| |

What is String in ProgrammingA string is typically a series of computer science instructions, whether as a literal constant or as some variable. The latter may be able to evolve its components and adjust the duration, or it could be set (after creation). A string is generally acknowledged as an information form. It is often represented as a byte (or term) range information structure that uses some character encoding to preserve a series of components, usually letters. The sequence can also designate as more generalized arrays or other forms and arrangements of sequence (or array) information. A variable is defined as sequence that may either cause immediate space to be permanently assigned to a fixed maximum size or implement an active dynamic allocation to contain a dynamic number of elements, depending on the programming language and correct information type used. When a sequence explicitly occurs in the code, it is classified as a specific string or an invisible string. A string is a finite series of symbols selected from a structure known as an alphabet in mathematical expressions used in mathematical logic and conceptual computer science. String datatypesA datatype string is a datatype modeled on a structured sequence concept. Strings are a data form that is so effective and necessary that they are introduced in almost every computer programming language. They are accessible as primitive data types in a specific languages and synthetic varieties in others. The structure of so many high-level programming languages enables an occurrence of a string datatype to be interpreted by a string, typically referenced in certain manner; such a meta-string is called a symbolic or string literal. String LengthWhile structured strings may have an absolute fixed length, they often restrict string's size to an imaginary maximum in specific languages. Besides, there are two kinds of string data types: strings of a specified length that have a defined maximum size to be calculated at the time of compilation and which use a similar amount of storage space, whether or not this maximum is required, and strings of variable size which do not have arbitrary finite size and which might be using different amounts of storage at runtime, based on the exact parameters. Variable-length strings are the bulk of sequences in other programming languages. Although variable-length strings are, for example, restricted in size by the amount of memory storage usable. The string's length can be processed as a different integer number (which can give the size another arbitrary barrier) or impliedly as a revocation character, usually a character quality with all null bits, such as in the computer language C. Character EncodingTraditionally, string datatypes have assigned one byte per character. Still, while the real character set diverse by province, character implementations were sufficiently similar to prevent developers from disregarding this because a program's specially prepared characters (such as time frame, storage, and comma) were in a similar place in all of the Unicode characters that a project would encounter. Traditionally, these character series are based on ASCII or EBCDIC. When a message was exhibited on a framework using distinct encryption in one processing, a message was often disfigured, although somewhat legible. Some internet users learned to read the disfigured text. Unicode has a kind of condensed image. Many other programming languages now have Unicode string datatypes. The chosen byte source model of Unicode UTF-8 is intended not to have the earlier mentioned issues for older multibyte Unicode characters. UTF-8, UTF-16, and UTF-32 enable the developer to realize that the application divisions of pre-defined length are distinct from the "characters"; however, the main problem is poorly built APIs to mask this distinction. ImplementationSeveral languages, such as Ruby and C++, enable a string's components to be updated after it has been developed; these are called mutable strings. The value is set in other languages, such as Java and Python, and must generate a new string if any changes are to be made. These are called permanent sequences (some of these languages also provide another mutable type, such as Java and .NET StringBuilder, the thread-safe Java String Buffer, and the Cocoa NS Mutable String). Usually, strings are configured as sequences of bytes, characters, or code items to allow easy access, excluding characters when they have a finite size, to separate groups or substrings. Alternatively, a couple of languages like Haskell incorporate them as relational databases. Representation of StringString representations are highly dependent on the availability of the text catalog and the conventional cryptographic system. Former implementations of strings were designed to operate with ASCII-defined catalog and encryption, or more modern enhancements such as the ISO (International Organizations for Standardizations) 8859 sequence. The Unicode's substantial accompaniment, together with a range of essential embedding like UTF-8 and UTF-16, is often used by advanced functionalities. The word byte string tends to indicate a sequence of bytes for specific purposes instead of the strings of only (readable) texts, strings of sections, or something like that. Byte strings also indicate that bytes may accept any input and therefore can retain any information which implies that neither value can be treated as a termination value. Some strings implement some implementations to sequences of variable lengths with inputs that store text codes for the respective strings. The significant difference is that a single rational text may occupy upwards of a single entry in the array of certain encryptions. For instance, it exists with UTF-8 since individual codes (UCS code assists) can occupy anything between one to four bytes. An infinite number of values can be used for unique characters. The string sequence (number of bits) varies from the actual size of the line in these situations (when the number of bytes is being used). UTF-32 avoids the first portion of the issue. 
A string can be represented in the below-mentioned forms. They are-
In both software and hardware, using a unique byte apart from zero for ending strings has historically appeared, however often with a value that's also a publishing character. "Several embedded systems use $ symbol: use CDC (Control data corporation) systems (it means the character had a zero value) and the use ZX80 "as this was the sequence substring in the BASIC language of the machine. "Data processing" devices such as IBM 1401 use a new acronym sign bit to delineate strings on the left side, in which the procedure will begin on the right side, quite identical. In most of the other portions of the sequence, this bit will have to be explicit. Although the IBM 1401 had a 7-bit code, absolutely nobody ever conceived of using this as a function to circumvent the seventh-bit designation (for instance) manage ASCII codes. Initially, microcomputer software pointed out that the elevated bit was not used in ASCII codes and configured it to signify a sequence's termination. Leading up to output, it must return it to 0 value.
