| |

Informatica BDMInformatica Big Data Management (BDM) product is a GUI based integrated development tool. This tool is used by organizations to build Data Quality, Data Integration, and Data Governance processes for their big data platforms. Informatica BDM has built-in Smart Executor that supports various processing engines such as Apache Spark, Blaze, Apache Hive on Tez, and Apache Hive on MapReduce. Informatica BDM is used to perform data ingestion into a Hadoop cluster, data processing on the cluster, and extraction of data from the Hadoop cluster. In Blaze mode, the Informatica mapping is processed by BlazeTM - Informatica's native engine that runs as a YARN based application. In Spark mode, the Informatica mappings are translated into Scala code. In Hive and MapReduce mode, Informatica's mappings are translated into MapReduce code and are executed natively to the Hadoop cluster. Informatica BDM integrates seamlessly with the Hortonworks Data Platform (HDP) Hadoop cluster in all related aspects, including its default authorization system. Ranger can be used to enforce a fine-grained role-based authorization to data as well as metadata stored inside the HDP cluster. Informatica's BDM integrates with Ranger in all modes of execution. Informatica's BDM has a Smart Executor that enables organizations to run their Informatica mappings seamlessly on one or more methods of implementation under the purview of their existing security setup. AuthenticationAuthentication is the process of dependably ensuring the user is who claims to be. Kerberos is the widely accepted authentication mechanism on Hadoop, including the Hortonworks Data Platform. Kerberos protocol relies on a Key Distribution Center (KDC), a network service that issues tickets permitting access. Informatica BDM supports Kerberos authentication on both Active directory and MIT-based key distribution centers. Kerberos authentication is supported by all modes of execution in Informatica BDM. AuthorizationAuthorization is the process of determining whether a user has access to perform certain operations on a given system or not. In HDP Hadoop clusters, authorization plays a vital role in ensuring the users access only the data that they are allowed to by the Hadoop administrator. 1. Blaze- YARN ApplicationWhen executing mappings on Informatica Blaze, optimizer first makes an invocation to Hadoop Service to fetch metadata information such as the hive table's partitioning details. 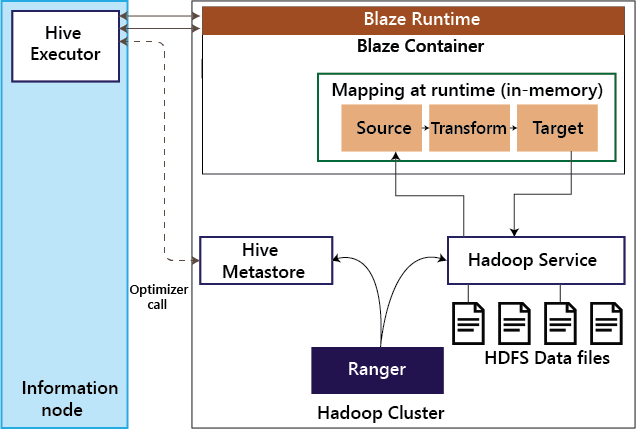
