| |

High AvailabilityAccomplishing corporate sustainability is a big priority for global corporations. Downtime may cause severe economic effects and, in certain cases, irreparable system failures. A high availability architecture is a strategy to eliminate service interruption and process failures. Every organization is highly dependent on the Internet, because of which machines and servers for companies should remain readily available at all times. High availability should be the primary aspect to be considered while establishing your IT infrastructure, whether you'd like to host your own IT technology or opt for the unified platform on a server farm. What is High AvailabilityIn order to provide continuous service over a particular time, a highly available architecture needs numerous modules functioning simultaneously. This often requires the reaction time to the queries of users. In particular, software solutions need not only to be digital but also reactive. To ensure the uninterrupted supply of crucial software and systems, implementing cloud computing infrastructure that allows it is important. When the different component damage occurs or when a device is under intense strain, it remains online and adaptive. Highly available networks have the potential to regenerate in the quickest way possible from unforeseen incidents. These systems reduce downtime or remove it by transferring the functions to replacement modules. In order to ensure that there are no trouble spots, this normally includes routine servicing, inspection, and preliminary in-depth checks. Multiple server structures with device software for ongoing analysis of the network's efficiency provide high availability situations. Avoiding unscheduled downtime for machines is the highest priority. When a part of machinery crashes, a total cessation of operation during the manufacturing time must not be triggered. For large organizations, remaining functional without disruptions is extremely crucial. A few moments disrupted in such environments can cause a loss of credibility, clients, and billions of dollars. Modern computers that are universally readable enable bugs as long as the degree of accessibility does not affect business activities. There are the following features of a highly available infrastructure:
The Need of High AvailabilityDowntime is the amount of time when your device (or connection) is unconscious or inaccessible. Leisure time may cause severe damage for a business, as when their devices are overloaded; all their operations are temporarily suspended. Amazon fell down for 15 minutes in August 2013 (like web and mobile operations) and eventually lost more than $66,000 in a minute. These are all massive numbers, even for an Amazon-sized company. There are two kinds of rest time: scheduled and unscheduled. A planned schedule throughput is an inevitable consequence of service. This involves the application of patches, software updates, and even modifications to the data structure. After all, unplanned downtime is induced by a certain unexpected occurrence, such as system failure. It can occur because of a module's power shortages or failure. Planned schedule breakdowns are largely prohibited from estimations of achievement. The primary goal of introducing the High Availability structure is to ensure that your device or software is designed with limited to no rest time to accommodate multiple pressures and multiple vulnerabilities. There are many factors that influence you to accomplish it, and we will speak about it momentarily. The Architecture of High Availability (HA)There might be several instances in the modern world where a decrease in your server's output from incidents varying from a sharp uptick in traffic can escalate to a sudden power failure. It can be even worse; regardless of whether the programs are hosted in the clouds or on a computer device, the servers can be overwhelmed. Such circumstances are inevitable. Instead of pretending that it doesn't happen, though, what you can really do is prepare properly so that your devices don't breakdown. The solution to the crisis is the use of setting up or infrastructure for High Availability (HA). The architecture of high availability is an approach to determine the elements, units or utilities of a device that ensures maximum production efficiency, however at periods of high load. While there are no predetermined guidelines for the implementation of High Availability systems, there are typically a few standard methods that should be followed in order to achieve the most from the least amount of effort. 
How to measure the percentage of response time for high availability?Availability is defined as how long over a definite duration, generally a year, a particular device remains fully functional. As a percentage, it is conveyed. Notice that response time does not have to indicate just like availability inherently. It is possible for a device to be up and going but not open to consumers. Network or load balancing problems may be the causes for this. Normally, the response time is demonstrated by using the scoring with the availability of five 9's. It will be specified in the Service Level Agreement (SLA) if you plan to go out for a unified platform. A rating of 'one nine' implies that the availability assured is 90%. Many organizations and corporations currently need to provide at least "three nines," i.e., 99.9% of availability. Organizations have different availability requirements. Five nines, "99.999 percent of throughput, would target those who need to stay functional across the clock during the year." It would seem like 0.1 percent doesn't make a significant difference that much. The measurements are small, indeed, if you translate it to minutes and hours. To consider the cumulative response time per year each rank contains, according to the list of nines:
The disparity among 99 percent and 99.9 percent is significant, as the above table indicates. Remember that it is estimated in days, not in hours or minutes, every year. The farther you want to be on the availability level, the cost of the product will also grow. How will response time be measured? For any element that could influence the efficient implementation of a part of the system, or the whole structure, it is important to quantify downtime. The Planned service of the device should be part of the calculation of availability. As you can see, the above table does not show a 100% availability point. In simple terms, any system is not completely exempt from failure. In contrast, it can require some time to turn to substitute parts, be milliseconds, minutes, or hours. Achievement of High AvailabilityCorporations trying to incorporate strategies of high availability need to consider several elements and criteria required to obtain as highly available for a system. Security mechanisms and facilities requirements to be managed around the clock to achieve the business goals and serviceability. Some requirements that need to be fulfilled include industry standards for achieving high availability. Here we have four steps to achieve efficiency and uptime of 99.999%. 1. Reducing high availability vs. redundancy of single points of failureBy ensuring replication on all grades, the crucial aspect of high-availability structures is to remove vulnerabilities. Regardless of if there is a global catastrophe, a device or power outage, to repair the damaged device, IT infrastructures should have backup elements. There are various extremes of part duplication that exist. The most prevalent among them are:
