Spark Big Data
Spark has been proposed by Apache Software Foundation to speed up the software process of Hadoop computational computing. Spark includes its cluster management, while Hadoop is only one of the forms for implementing Spark.
Spark applies Hadoop in two forms. The first form is storage and another one is processing. Thus, Spark includes its computation for cluster management and applies Hadoop for only storage purposes.
Apache Spark
Apache Spark is a distributed and open-source processing system. It is used for the workloads of 'Big data'. Spark utilizes optimized query execution and in-memory caching for rapid queries across any size of data. It is simply a general and fast engine for much large-scale processing of data.
It is much faster as compared to the previous concepts to implement with Big Data such as classical MapReduce. Spark is faster die to it executes on RAM/memory and enables the processing faster as compared to the disk drivers.
Spark is simple due to it could be used for more than one thing such as working with data streams or graphs, Machine Learning algorithms, inhaling data into the database, building data pipelines, executing distributed SQL, and others.
Apache Spark Evolution
Spark is one of the most important sub-projects of Hadoop. It was developed in APMLab of UC Berkeley in 2009 by Matei Zaharia. In 2010, it was an open-source under the BSD license. Spark was donated in 2013 to the Apache Software Foundation. Apache Spark is now a top-level project of Apache from 2014 February.
Ecosystem of Spark
The main components of the Spark Ecosystem are explained below:
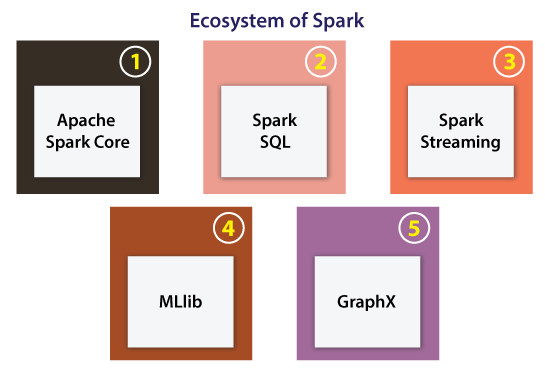
- Apache Spark Core: Apache Spark Core can be defined as an underlying normal execution engine for the platform of Spark. It facilitates referencing data sets and in-memory computing within the external storage structures.
- Spark SQL: This component is a module of Apache Spark for operating with many kinds of structured data. Various interfaces provided by Spark SQL facilitates Spark along with a lot of information regarding both the computation and data being implemented.
- Spark Streaming: Spark streaming permits Spark for processing streaming data in real-time. The data could be inhaling from several sources such as Hadoop Distributed File System (HDFS), Flume, and Kafta. After that data could be processed with complex algorithms and then pushed out towards the live dashboards, databases, and file systems.
- Machine Learning Library (MLlib): Apache Spark is armed with a prosperous library called MLlib. The MLlib includes a wide range of machine learning algorithms collaborative filtering, clustering, regression, and classifications. Also, it contains other resources for tuning, evaluating, and constructing ML pipelines. Each of these functionalities supports Spark scale-out around the cluster.
- GraphX: Apache Spark comes using a library for manipulating graph databases and implement computations known as GraphX. This component unifies Extract, Transform, and Load (ETL) process, constant graph computation, and exploratory analysis in an individual system.
There are also some others such as Tachyon and BlinkDB:
- Tachyon: It is a memory-centric shared file system. It can enable faithful file distribution on memory speed around cluster frameworks like MapReduce and Spark. It caches implementing set files inside the memory, thus ignoring going to disk for loading data sets that are read frequently. It enables different frameworks and queries/jobs for accessing cached files on memory speed.
- BlinkDB: It is an approximate engine for the query. It can be used to run reciprocal SQL queries over a large amount of data. Also, it permits users to trading-off query efficiency for response time. BlinkDB works over large sets of data by executing queries on various data samples. It can present outcomes annotated with valid error bars.
Also, there are integration adaptors along with some other products such as SparkR (R), and Spark Cassandra Connector (Cassandra). We can utilize Spark for accessing data that is stored inside the Cassandra database and Implement analysis of data on that particular data using Cassandra Connector.
Architecture of Spark
The architecture of Spark contains three of the main elements which are listed below:
- API
- Data Storage
- Resource Management
Let's defines these elements in detail.
API
This element facilitates many developers of the applications for creating Spark-based applications with a classic API interface. Spark offers API for Python, Java, and Scala programming languages.
Data Storage
Spark applies the Hadoop Distributed File System for various purposes of data storage. It works with any data source that is compatible with Hadoop including Cassandra, HBase, HDFS, etc.
