| |

Data Science Tutorial for BeginnersData Science has become the most demanding job of the 21st century. Every organization is looking for candidates with knowledge of data science. In this tutorial, we are giving an introduction to data science, with data science Job roles, tools for data science, components of data science, application, etc. So let's start, 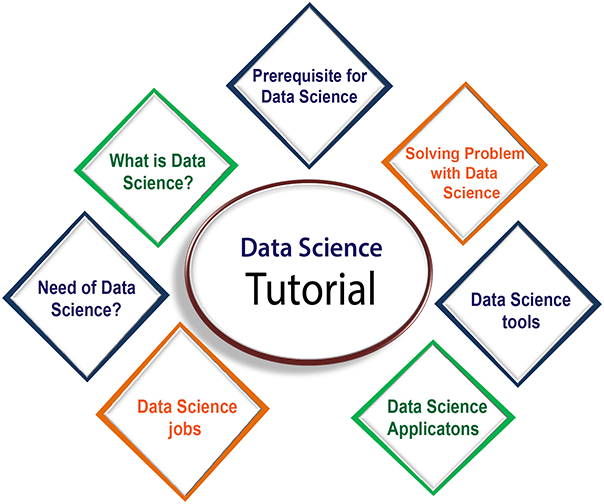
What is Data Science?Data science is a deep study of the massive amount of data, which involves extracting meaningful insights from raw, structured, and unstructured data that is processed using the scientific method, different technologies, and algorithms. It is a multidisciplinary field that uses tools and techniques to manipulate the data so that you can find something new and meaningful. Data science uses the most powerful hardware, programming systems, and most efficient algorithms to solve the data related problems. It is the future of artificial intelligence. In short, we can say that data science is all about:
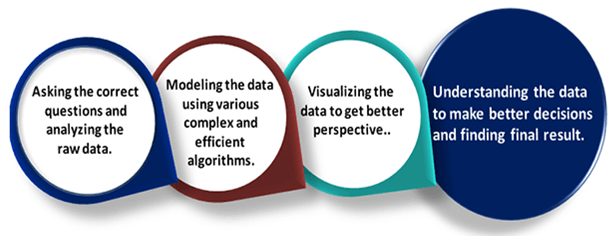
Example:Let suppose we want to travel from station A to station B by car. Now, we need to take some decisions such as which route will be the best route to reach faster at the location, in which route there will be no traffic jam, and which will be cost-effective. All these decision factors will act as input data, and we will get an appropriate answer from these decisions, so this analysis of data is called the data analysis, which is a part of data science. Need for Data Science:
Some years ago, data was less and mostly available in a structured form, which could be easily stored in excel sheets, and processed using BI tools. But in today's world, data is becoming so vast, i.e., approximately 2.5 quintals bytes of data is generating on every day, which led to data explosion. It is estimated as per researches, that by 2020, 1.7 MB of data will be created at every single second, by a single person on earth. Every Company requires data to work, grow, and improve their businesses. Now, handling of such huge amount of data is a challenging task for every organization. So to handle, process, and analysis of this, we required some complex, powerful, and efficient algorithms and technology, and that technology came into existence as data Science. Following are some main reasons for using data science technology:
Data science Jobs:As per various surveys, data scientist job is becoming the most demanding Job of the 21st century due to increasing demands for data science. Some people also called it "the hottest job title of the 21st century". Data scientists are the experts who can use various statistical tools and machine learning algorithms to understand and analyze the data. The average salary range for data scientist will be approximately $95,000 to $ 165,000 per annum, and as per different researches, about 11.5 millions of job will be created by the year 2026. Types of Data Science JobIf you learn data science, then you get the opportunity to find the various exciting job roles in this domain. The main job roles are given below:
