| |

Kubernetes Tutorial
What is Kubernetes?Kubernetes is also known as 'k8s'. This word comes from the Greek language, which means a pilot or helmsman. It is actually an enhanced version of 'Borg' for managing the long-running processes and batch jobs. Nowadays, many cloud services offer a Kubernetes-based infrastructure on which it can be deployed as the platform-providing service. This technique or concept works with many container tools, like docker, and follows the client-server architecture. Key Objects of KubernetesFollowing are the key objects which exist in the Kubernetes: Pod It is the smallest and simplest basic unit of the Kubernetes application. This object indicates the processes which are running in the cluster. Node A node is nothing but a single host, which is used to run the virtual or physical machines. A node in the Kubernetes cluster is also known as a minion. Service A service in a Kubernetes is a logical set of pods, which works together. With the help of services, users can easily manage load balancing configurations. ReplicaSet A ReplicaSet in the Kubernetes is used to identify the particular number of pod replicas are running at a given time. It replaces the replication controller because it is more powerful and allows a user to use the "set-based" label selector. Namespace Kubernetes supports various virtual clusters, which are known as namespaces. It is a way of dividing the cluster resources between two or more users. Features of KubernetesFollowing are the essential features of Kubernetes: 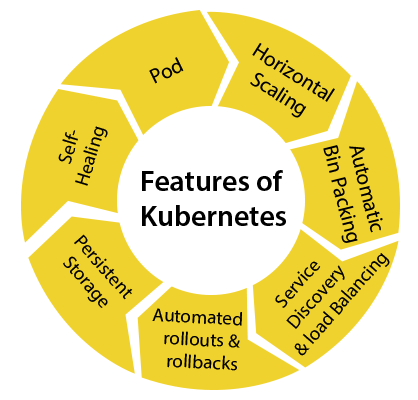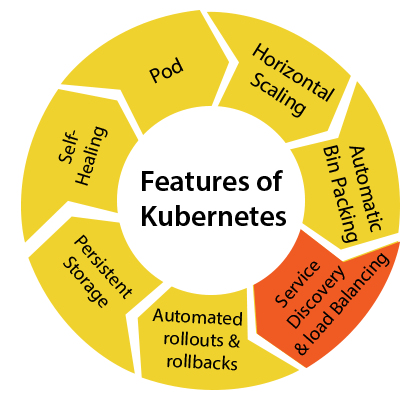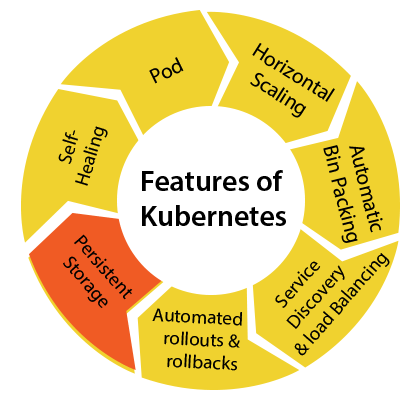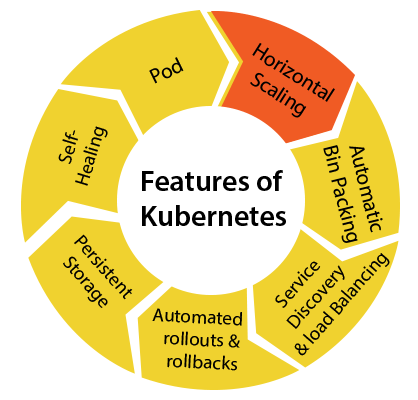
Kubernetes Architecture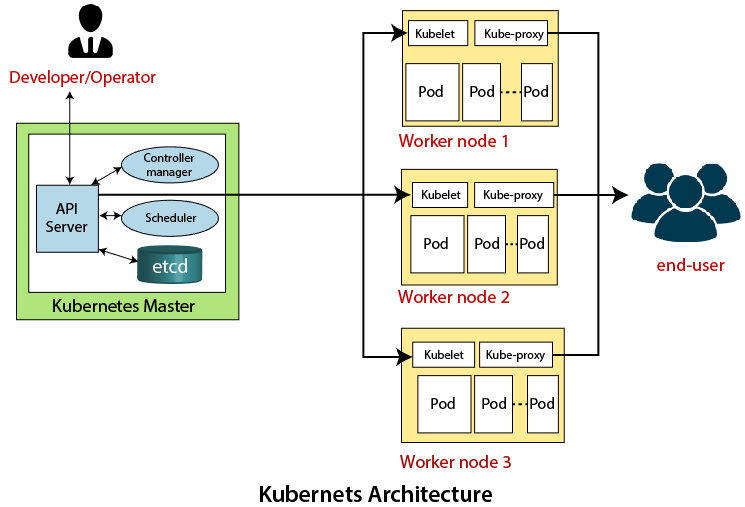
The architecture of Kubernetes actually follows the client-server architecture. It consists of the following two main components:
Master Node or Kubernetes Control PlaneThe master node in a Kubernetes architecture is used to manage the states of a cluster. It is actually an entry point for all types of administrative tasks. In the Kubernetes cluster, more than one master node is present for checking the fault tolerance. Following are the four different components which exist in the Master node or Kubernetes Control plane:
API Server The Kubernetes API server receives the REST commands which are sent by the user. After receiving, it validates the REST requests, process, and then executes them. After the execution of REST commands, the resulting state of a cluster is saved in 'etcd' as a distributed key-value store. Scheduler The scheduler in a master node schedules the tasks to the worker nodes. And, for every worker