Resource Management
The Spark could be expanded as the stand-alone server. Also, it can be expanded on any shared computing framework such as YARN or Mesos.
RDD in Spark
RDD stands for Resilient Distributed Dataset. It is a core concept within the Spark framework. Assume RDD like any table inside the database. It could take any data type. Spark can store data in Resilient Distributed Dataset on distinct partitions.
These datasets can support to rearrange the computations and upgrading the processing of data.
Also, these datasets are fault-tolerant due to the RDD which understands how to re-compute and recreate the datasets.
Resilient Distributed Datasets are immutable. We can change RDD using a transformation. However, this transformation will return us to a newer RDD while the actual RDD endures the same.
In more detail, RDD provides its support for two kinds of operations:
Action
This operation assesses and returns a newer value. Each query of data processing is computed and the final value will be returned if a function of action is called over an RDD object.
A few of the operations of Action are foreach, countByKey, take, first, count, collect, and reduce.
Transformation
Transformation does not return any single value. It returns a newer RDD. Nothing will be assessed if we call any function of transformation. It only holds the RDD and then returns a newer RDD.
A few of the operations of Transformation are coalesce, pipe, aggregateByKey, reduceByKey, groupByKey, flatMap, filter, and map.
Spark Installation
There are some different things to use and install Spark. We can install Spark on our machine as any stand-alone framework or use the images of Spark VM (Virtual Machine) available from many vendors such as MapR, HortonWorks, and Cloudera. Also, we can use Spark configured and installed inside the cloud (such as Databricks Clouds).
Spark Execution
When we use the Cloud-based installation to install Spark or install it on a local machine, there are some different ways we can link to the Spark engine.
The below table illustrates the parameter of the Master URL for different ways of executing Spark:
| Master URL |
Description |
| Local |
It can locally execute Spark with a single worker thread (such as no parallelism). |
| Local[K] |
It can locally execute Spark using K worker nodes (set it ideally to the cores counts on our machine). |
| Local[*] |
It can locally execute Spark using a lot of worker threads same as the logical cores on our machine. |
| spark://HOST:PORT |
It provides a facility to connect to a provided stand-alone Spark cluster master. The port should be the one that can be easily configured for use by our master, which is by default 7077. |
| mesos://HOST:PORT |
It provides a facility to connect to a provided Mesos cluster. The port should be the one that can be easily configured for use, which is by default 5050. |
| yam-client |
This URL helps to connect to a YARN cluster within the client mode. The location of the cluster will be detected on the basis of a variable, i.e., HADOOP_CONF_DIR. |
| yam-cluster |
This URL helps to connect to a YARN cluster within the cluster mode. The location of the cluster will be detected on the basis of the HADOOP_CONF_DIR. |
Features of Spark
Some of the primary features of Spark are as follows:
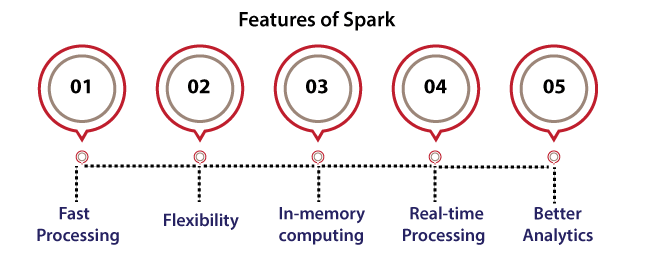
- Fast processing: One of the most essential aspects of Spark is that it has enabled the world of big data to select the technology on others because of its speed. On the other hand, big data is featured by veracity, variety, velocity, and volume which require to be implemented at a great speed. Spark includes RDD (Resilient Distributed Dataset) which can save time in writing and reading operations, permitting it to execute almost many times faster as compared to Hadoop.
- Flexibility: Spark supports more than one language and permits many developers for writing applications in Python, R, Scala, or Java.
- In-memory computing: Apache Spark can store the data inside the server's RAM which permits quick access. Also, it accelerates analytics speed.
- Real-time processing: Apache Spark can process streaming data in real-time. Unlike MapReduce that only processes stored data, Apache Spark can process data in real-time. Therefore, it can also produce instant results.
- Better analytics: In variations of MapReduce that provides the ability for mapping and reducing functions, Spark provides much more as compared to it. Apache Spark combines a prosperous set of machine learning, complex analytics, SQL queries, etc. Using each of these functionalities, analytics could be implemented in a better way using Spark.
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