Below is the explanation of some critical job titles of data science. 1. Data Analyst: Data analyst is an individual, who performs mining of huge amount of data, models the data, looks for patterns, relationship, trends, and so on. At the end of the day, he comes up with visualization and reporting for analyzing the data for decision making and problem-solving process. Skill required: For becoming a data analyst, you must get a good background in mathematics, business intelligence, data mining, and basic knowledge of statistics. You should also be familiar with some computer languages and tools such as MATLAB, Python, SQL, Hive, Pig, Excel, SAS, R, JS, Spark, etc. 2. Machine Learning Expert: The machine learning expert is the one who works with various machine learning algorithms used in data science such as regression, clustering, classification, decision tree, random forest, etc. Skill Required: Computer programming languages such as Python, C++, R, Java, and Hadoop. You should also have an understanding of various algorithms, problem-solving analytical skill, probability, and statistics. 3. Data Engineer: A data engineer works with massive amount of data and responsible for building and maintaining the data architecture of a data science project. Data engineer also works for the creation of data set processes used in modeling, mining, acquisition, and verification. Skill required: Data engineer must have depth knowledge of SQL, MongoDB, Cassandra, HBase, Apache Spark, Hive, MapReduce, with language knowledge of Python, C/C++, Java, Perl, etc. 4. Data Scientist: A data scientist is a professional who works with an enormous amount of data to come up with compelling business insights through the deployment of various tools, techniques, methodologies, algorithms, etc. Skill required: To become a data scientist, one should have technical language skills such as R, SAS, SQL, Python, Hive, Pig, Apache spark, MATLAB. Data scientists must have an understanding of Statistics, Mathematics, visualization, and communication skills. Prerequisite for Data ScienceNon-Technical Prerequisite:
Technical Prerequisite:
Difference between BI and Data ScienceBI stands for business intelligence, which is also used for data analysis of business information: Below are some differences between BI and Data sciences:
Data Science Components: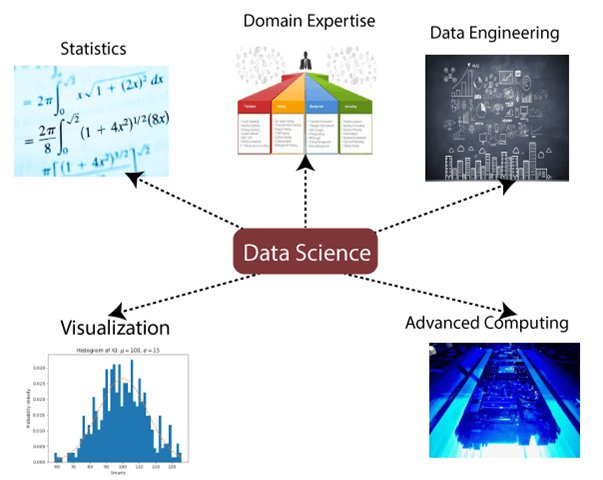
The main components of Data Science are given below: 1. Statistics: Statistics is one of the most important components of data science. Statistics is a way to collect and analyze the numerical data in a large amount and finding meaningful insights from it. 2. Domain Expertise: In data science, domain expertise binds data science together. Domain expertise means specialized knowledge or skills of a particular area. In data science, there are various areas for which we need domain experts. 3. Data engineering: Data engineering is a part of data science, which involves acquiring, storing, retrieving, and transforming the data. Data engineering also includes metadata (data about data) to the data. 4. Visualization: Data visualization is meant by representing data in a visual context so that people can easily understand the significance of data. Data visualization makes it easy to access the huge amount of data in visuals. 5. Advanced computing: Heavy lifting of data science is advanced computing. Advanced computing involves designing, writing, debugging, and maintaining the source code of computer programs. 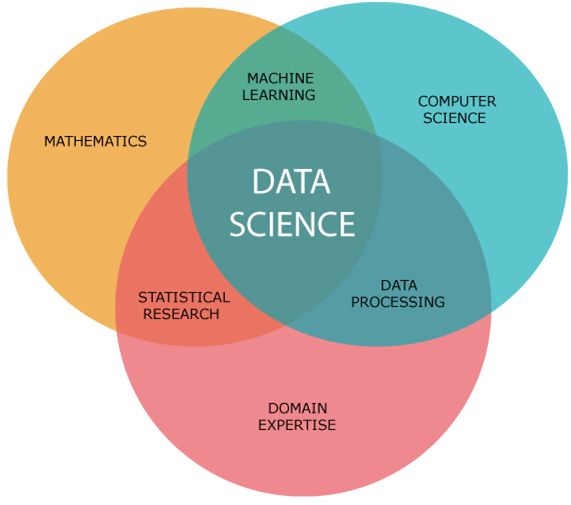
