| |

Data Mesh - Rethinking Enterprise Data ArchitectureIn this age of world, where self-service business intelligence is ruling the field, every business tries to establish itself as an information-driven business. Many businesses are aware of the numerous benefits realized through leverage to make informed decisions. It is the ability to offer customers superior, highly personalized services while also reducing costs and capital being the most appealing. 
However, businesses are still confronted with a variety of challenges in transitioning into a data-driven strategy and making the most of its full potential. While transferring legacy systems and avoiding legacy culture and prioritizing the management of data in an ever-changing set of business needs are all legitimate challenges, the architecture of the data platform also is a major obstruction. Siloed data warehouses and data lake architectures are limited in their capacities to support an instantaneous stream of data. In turn, they undermine organizations' objectives of scalability and democratization. However, Data Mesh - a revolutionary, new paradigm of architecture that has caused quite the buzz - could help give your data-related goals an opportunity to breathe new life into your data. Let's look a bit closer at the details of Data Mesh and how it could change the way we think about big Data management. What is Data Mesh?Data Mesh essentially refers to breaking down siloes and data lakes into smaller, decentralized parts. Similar to the transition from monolithic software to microservices-based architectures in software development. Data Mesh can be described as a data-centric form of microservices. 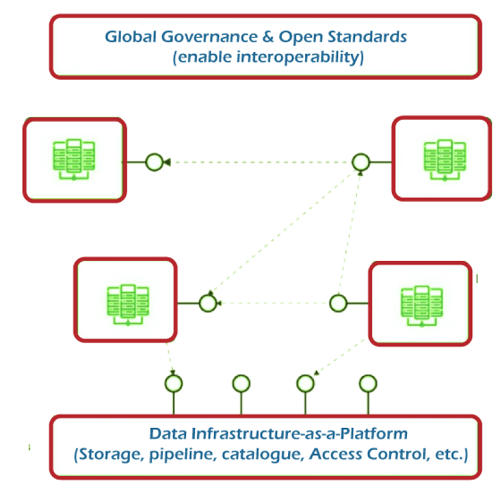
The term was initially defined in the late 1990s by ThoughtWorks Consultant Zhamak Dehghani as a kind structure for data platforms designed to take advantage of the all-encompassing nature of enterprise data by utilizing a self-service structured, domain-oriented structure. As an innovative idea in architecture and organization, Data Mesh challenges the common belief that large data needs to be centralized to maximize its potential for analysis. If all data isn't stored in one location and centrally managed in order to maximize its full value. In a 180-degree deviation from this old-fashioned belief, Data Mesh claims that big data can be a catalyst for the development of new technologies only if it's distributed to domain owners, which then offer data as a product. To make this possible for this, a fresh version of federated governance needs to be adopted via automated processes to facilitate interoperability among domain-oriented products. The democratization in the use of information is the primary foundation upon which the idea Data Mesh was developed. Data Mesh rests, and it can't be accomplished without decentralization, interoperability, and prioritizing the users the experience. As an architectural concept, Data Mesh holds immense potential for enabling analytics on a large scale by offering access to a growing and fast-growing diverse domain set. Particularly in scenarios that increase consumption like machine learning, analytics, or the development and deployment of data-centric apps. In its essence, Data Mesh seeks to address the weaknesses of traditional platforms, which led to the development of central data lakes or warehouses. Contrasting with monolithic data handling infrastructures that limit the consumption, storage, and processing of data is restricted to a single data lake, Data Mesh supports data distribution to specific domains. The approach of the data-as-a product allows people in different areas to manage the data processing pipelines of their respective domains on their own. The tissue that connects these domains, as well as the data assets that are associated with them, provides an interoperability layer that ensures a consistent format and standard for data. The various pockets of data are connected and joined by the mesh. Thus, the term. Problems that Data Mesh Seeks to Fix: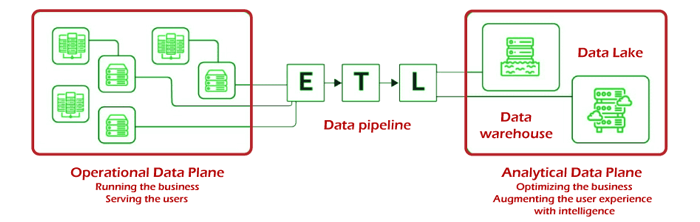
As previously mentioned, the limitations of the traditional data structures have proven to be an important obstruction in businesses' efforts to make the most of the data available to their disposal to make tangible gains in improving business practices and processes. The main challenge is the transformation of massive amounts of data into savvy and actionable information. Data Mesh addresses these concerns by addressing the following obvious flaws in the traditional approach to managing big data:
Three Key Components of Data MeshData Mesh Data Mesh requires different elements to work seamlessly - Data infrastructures, sources of data, and pipelines that are domain-oriented. Each of these components is essential to ensure interoperability, observability, and management and ensure standards that are domain-neutral in the data mesh design. The following elements play an important role in assisting Data Mesh to meet those standards:
