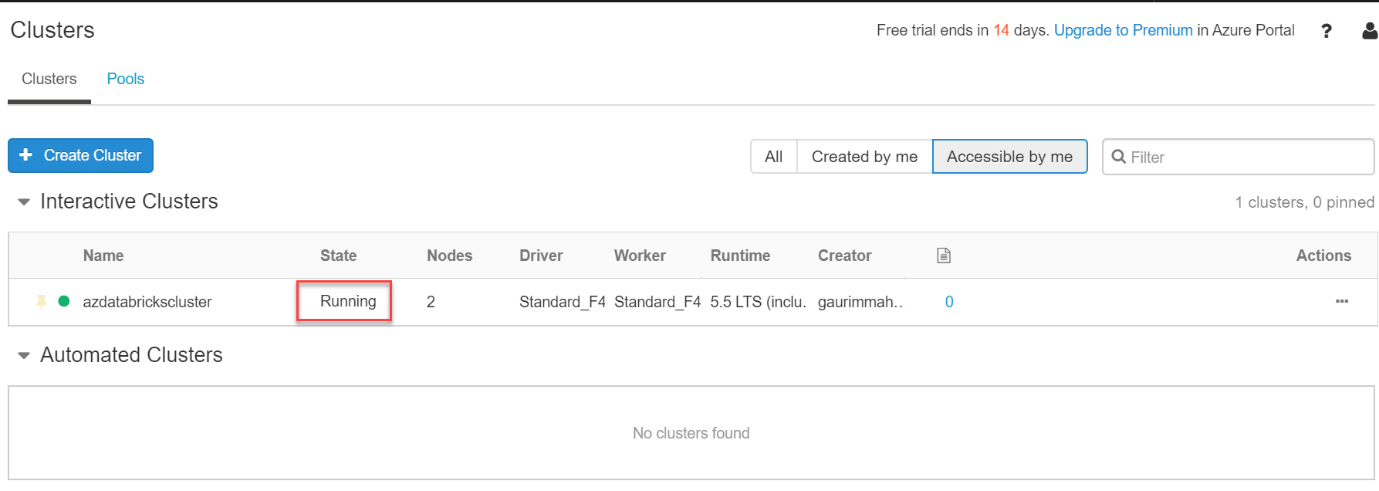
Databricks is a fully managed service by default, which means that the cluster's resources are deployed to a locked resource group, databricks-rg-azdatabricks-3... as seen in the diagram below azdatabricks, VM, Disk, and other network-related services are generated for the Databricks Service: 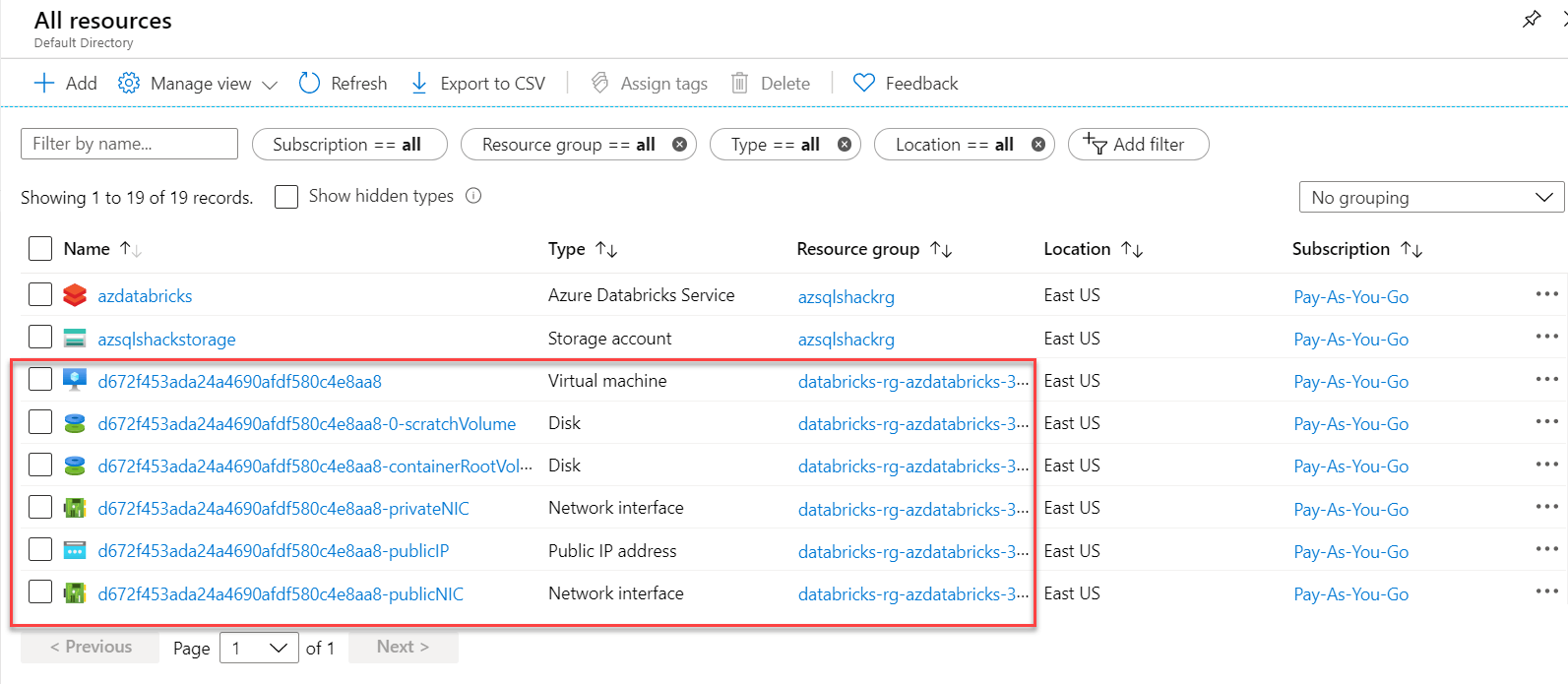
In the predefined Resource group, we'll also see that a dedicated Storage account has been deployed: 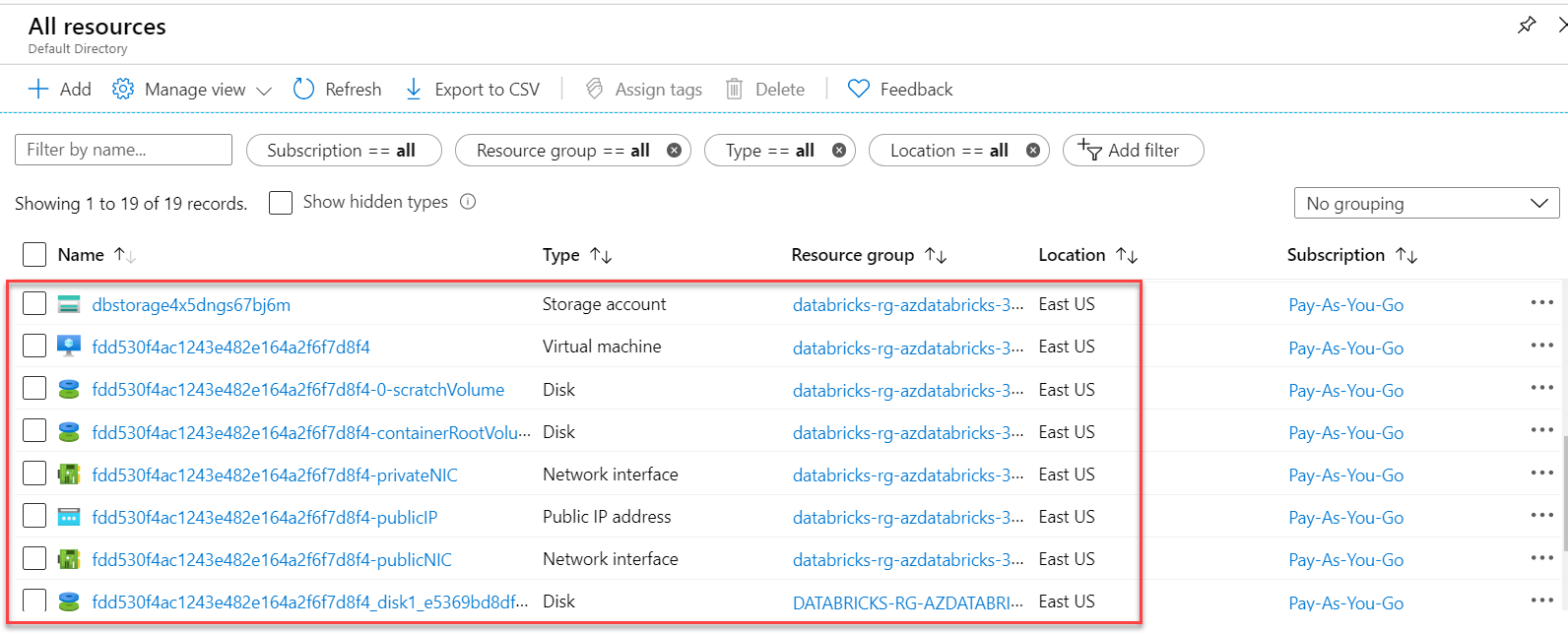
Create a notebook in the Spark cluster In the Spark cluster, a notebook is a web-based interface that allows us to run code and visualizations