node, it is used to store the resource usage information. Controller Manager The Controller manager is also known as a controller. It is a daemon that executes in the non-terminating control loops. The controllers in a master node perform a task and manage the state of the cluster. In the Kubernetes, the controller manager executes the various types of controllers for handling the nodes, endpoints, etc. ETCD It is an open-source, simple, distributed key-value storage which is used to store the cluster data. It is a part of a master node which is written in a GO programming language. Now, we have learned about the functioning and components of a master node; let's see what is the function of a slave/worker node and what are its components. Worker/Slave nodeThe Worker node in a Kubernetes is also known as minions. A worker node is a physical machine that executes the applications using pods. It contains all the essential services which allow a user to assign the resources to the scheduled containers. Following are the different components which are presents in the Worker or slave node: Kubelet This component is an agent service that executes on each worker node in a cluster. It ensures that the pods and their containers are running smoothly. Every kubelet in each worker node communicates with the master node. It also starts, stops, and maintains the containers which are organized into pods directly by the master node. Kube-proxy It is a proxy service of Kubernetes, which is executed simply on each worker node in the cluster. The main aim of this component is request forwarding. Each node interacts with the Kubernetes services through Kube-proxy. Pods A pod is a combination of one or more containers which logically execute together on nodes. One worker node can easily execute multiple pods. Installation of Kubernetes on LinuxThe installation of Kubernetes on Linux is a straight forward process. Follow the below steps to install the Kubernetes. In the installation of Kubernetes, each step is mandatory. Step 1: In this step, we have to update the necessary dependencies of a system using two commands. The first command is used to get all the updates. Execute the following command in the terminal; it will ask to enter the system's password. Output: 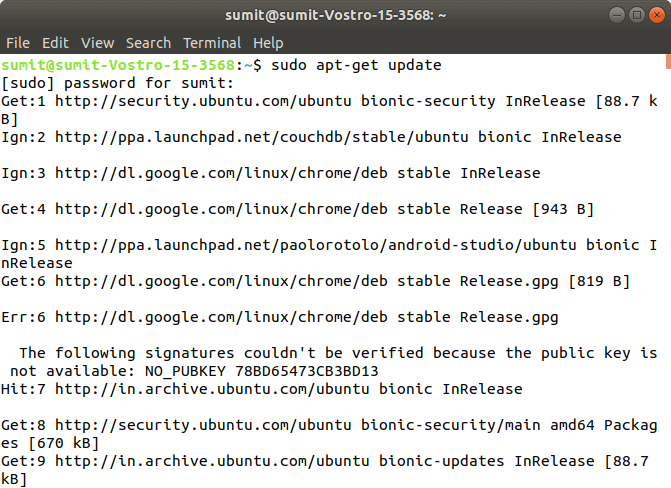
When the first command is successfully executed, type the following second command, which is used to make the repositories. Output: 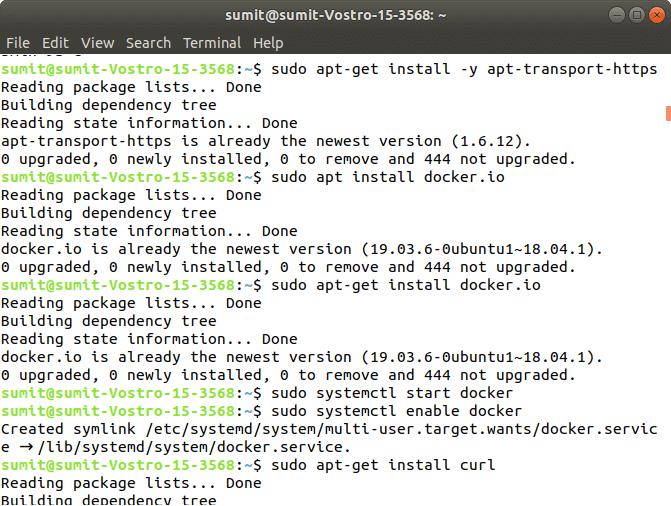
Step 2: After the above steps are successfully executed, we have to install the dependencies of docker in this step. Type the following command to install the docker. In the installation process, we have to choose Y for confirmation of the installation. Output: 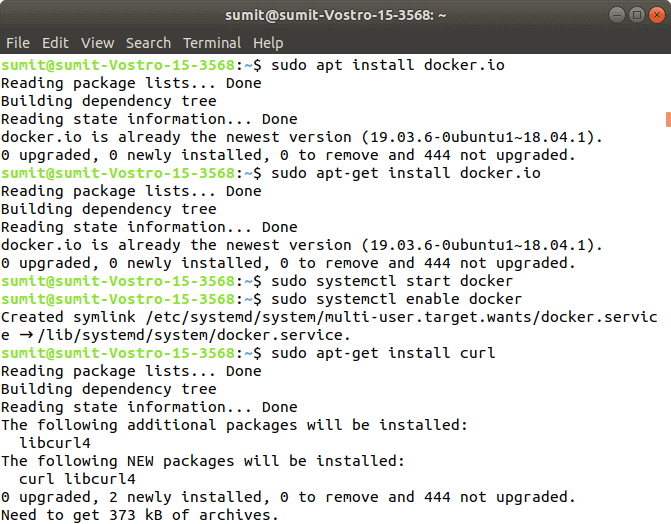