6. Mathematics: Mathematics is the critical part of data science. Mathematics involves the study of quantity, structure, space, and changes. For a data scientist, knowledge of good mathematics is essential. 7. Machine learning: Machine learning is backbone of data science. Machine learning is all about to provide training to a machine so that it can act as a human brain. In data science, we use various machine learning algorithms to solve the problems. Tools for Data ScienceFollowing are some tools required for data science:
Machine learning in Data ScienceTo become a data scientist, one should also be aware of machine learning and its algorithms, as in data science, there are various machine learning algorithms which are broadly being used. Following are the name of some machine learning algorithms used in data science:
We will provide you some brief introduction for few of the important algorithms here, 1. Linear Regression Algorithm: Linear regression is the most popular machine learning algorithm based on supervised learning. This algorithm work on regression, which is a method of modeling target values based on independent variables. It represents the form of the linear equation, which has a relationship between the set of inputs and predictive output. This algorithm is mostly used in forecasting and predictions. Since it shows the linear relationship between input and output variable, hence it is called linear regression. 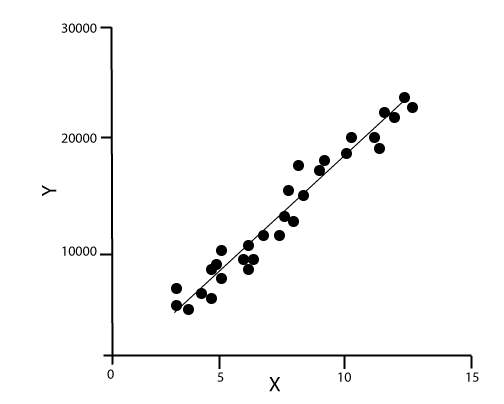
The below equation can describe the relationship between x and y variables: Where, y= Dependent variable 2. Decision Tree: Decision Tree algorithm is another machine learning algorithm, which belongs to the supervised learning algorithm. This is one of the most popular machine learning algorithms. It can be used for both classification and regression problems. In the decision tree algorithm, we can solve the problem, by using tree representation in which, each node represents a feature, each branch represents a decision, and each leaf represents the outcome. Following is the example for a Job offer problem: 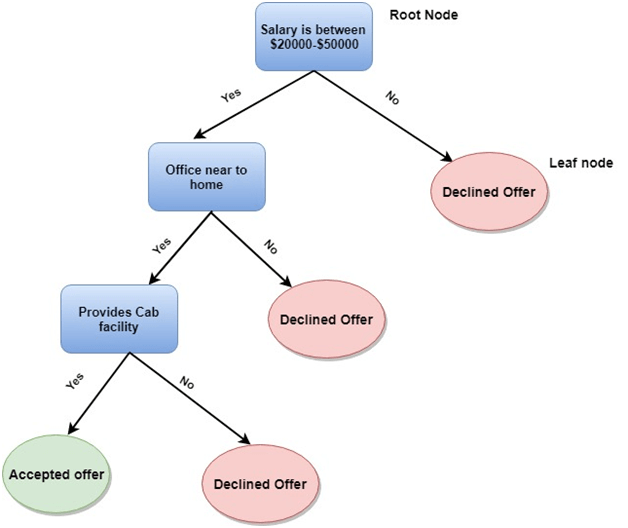
In the decision tree, we start from the root of the tree and compare the values of the root attribute with record attribute. On the basis of this comparison, we follow the branch as per the value and then move to the next node. We continue comparing these values until we reach the leaf node with predicated class value. 3. K-Means Clustering: K-means clustering is one of the most popular algorithms of machine learning, which belongs to the unsupervised learning algorithm. It solves the clustering problem. If we are given a data set of items, with certain features and values, and we need to categorize those set of items into groups, so such type of problems can be solved using k-means clustering algorithm. K-means clustering algorithm aims at minimizing an objective function, which known as squared error function, and it is given as: 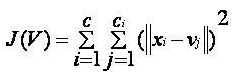
