| |

ETL ProcessETL stands for Extraction, Transformation, and loading. ETL is a process which is used to Extract data, Transform the data and loading of the data to the final source. ETL follows a process of loading the data from the source system to the Data Warehouse. 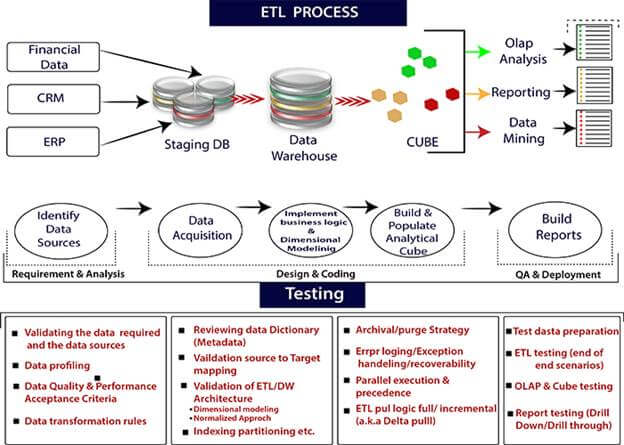
Steps to perform the ETL process are: ExtractionExtraction is the first process where data from different sources like text file, XML file, Excel file, or various other sources are collected. TransformationTransformation is the second step of the ETL process, where all the collected data has been transformed into the same format. The format can be anything as per our requirement. In this step, a set of rules of functions are applied to the extracted data to convert it into a single standard format. It may involve the following tasks:
LoadingLoading is the final step of the ETL process. The big chunk of data is collected from various sources, transformed them, and finally loaded to the data warehouse. ETL is a process to extract the data from different source systems, transform the data, and load the data into the data warehouse. ETL process requires active input from various stakeholders including, developers, analysts, testers, top executive. ETL (Extract, Transform and Load) is an automated process of extracting the information from the raw data which is required for analysis and transforms it into a format that can serve business needs and loads it into a data warehouse. ETL typically summarize data to reduce its size and improve performance for a specific type of analysis. ETL process uses the pipelining concept. In this concept, as soon as the data is extracted, it can be transformed, and during the period of transformation, new data can be obtained. And when the modified data is being loaded into the data warehouse, the already extracted data can be transformed. 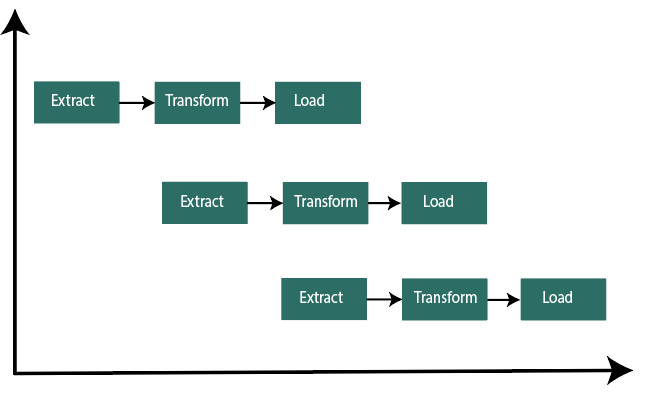
When we build an ETL infrastructure, we must integrate data sources, carefully plan, and test to ensure that we transform the source data correctly. Here, we are explaining three ways to build an ETL infrastructure, and one more way to build a data pipeline without using ETL. 1) Building an ETL pipeline with batch processingHere, are the processes to build a traditional ETL process, in which we transfer and process the data in batches from the source database to the data warehouse. It is challenging to develop an enterprise ETL Pipeline; we will typically rely on ETL tools such as Stitch and Blendo, which simplify and automate the process. Building ETL with batch processing, here is the ETL best practice. 1) Reference Data: Here, we will create a set of data that defines the set of permissible values, and may contain the data. Example: In a country data field, we can define the country codes which are allowed. 2) Extract from Data Reference: The success of ETL steps is to extract the data correctly. Most of the ETL systems combine the data from multiple source systems, each with its data organization and format including relational database, non-relational database, XML, JSON, CSV files and after successful extraction, data is converted into a single format for standardizing the format. 3) Data Validation: An automated process confirms whether the pulled data from sources have expected values. For example, A data field should contain valid dates within the past 12 months in a database of financial transaction from the past year. The validation engine rejects the data if it fails the validation rules. We analyze the rejected records, on a regular basis, to identify what went wrong. Here we correct the source data or modify extracted data to resolve the problem in the next batches. 4) Transform Data: Removing extraneous or erroneous data, applying business rules, checking data integrity (ensuring that data was not corrupted in the source or corrupted by ETL and no data was dropped in the previous stages), and creating aggregate as necessary. If we analyze revenue, we can summarize the dollar amount of invoices into a daily or monthly total. We need to program and test a series of rules or functions that can achieve the required transformation and run them on the extracted data. 5) Stage: We will not typically load transformed data directly into the target data warehouse. Data should be entered first into a staging database, making it easier to roll back if something goes wrong. At this point, we can also generate audit reports for regulatory compliance or diagnose and repair data problems. 6) Publish to Data Warehouse: Loading the data to the target tables. Some data warehouse overwrites existing information every time, the ETL pipeline loads a new batch daily, monthly or weekly. In other words, ETL can add new data without overwriting, with a timestamp indicating it is unique. We must do this carefully to prevent data warehouse from "bursting" due to disk space and performance limitation. 2) Building an ETL Pipeline with stream processingModern data processes often include real-time data. For example, from a large e-commerce website web analytics data. In these use cases, we cannot extract and transform data in large batches, and the need arises to perform ETL on data streams, which means as client applications write data to the data source, data should be treated, transformed and saved immediately to the target data store. Many stream processing tools are available today including- apache Samza, Apache store, and Apache Kafka. 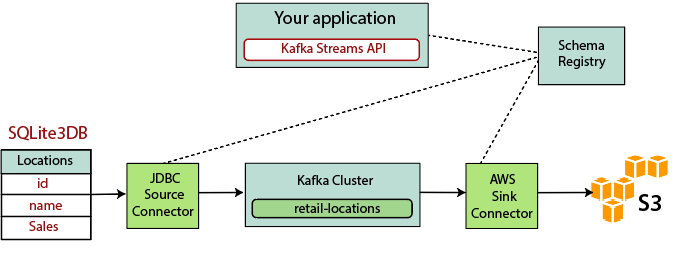
Building streaming ETL based on Kafka involves the following points: 1) Extracting data into Kafka: The JDBC connector pulls each row of the source table. As client applications add rows to the table, Kafka automatically writes them as a new message to the Kafka topic, which enables the real-time data stream. 2) Pulling data from Kafka: ETL application extract messages from the Kafka topics as Avro Records, which creates an Avro schema file and deserialize them, and created KStream objects from the messages. 3) Transform Data in KStream object: Using Kafka Streams API, the stream processor receives one record at a time, processes it and can produce one or more output records from the downstream processor. These can transform one message at a time, filter them based on conditions, or perform data operations on multiple messages. 4) Load Data to other systems: ETL applications still hold the data, and now this need to stream it into target systems, such as data warehouse or data lakes. Their purpose is to use a S3 sink connector to stream the data to Amazon S3. We can implement integration with other systems. For example: stream the data to a Redshift data warehouse using Amazon Kinesis.
Next TopicETL Interview Questions
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