Then the job is submitted to Blaze Runtime. The illustration represents how Blaze interacts with the Hadoop Service, such as Hive Server 2. When an Informatica mapping gets executed in Blaze mode, then call is made to the Hive Metastore to understand the structure of the tables. The Blaze runtime then loads the optimized mapping into memory. This mapping then interacts with the corresponding Hadoop service to read the data or write the data. The Hadoop service itself is integrated with Ranger and ensures the authorization is taken place before the request is served. 2. SparkInformatica BDM can execute mappings as Spark's Scala code on the HDP Hadoop cluster. The illustration details different steps involved when using Spark execution mode. 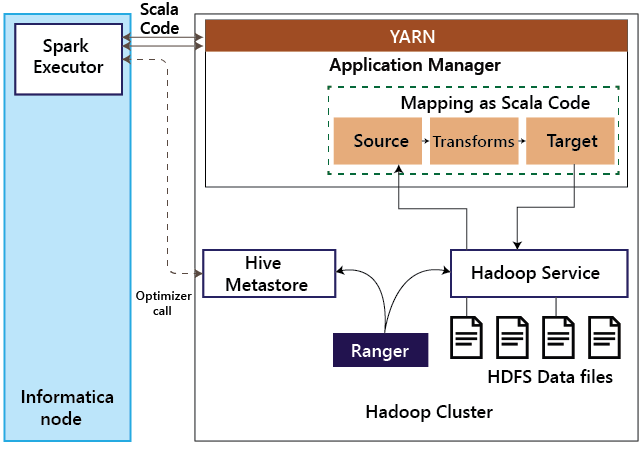
The Spark executor translates Informatica's mappings into the Spark Scala code. As part of this translation, if Hive sources or targets are involved, then Spark executor makes a call to Hive metastore to understand the structure of the Hive tables and optimize the Scala code. Then, this Scala code is submitted to YARN for execution. When the Spark code accesses the data, the corresponding Hadoop service relies on Ranger for authorization. 3. Hive on MapReduceInformatica BDM can execute mappings as MapReduce code on the Hadoop cluster. Below illustration steps involved Hive on MapReduce mode. 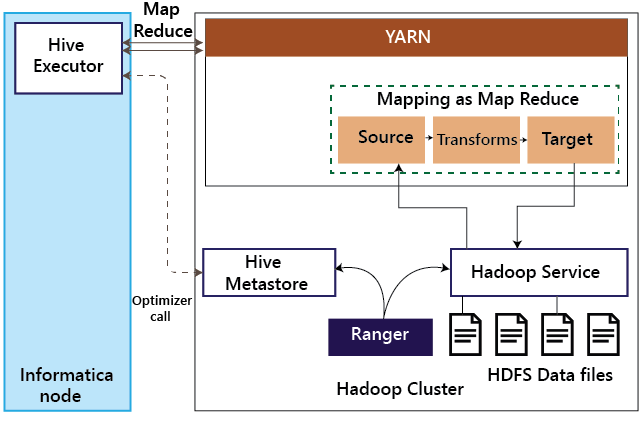
When a mapping is executed in Hive on MapReduce mode, the Hive executor on the Informatica node translates the Informatica mapping into MapReduce and submits the job to the Hadoop cluster. If Hive sources or targets are involved, the Hive executor makes a call to the Hive Meta store to understand the table structure and accordingly optimize the mapping. As the MapReduce interacts with Hadoop services such as HDFS and Hive, the Hadoop service authorizes the requests with Ranger. 4. Hive on TezTez can be enabled in Informatica BDM by a configuration change and is transparent to the mapping developed. 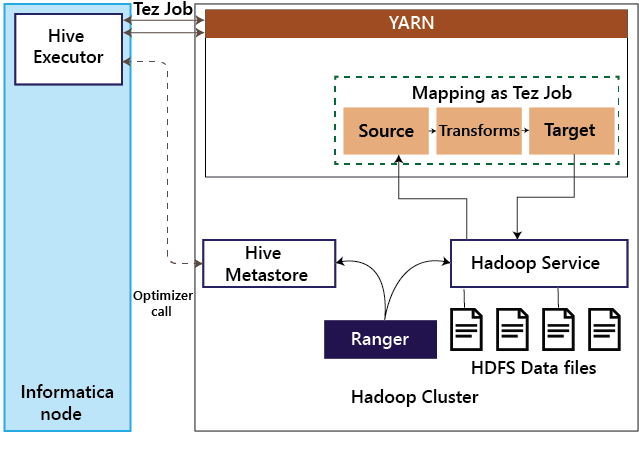
Hence mappings running on Hive on Tez follow a similar pattern as Hive on MapReduce. When a mapping is executed in the Hive on Tez mode, the Hive executor on the Informatica node translates the Informatica mapping into Tez job and submits it to the Hadoop cluster. If Hive sources or targets are involved, the Hive executor makes a call to the Hive Meta store to understand the table structure and accordingly optimize the mapping. As the Tez job interacts with Hadoop services such as HDFS and Hive, the Hadoop service authorizes the requests with Ranger.
Next TopicPartitioning in Informatica
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