After installing the docker, we have to type the different two commands for starting and enabling the docker. Type the following first command, which starts the docker: Now, type the following second command, which enables the docker: Output: 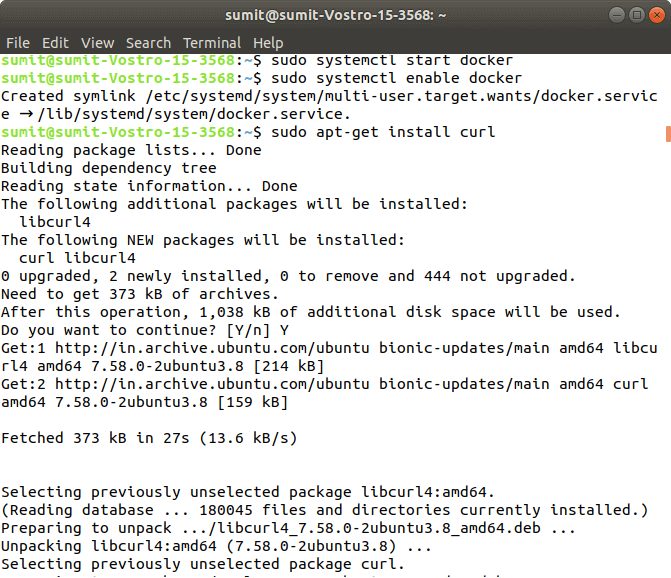
Now, we can check the version of docker by typing the following command: Output: 
Step 3: After the successful execution of all the commands of the second step, we have to install the curl command. The curl is used to send the data using URL syntax. Now, install the curl by using the following command. In the installation, we have to type Y. Output: 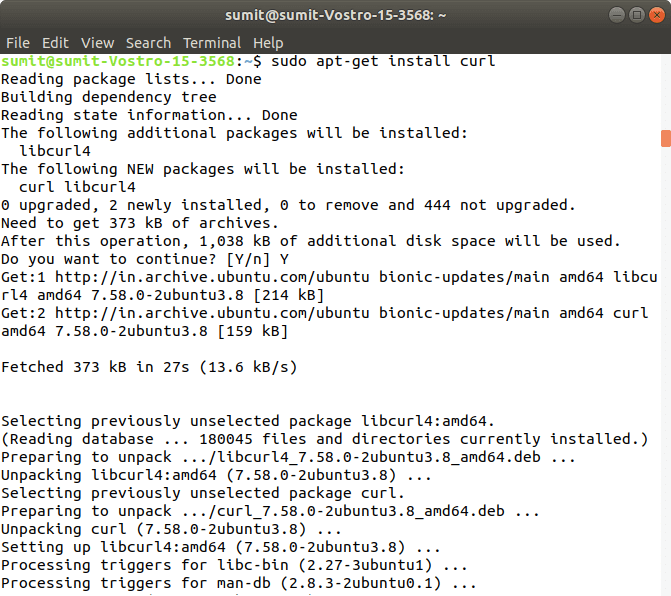
Now, we have to download the add package key for Kubernetes by the following command: Output: 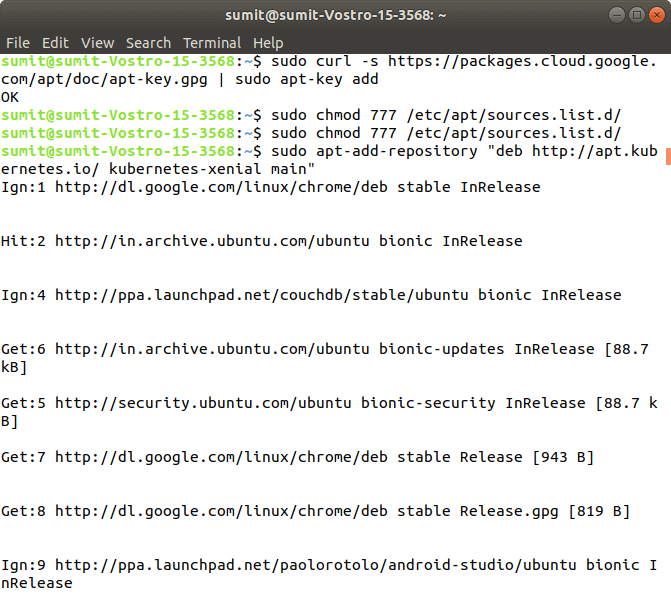
If you get an error from the above command, then it means your curl command is not successfully installed, so first install the curl command, and again run the above command. Now, we have to add the Kubernetes repositories by the following command: Output: 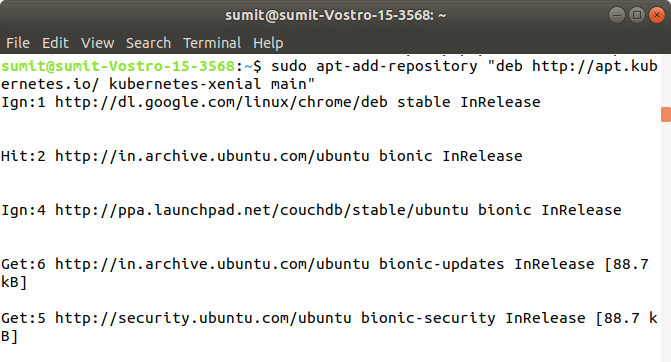
After the successful execution of the above command, we have to check any updates by executing the following command: Output: 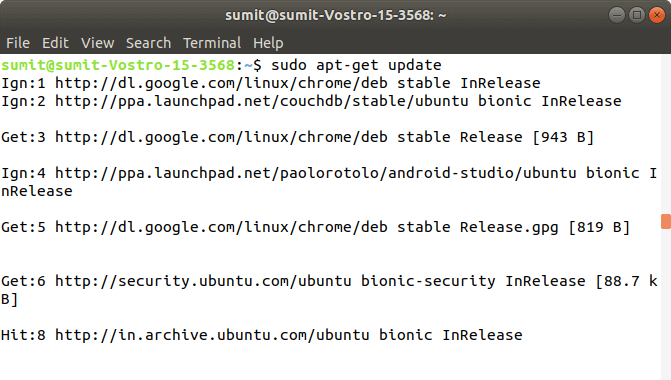