Where, J(V) => Objective function How to solve a problem in Data Science using Machine learning algorithms?Now, let's understand what are the most common types of problems occurred in data science and what is the approach to solving the problems. So in data science, problems are solved using algorithms, and below is the diagram representation for applicable algorithms for possible questions: 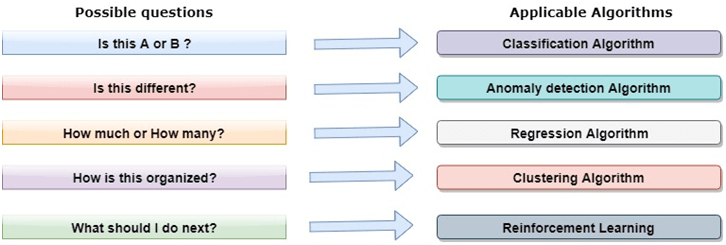
Is this A or B? : We can refer to this type of problem which has only two fixed solutions such as Yes or No, 1 or 0, may or may not. And this type of problems can be solved using classification algorithms. Is this different? : We can refer to this type of question which belongs to various patterns, and we need to find odd from them. Such type of problems can be solved using Anomaly Detection Algorithms. How much or how many? The other type of problem occurs which ask for numerical values or figures such as what is the time today, what will be the temperature today, can be solved using regression algorithms. How is this organized? Now if you have a problem which needs to deal with the organization of data, then it can be solved using clustering algorithms. Clustering algorithm organizes and groups the data based on features, colors, or other common characteristics. Data Science LifecycleThe life-cycle of data science is explained as below diagram. 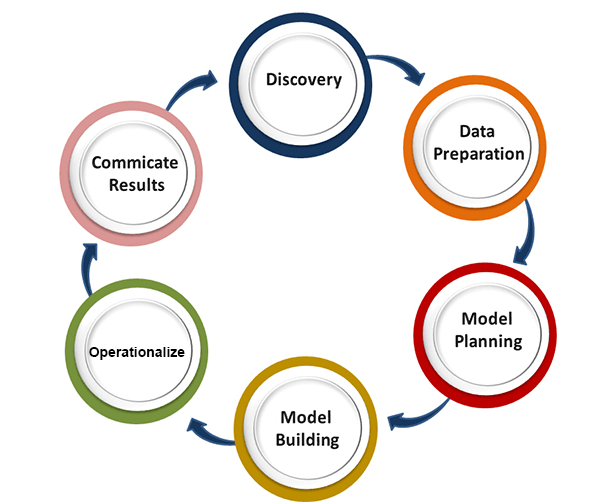
The main phases of data science life cycle are given below: 1. Discovery: The first phase is discovery, which involves asking the right questions. When you start any data science project, you need to determine what are the basic requirements, priorities, and project budget. In this phase, we need to determine all the requirements of the project such as the number of people, technology, time, data, an end goal, and then we can frame the business problem on first hypothesis level. 2. Data preparation: Data preparation is also known as Data Munging. In this phase, we need to perform the following tasks:
After performing all the above tasks, we can easily use this data for our further processes. 3. Model Planning: In this phase, we need to determine the various methods and techniques to establish the relation between input variables. We will apply Exploratory data analytics(EDA) by using various statistical formula and visualization tools to understand the relations between variable and to see what data can inform us. Common tools used for model planning are:
4. Model-building: In this phase, the process of model building starts. We will create datasets for training and testing purpose. We will apply different techniques such as association, classification, and clustering, to build the model. Following are some common Model building tools:
5. Operationalize: In this phase, we will deliver the final reports of the project, along with briefings, code, and technical documents. This phase provides you a clear overview of complete project performance and other components on a small scale before the full deployment. 6. Communicate results: In this phase, we will check if we reach the goal, which we have set on the initial phase. We will communicate the findings and final result with the business team. Applications of Data Science:
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








