| |

Data Warehouse ArchitectureA data warehouse architecture is a method of defining the overall architecture of data communication processing and presentation that exist for end-clients computing within the enterprise. Each data warehouse is different, but all are characterized by standard vital components. Production applications such as payroll accounts payable product purchasing and inventory control are designed for online transaction processing (OLTP). Such applications gather detailed data from day to day operations. Data Warehouse applications are designed to support the user ad-hoc data requirements, an activity recently dubbed online analytical processing (OLAP). These include applications such as forecasting, profiling, summary reporting, and trend analysis. Production databases are updated continuously by either by hand or via OLTP applications. In contrast, a warehouse database is updated from operational systems periodically, usually during off-hours. As OLTP data accumulates in production databases, it is regularly extracted, filtered, and then loaded into a dedicated warehouse server that is accessible to users. As the warehouse is populated, it must be restructured tables de-normalized, data cleansed of errors and redundancies and new fields and keys added to reflect the needs to the user for sorting, combining, and summarizing data. Data warehouses and their architectures very depending upon the elements of an organization's situation. Three common architectures are:
Data Warehouse Architecture: Basic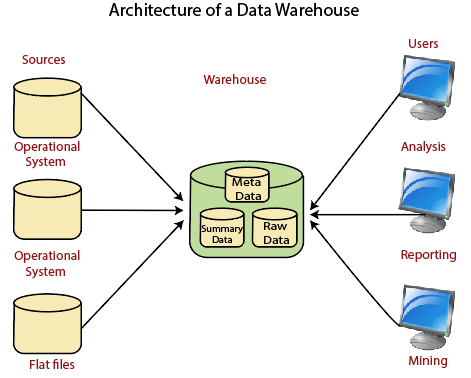
Operational System An operational system is a method used in data warehousing to refer to a system that is used to process the day-to-day transactions of an organization. Flat Files A Flat file system is a system of files in which transactional data is stored, and every file in the system must have a different name. Meta Data A set of data that defines and gives information about other data. Meta Data used in Data Warehouse for a variety of purpose, including: Meta Data summarizes necessary information about data, which can make finding and work with particular instances of data more accessible. For example, author, data build, and data changed, and file size are examples of very basic document metadata. Metadata is used to direct a query to the most appropriate data source. Lightly and highly summarized data The area of the data warehouse saves all the predefined lightly and highly summarized (aggregated) data generated by the warehouse manager. The goals of the summarized