Using a unique termination word, the duration of a sequence can be encoded impliedly; this is always the zero-value character (it means all bits contain zero value), a standard that the prominent C programming language uses and perpetuates. This formulation is also usually alluded to as a C string. The n-character string composition consumes n + 1 storage (1 is for the terminator) and seems to be, thus an implied data structure. In ended strings and in any string, the ending character is not an acceptable word. Length-field strings don't have this restriction and can contain specific binary information as well. For Example: Here, we have an instance in which a null-terminated sequence preserved as 8-bit hexadecimal digits in a 10-byte frame, together with its ASCII (or even more standard UTF-8) expression, is: 
The string size in the above illustration, 'DAVID,' is five words, but it takes 6 bytes in size. Characters do not appear to be an element of the interpretation after the terminator; they can be either component of any other data or only trash. (Strings of this type are often called ASCIZ sequence after being declared by the declaration's existing programming languages).
Several programming languages introduce strings via records through some structural properties, like object-oriented models, along with the following code: Although the implementation usually is secret, it is essential to manipulate and change the sequence via member variables. The input text refers to a system memory that is dynamically assigned, which can be extended as required.
It is also possible to directly save a string's size, such as by appending the string only with size as a byte value. In several Pascal accents, this pattern is used; several people call such a series a Pascal string or a P-string as a result. Saving the size of strings as bytes restricts the maximum length of strings to 255. Enhanced representations of Pascal-strings use 16-, 32-, or 64-bit terms to hold the string size to prevent certain restrictions. When the length field reaches the physical address, only the available storage restricts the strings. If the size is limited, it can be encrypted in steady storage. Usually, a computer term, resulting in an implied data structure, using n+k storage, here k is the number of characters in a text (8 on a 64-bit system representing 8-bit ASCII, one on the 32-bit UTF-32/UCS-4 on a 32-bit system, etc.). Encrypting a size n requires log(n) memory if the size is not constrained, so length-prefixed sequences are a concise data structure, encrypting a string of size n in log(n) + n memory. There is no fixed size in the size-prefix field alone in the above situation, but as the sequence developed, the individual string value must be shifted so that the sequence number has to be expanded. Below is a Pascal string placed including its ASCII / UTF-8 expression in a 10-byte buffer: 
Either text elimination or length codes restrict sequences: C language character arrays contain null values. For instance, they cannot be explicitly treated by the C string library's operations: strings with a size value are constrained to the maximum sized code value. By creative programming, both of the above drawbacks can be resolved. Here, we have some different representations of string in several languages- String Representation in 'C' LanguageAs we know, C programming does not enable a character type parameter to hold over than a single character. In C programming, the below-given examples are therefore incorrect and generate syntax errors. As we have seen before, the array's idea is to save in a variable over than single value of a particular data type. Here we have the syntactical structure for storing and printing five digits in an integer-type sequence. After the successful execution of the above code syntax, we got the below-given output. 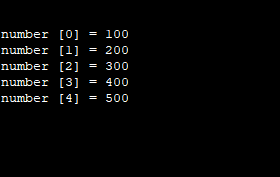
String Representation in Java ProgrammingWhile you can preserve strings using character sequences, Java is a specialized programming language, and its developers have attempted to include advanced capabilities. As a pre-defined data type, Java offers strings like every other data type. It implies that you can explicitly describe strings rather than describing them as a text sequence. For Example- Here, we have a program in java to print "Hello Java." In the below- discussed program code, Java uses a new operator to generate a unique string sequence. After the successful execution of the above program code, you got the following output on the screen. 
String Representation in Python LanguageGenerating and representing strings in Python programming is as convenient as using single or double quotations to allocate a Python variable sequence. For Example- Here, we have a basic program in python to create and print two string sequences with the help of print() function. After the execution of the above code, you got the below output. 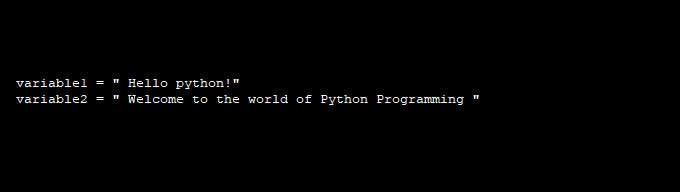
The Python language does not support character type; these are viewed as sequences of size one, often called a substring-using the square brackets for cutting together with the list of indexes to reach substrings to get the substring. Take a look at the program code section below. Program code You got the following result after the successful execution of the above code. 
Next Topic500 Internal Server Error
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