in a variety of languages. We can create notebooks and run Spark jobs after the cluster is up and running. Now we must click on the Create button which is present under the Workspace tab which is on the left vertical menu bar, then we must click on the select Notebook option. For reference have a look at the image below: 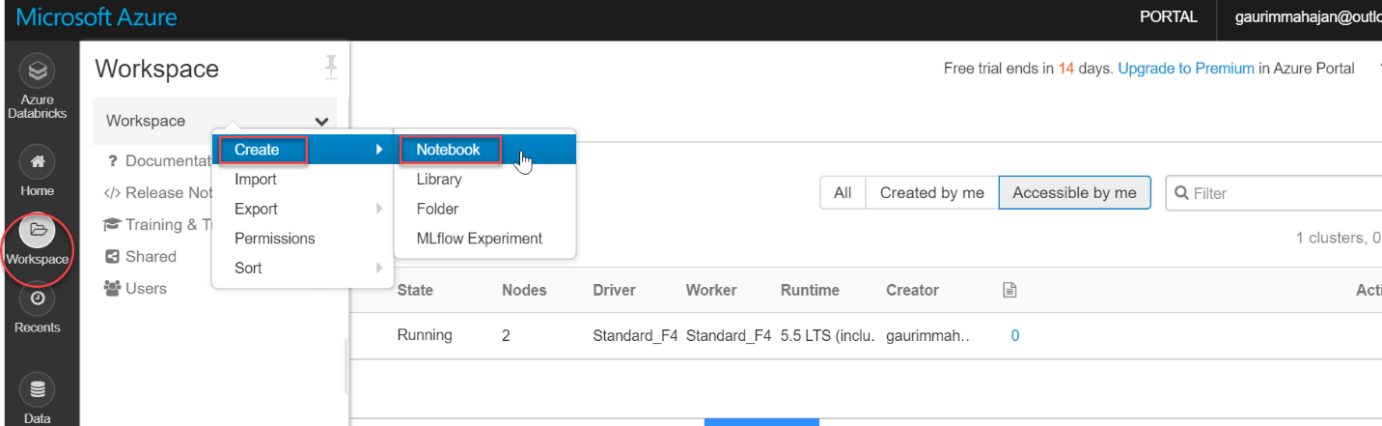
Now we need to give a name for the notebook and we must always give a proper name so that anyone working on it must get a proper understanding of the notebook just by reading its name. Now we have to select a language Suc gh as Python, Scala, SQL, R and the cluster name in the Create Notebook dialog