information are to speed up query performance. The summarized record is updated continuously as new information is loaded into the warehouse. End-User access Tools The principal purpose of a data warehouse is to provide information to the business managers for strategic decision-making. These customers interact with the warehouse using end-client access tools. The examples of some of the end-user access tools can be:
Data Warehouse Architecture: With Staging AreaWe must clean and process your operational information before put it into the warehouse. We can do this programmatically, although data warehouses uses a staging area (A place where data is processed before entering the warehouse). A staging area simplifies data cleansing and consolidation for operational method coming from multiple source systems, especially for enterprise data warehouses where all relevant data of an enterprise is consolidated. 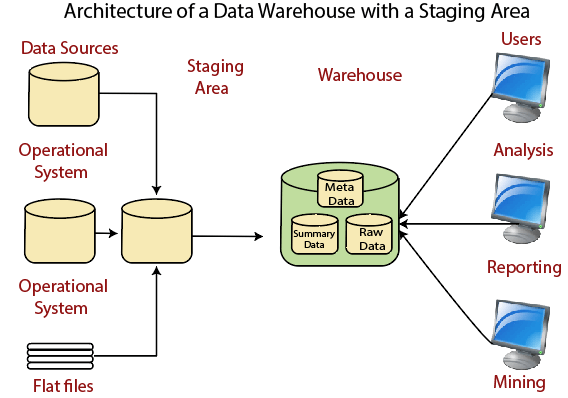
Data Warehouse Staging Area is a temporary location where a record from source systems is copied. 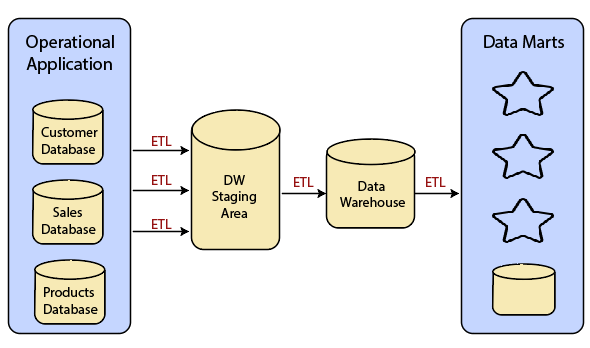
Data Warehouse Architecture: With Staging Area and Data MartsWe may want to customize our warehouse's architecture for multiple groups within our organization. We can do this by adding data marts. A data mart is a segment of a data warehouses that can provided information for reporting and analysis on a section, unit, department or operation in the company, e.g., sales, payroll, production, etc. The figure illustrates an example where purchasing, sales, and stocks are separated. In this example, a financial analyst wants to analyze historical data for purchases and sales or mine historical information to make predictions about customer behavior. 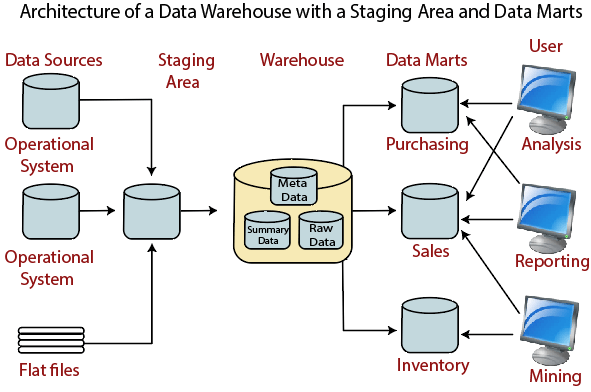
Properties of Data Warehouse ArchitecturesThe following architecture properties are necessary for a data warehouse system: 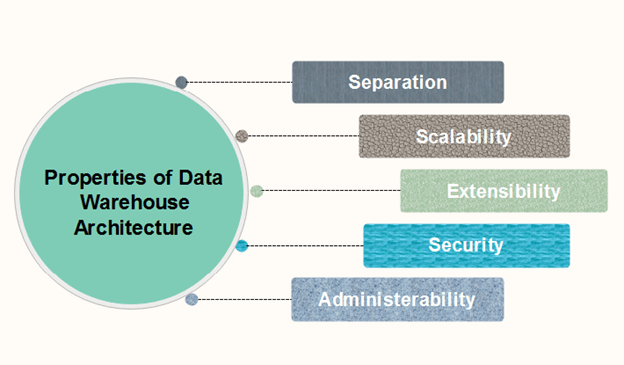
1. Separation: Analytical and transactional processing should be keep apart as much as possible. 2. Scalability: Hardware and software architectures should be simple to upgrade the data volume, which has to be managed and processed, and the number of user's requirements, which have to be met, progressively increase. 3. Extensibility: The architecture should be able to perform new operations and technologies without redesigning the whole system. 4. Security: Monitoring accesses are necessary because of the strategic data stored in the data warehouses. 5. Administerability: Data Warehouse management should not be complicated. Types of Data Warehouse Architectures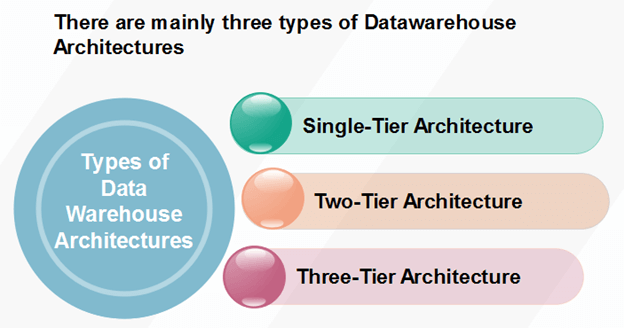