Step 4: After the execution of the above commands in the above steps, we have to install the components of Kubernetes by executing the following command: Output: 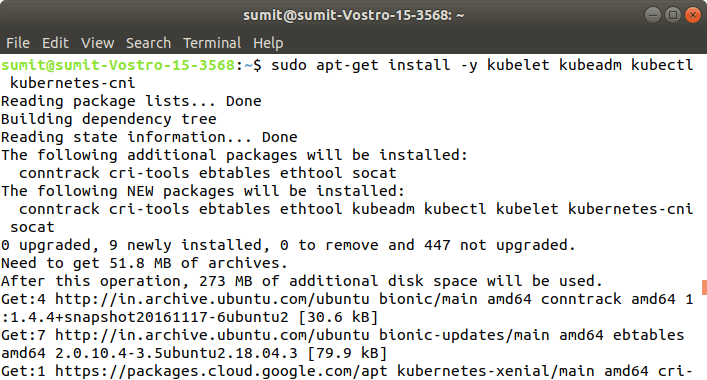
Step 5: After the above installation is done, we have to initialize the kubeadm by executing the following command. The following command disables the swapping on other devices: Output: 
Now, we have to initialize the kubeadm by executing the following command: Output: 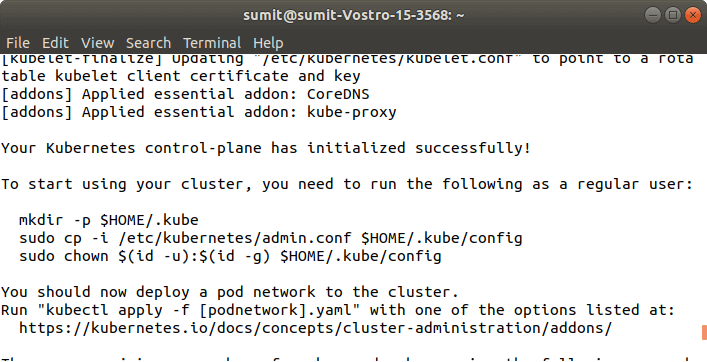
Step 6: After the above command is successfully executed, we have to run the following commands, which are given in the initialization of kubeadm. These commands are shown in the above screenshot. The following commands are used to start a cluster: 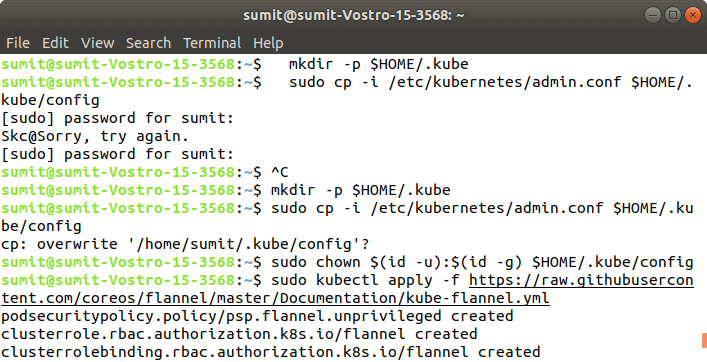
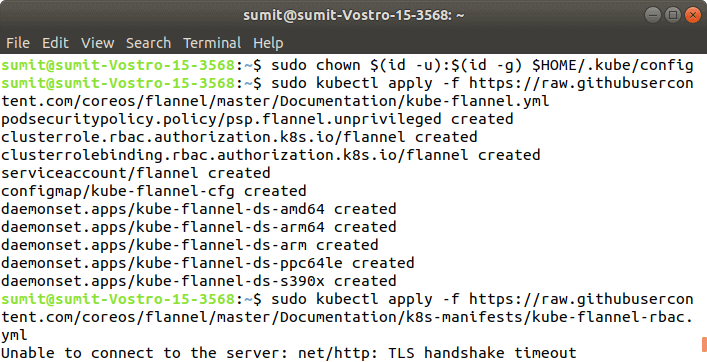
Output: Step 7: In this step, we have to deploy the paths using the following command: Output: 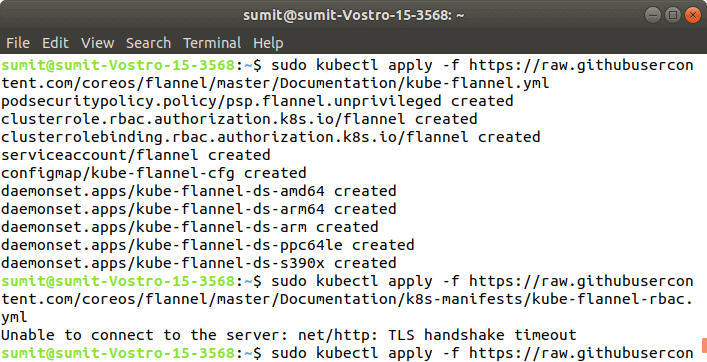
Step 8: After the execution of the above command, we have to run the following command to verify the installation: Output: 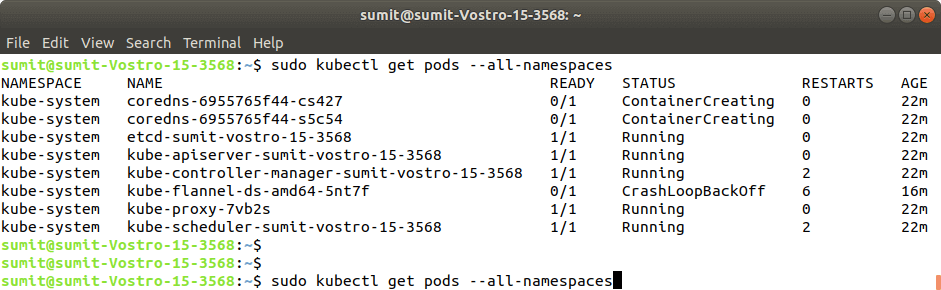
If the output is displayed as shown in the above screenshot. It means that the Kubernetes is successfully installed on our system. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








