| |

What is Amazon EMR?Amazon Elastic Map Reduce (Amazon EMR) is a web service that makes it easy to process large amounts of data quickly and cost-effectively. Amazon EMR uses Hadoop, an open-source framework, to distribute your data and processing across resizable clusters of Amazon EC2 instances. Amazon EMR is used in various applications, including log analysis, web indexing, data warehousing, machine learning, financial analysis, scientific simulation, and bioinformatics. Customers launch millions of Amazon EMR clusters every year. Amazon EMR (formerly known as Amazon Elastic Map Reduce) is an Amazon Web Services (AWS) tool for big data processing and analysis. Amazon markets EMR as an expandable, low-configuration service that provides the option of running cluster computing on-premises. Amazon EMR is based on Apache Hadoop, a Java-based programming framework that supports the processing of large data sets in a distributed computing environment. Using Map Reduce, a core component of the Hadoop software framework, developers can write programs that process massive amounts of unstructured data in distributed clusters of processors or standalone computers. Google developed it to index web pages and replaced its original indexing algorithm and inference in 2004. Amazon EMR processes big data in Hadoop clusters of virtual servers on Amazon Elastic Compute Cloud (EC2) and Amazon Simple Storage Service (S3). Elastic in the name of EMR refers to its dynamic resizing capability, which enables administrators to increase or decrease resources based on their current needs. Amazon EMR is used for log analysis, web indexing, data warehousing, machine learning (ML), financial analysis, scientific simulation, and data analysis in bioinformatics. It also supports workloads based on Apache Spark, Apache Hive, Presto and Apache HBase, which integrate with Hive and Pig, which are open source data warehouse tools for Hadoop. Hive uses queries and analyzes data, and Pig provides a high-level mechanism for programming Map Reduce jobs to be executed in Hadoop. Amazon EMR Use CasesThere are many ways enterprises can use Amazon EMR, including: Machine Learning. EMR's built-in ML tools use the Hadoop framework to build a variety of algorithms to support decision making, including decision trees, random forests, support vector machines, and logistic regression. Extract, Convert and Load. ETL is the process of moving data from one or more data stores to another. Data transformation - such as sorting, aggregation and joining - can be done using EMR. Clickstream Analysis. Amazon S3 clickstream data can be analyzed with Apache Spark and Apache Hive. Apache Spark is an open-source data processing tool that can help make data easier to manage and analyze. Spark uses a framework that enables jobs to be run across large clusters of computers and can process data in parallel. Apache Hive is a data warehouse infrastructure built on top of Hadoop that provides tools to work with data that Spark can analyze. Clickstream analysis can help organizations understand customer behaviour, improve website layout, find out what keywords people use in search engines, and see which Word combinations lead to sales. Real-time Streaming. Users can analyze events using streaming data sources in real-time with Apache Spark Streaming and Apache Flink. It enables streaming data pipelines to be built on EMR. Interactive Analytics. EMR Notebook is a managed service that provides a secure, scalable and reliable environment for data analysis. Using Jupyter Notebook - Open-source web application data scientists can use to create and share live code and equations - data can be prepared and visualized to perform interactive analytics. Genomics. Organizations can use EMR to process genomic data to make data processing and analysis scalable for industries, including pharmaceutical and telecommunications. Amazon EMR Deployment OptionsAs a cloud service, Amazon EMR can be deployed in a variety of settings, such as: Amazon EMR on Amazon EC2. Using Amazon EC2, Amazon EMR can process large amounts of data quickly. Users can configure Amazon EMR to take advantage of on-demand, reserved and spot instances. Amazon EMR on Amazon Elastic Kubernetes Service (EKS). Amazon EMR Console enables users to run Apache Spark applications alongside other applications on the same EKS cluster. Organizations can share compute and memory resources across applications and use Kubera to monitor and manage infrastructure. 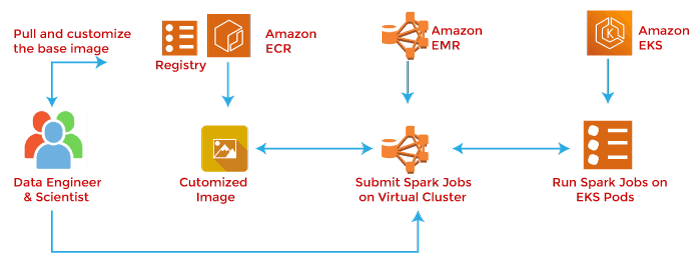
Amazon EMR featuresThe features of Amazon EMR are designed to make the following tasks easier and more convenient for administrators and developers:
Next TopicAmazon Relational Database Service
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