box, then we have to click on the Create button. This will add a notebook to the Spark cluster that we have just created: 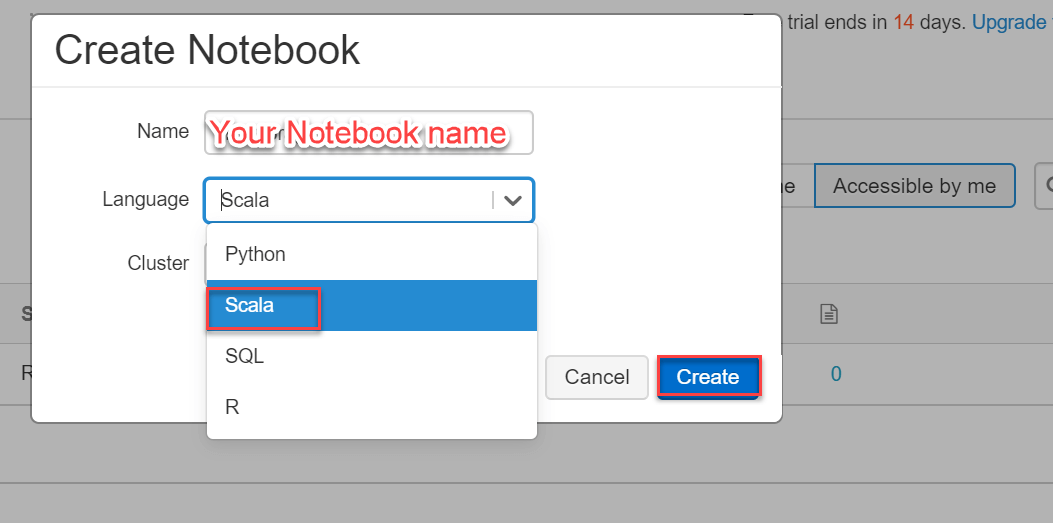
I'm going to end this topic here because we'll be looking at other aspects of Databricks Notebooks in my next articles. ConclusionHere, we've attempted to explain the fundamentals of Azure Databricks in the most understandable manner possible. We tried creating a cluster in the easiest manner possible. This tutorial is intended to assist novices in learning the foundations of Databricks in Azure.
Next TopicWhy is PowerShell Used
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