Single-Tier ArchitectureSingle-Tier architecture is not periodically used in practice. Its purpose is to minimize the amount of data stored to reach this goal; it removes data redundancies. The figure shows the only layer physically available is the source layer. In this method, data warehouses are virtual. This means that the data warehouse is implemented as a multidimensional view of operational data created by specific middleware, or an intermediate processing layer. 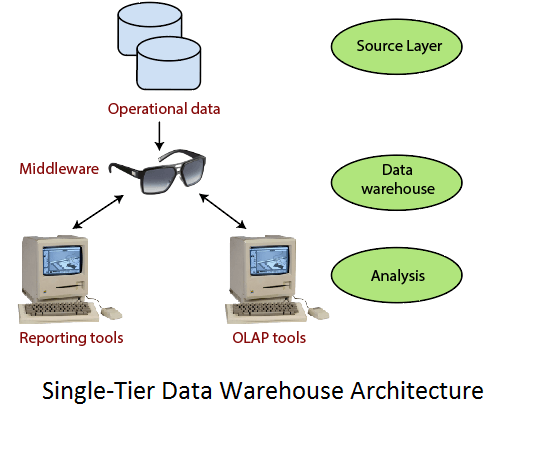
The vulnerability of this architecture lies in its failure to meet the requirement for separation between analytical and transactional processing. Analysis queries are agreed to operational data after the middleware interprets them. In this way, queries affect transactional workloads. Two-Tier ArchitectureThe requirement for separation plays an essential role in defining the two-tier architecture for a data warehouse system, as shown in fig: 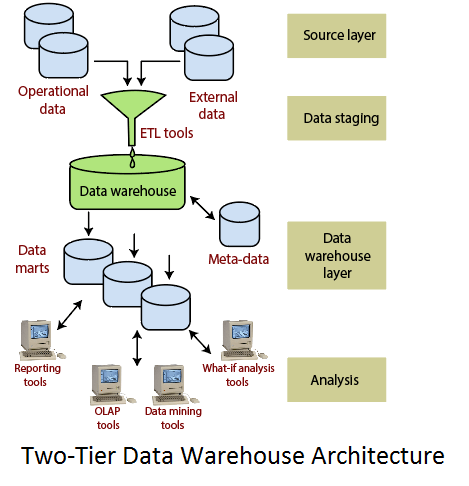
Although it is typically called two-layer architecture to highlight a separation between physically available sources and data warehouses, in fact, consists of four subsequent data flow stages:
Three-Tier ArchitectureThe three-tier architecture consists of the source layer (containing multiple source system), the reconciled layer and the data warehouse layer (containing both data warehouses and data marts). The reconciled layer sits between the source data and data warehouse. The main advantage of the reconciled layer is that it creates a standard reference data model for a whole enterprise. At the same time, it separates the problems of source data extraction and integration from those of data warehouse population. In some cases, the reconciled layer is also directly used to accomplish better some operational tasks, such as producing daily reports that cannot be satisfactorily prepared using the corporate applications or generating data flows to feed external processes periodically to benefit from cleaning and integration. This architecture is especially useful for the extensive, enterprise-wide systems. A disadvantage of this structure is the extra file storage space used through the extra redundant reconciled layer. It also makes the analytical tools a little further away from being real-time. 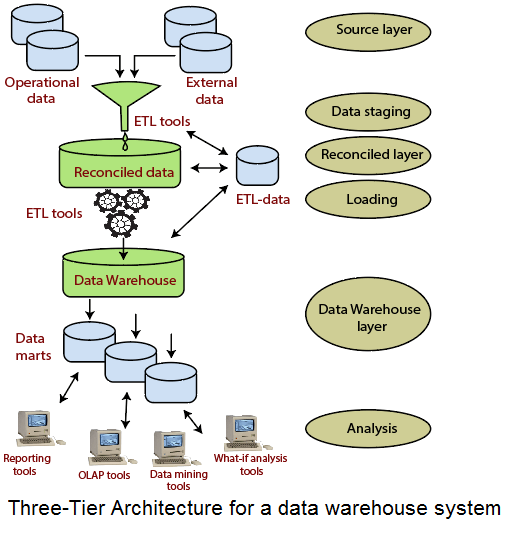
Next TopicThree-Tier Data Warehouse Architecture
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