Let's go through each above-mentioned model. N+1 Model It involves the volume of hardware required to maintain the machine up (referred to as 'N'). For each of the modules, it is functional with single separate backup element in case of a fault. Using an external source of power for a database server will be an instance, but this could be some other IT element. Normally, this paradigm is active / passive. If a malfunction occurs, replacement modules are on reserve, preparing to take over. The replication of N+1 may be active as well. Notice that the N+1 template is not a design that is fully redundant. N+2 Model It is equivalent to the N+1 model. The discrepancy is that the device can tolerate the breakdown of two similar elements. This will be enough in the higher nines to sustain most companies running smoothly. 2N Model This model requires twice the amount of every single part required for the system to operate. The benefit of this strategy is that you may not have to take into account whether a single element or the entire system has failed. The tasks can be transferred directly to the substitute elements. 2N+1 Model With some other variables for enhanced security, the 2N+1 model offers the same degree of availability and replication as 2N. By regional replication, the absolute redundancy is accomplished. It is the only full failure strategy toward natural catastrophes and other occurrences. In this situation, in various regions, servers are spread over several regions. It is appropriate to position websites in different towns, nations, or even continents. They are completely autonomous in that sense. Another will be able to acquire and keep the company going if a massive failure occurs in one place. This form of replication proves to be relatively expensive. The positive territory would be to go for a unified platform from one of the network infrastructure vendors spanning the globe. In addition to power failures, one of the most prominent determinants of this business slowdown is network problems. The network should be designed in such a manner that it remains up 24/7/365 for that purpose. There must be alternative network routes to reach 100 percent network service throughput. There should be interchangeable enterprise-grade switching and adapters in each of them. 2. Remediation and Data BackupOne of the main challenges for any enterprise is data protection. A system with high availability should have sound strategies for data security and recovery procedures. To have adequate replacements is an essential necessity. The order to effectively restore in the event of a system failure, fraud, or total storage breakdown is another important thing. The best choice to suggest is to use data replication when your company needs low RTOs and RPOs, and you cannot stand to waste data. Based on company scope, needs, and expenditure, there are several contingency plans to select from. With the high availability of IT, full backup and recovery go together. Both should be prepared carefully. To ensure data redundancy, the development of complete backups on a replicate infrastructure is crucial and must not be ignored. 3. Automatic failback with Detection of FailureIn a highly usable, replicate IT architecture, the device requires to divert requests to a backup generator immediately in case of a fault. This is known as failover. Early diagnosis of vulnerability is critical for enhancing failover rates and ensuring optimum efficiency of services. For high availability, one of the solutions and services we suggest Carbonite Availability. Either it is digital or actual, it is sufficient for any architecture. You may switch to Cloud Replica for efficient and scalable cloud-based network downtime and fail-back. The failover approach refers to either an entire system or some of its components that may crash down. Failover must be transparent and happen in real-time if a part fails or a database server avoids reacting. The mechanism seems like the following:
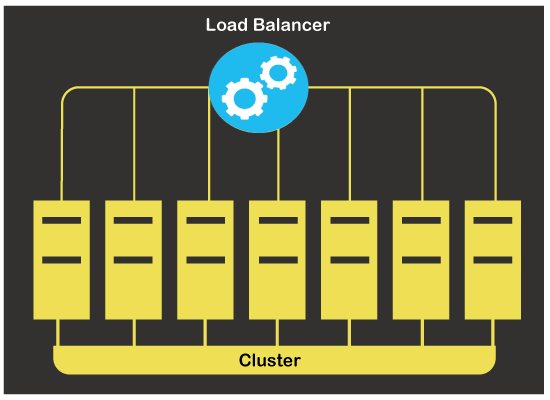
The length of the failure cycle focuses on how complex the device is. It will take a few minutes in several situations. However, it may also take many hours. To achieve the best performance, preparing for high availability should be dependent on all of these factors. The overall purpose of obtaining 99.999 % availability and improving failover times must be in alignment with each device component. 4. Load BalancingA load balancer may be a system for devices or a system for software. It aims to disperse multiple servers and modules with software or network services. The aim is to enhance overall efficiency and reliability in operations. By effectively handling loads and constantly tracking the back-end server's performance, it significantly improves the usage of servers and communication resources. How does a load balancer select the server?You may use several different strategies to spread the load through a pool of servers. It will rely on different considerations to choose the one for your caseloads. Any of these involve the form of software being supported, the network's status, and the backend servers' status. As per the current number of received requests, a load balancer determines which algorithm to use. Many of the most widely used algorithms for load balancing are discussed below: Robin's RoundThe load balancer, with the Round Robin algorithm, guides requests to the very first server in the queue. It will switch to the last one down the priority list and then start from scratch. It is simple to execute this method, and it is extensively utilized. It's doesn't, although, take into account whether servers have various parameters of hardware and whether they can overwhelm more easily. Limited ConnectionIn this situation, the server with the minimum number of registered links will be selected by the load balancer. If the user requests in, the load balancer just wouldn't, as is the situation with Round Robin, grant a link to another server in the queue. Rather, one with the minimum current links will be sought. In some cases where sessions last for a longer period, the lowest link method is especially suitable to prevent overburdening the web servers. Hash of Source IPThis method will decide which server to choose as per the request's source IP address. By using source and destination IP address, the load balancer generates a special cryptographic hash key. This key often allows a user's request to be directed to a certain server. After all, load balancers play a significant role in maintaining a highly open infrastructure. Even so, just getting a load balancer doesn't really imply that the system's availability is high. If a load balancer design just routes congestion to minimize the burden on an individual computer, it does not make the device highly usable. You may remove it as a single point of failure with the implementation of replication for the load balancer itself. Advantages of High AvailabilityHere, we have some advantages of the High Availability system. They are mentioned-below.
Next TopicBest C Cleaner Alternatives in 2020
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