Four Core Principles and Logical Architecture of Data MeshData Mesh is a paradigm that is based on four core principles. Each of them is intuitively designed to address the numerous challenges that arise from the traditional centralized approach towards big data management as well as data analysis. This is a review of what these fundamental principles refer to: 1. Domain-oriented Decentralized Data Ownership and Architecture:The core of the project is that Data Mesh seeks to decentralize the responsibility for data distribution to the people who work closely with it in hopes of scalability and continuous execution of any modifications. The decomposition and decentralization of data are accomplished by reshaping the data ecosystem, which includes metadata, analytical data, and the underlying computations. Because most companies today are decentralized in accordance with the areas they work within, the decomposition of data is performed on the same line. This is a way to localize the results of change and evolution with respect to the limited context of a particular domain. This is why it's important to create the best system for data ownership distribution. 2. Data-as-a-product:One of the biggest problems with monolithic data structures is the significant cost and difficulty in identifying, trusting, interpreting the importance of using high-quality data. The problem could have been exacerbated with Data Meshes considering an increase in the number of data domains had it not been addressed from the beginning. The principle of data as a product was viewed as a viable solution to solving the problems of old data silos as well as their data quality. In this model, analytical data is treated as a product, and those who utilize this data are considered customers. Making use of capabilities like accessibility, understanding, security, and trustworthiness is essential to use data as an item. Therefore, it is an essential element to Data Mesh implementation. 3. Self-Serve Data Infrastructure as a Platform:Establishing, deploying, monitoring, accessing, and managing data as a product requires a large infrastructure and the right skills to provide it. Replicating these resources for each domain created using the Data Mesh approach is not feasible. Furthermore, multiple domains may have access to the identical collection of data. To prevent duplication of efforts and resources, a high-level abstraction of infrastructure must be required. This is where the self-serve infrastructure for data as a platform becomes relevant. It's an extension of the current delivery platforms required to operate and monitor various services. Self-serve data platforms comprise tools that are able to support workflows of domain developers with little knowledge and expertise. However, it has to be able to reduce the costs of creating data products. 4. Federated Computational Governance:Data Mesh entails a distributed system that is self-contained and designed, and developed by teams of independent experts. To reap the maximum benefit from this type of architecture, interoperability between different products is essential. The model of federated computational governance provides exactly that. An association of data domains and platform product owners is given the power to make decisions as they work within a set of globally defined rules. This results in a healthy interoperability ecosystem. Why use Data Mesh?As of now, the majority of companies have benefited from single data lakes or data warehouses as part of a larger data infrastructure to satisfy their requirements for business intelligence. These solutions are implemented as well as managed and maintained by a tiny group of specialists who typically have to deal with massive technical debts. This results in a data team struggling to keep pace with increasing demands from the business, a gap between data producers and data users, and an increasing resentment with data users. A decentralized structure like Data Mesh blends the best of both worlds - central databases and decentralized data domains, along with independent pipelines to provide an efficient and sustainable alternative. Data Mesh Data Mesh is capable of eliminating all the flaws of data lakes by facilitating greater freedom and independence when it comes to the management of data. This opens up more opportunities for experimentation with data and ingenuity because the burden of data management is taken away from the hands of a few experts. In the same way, the self-serve platform provides possibilities for a more general and automated approach to data standardization and sharing and collection of data. In the end, Data Mesh's advantages Data Mesh translate into an unquestionably competitive advantage over traditional data structures. To Mesh or Not to Mesh - Which is the Right Choice for Us?In light of these numerous benefits, an organization should be looking to take advantage of Data Mesh. Data Mesh architecture for big data management. Is it, however, the best option for you? A simple method to figure out how to determine the Data Mesh score based on the quality of the data as well as the number of data domains as well as data teams, their size, and the bottlenecks that exist in data engineering and governance methods. The more score you have, the higher your score, the more complicated your infrastructure for data and, consequently, the greater the requirement for Data Mesh. ConclusionTechnology-related compatibility is among the most important aspects to be considered by any company's efforts to adopt and implement the Data Mesh-based approach to managing data. To fully embrace the Data Mesh architecture effectively, companies must restructure the data platform, rethink the roles of the domain owners and overhaul their structures in order to make the ownership of data products possible, as well as transition to treat their data analysis as an item. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








