| |

OpenCV Tutorial | OpenCV using PythonOpenCV tutorial explains both fundamental and sophisticated OpenCV concepts. Our OpenCV course is intended for both novices and experts. An open-source computer vision library is called OpenCV. It gives the system the ability to identify faces or other objects. Using the Python programming language, we will master the fundamentals of OpenCV in this lesson. The entire range of topics covered in our OpenCV tutorial is covered, including Read and Save Images, Canny Edge Detection, Template Matching, Blob Detection, Contour, Mouse Event, Gaussian Blur, and others. What is OpenCV?
OpenCV is a Python open-source library for computer vision in artificial intelligence, machine learning, facial recognition, etc. The term "computer vision" (abbreviated as "CV") in OpenCV refers to a branch of research that enables computers to comprehend the content of digital images like pictures and movies. To comprehend the content of the images is the goal of computer vision. It takes the description of the images-which may be of an object, a text description, a three-dimensional model, etc.-and extracts it from the images. Computer vision, for instance, can help cars by enabling them to recognize various roadside items, such as pedestrians, traffic signs, and traffic lights, and then respond appropriately. 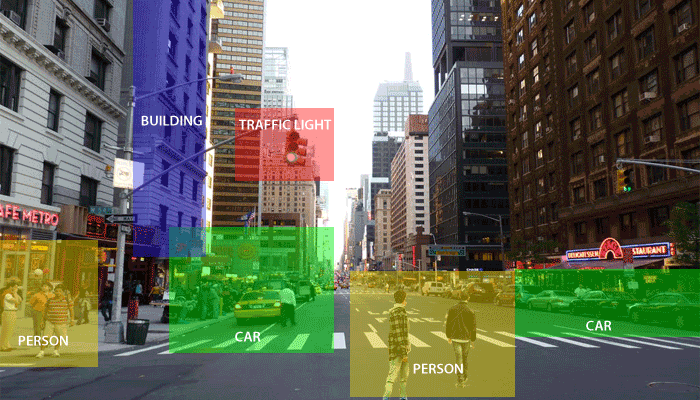
The same types of work humans perform can be completed by computers just as effectively, thanks to computer vision. Two primary tasks are listed below and are defined as follows:
HistoryOpenCV stands for Open-Source Computer Vision Library, widely used for image recognition or identification. It was officially launched in 1999 by Intel. It was written in C/C++ in the early stage, but now it is also commonly used in Python for computer vision. At the IEEE Conference on Computer Vision and Pattern Recognition in 2000, the first alpha version of OpenCV was made available for general usage. From 2001 to 2005, five beta versions were made available. In 2006, the initial 1.0 version was released. In October 2009, the critical updates to OpenCV's second version were released. The second edition's C++ interface has significantly changed to facilitate better, easier, and more type-safe implementations. An independent Russian team develops the software and publishes a new version every six months. How OpenCV WorksIn this tutorial, we will learn how computers perform image recognition. How does the Computer Recognize the Image?Human eyes provide a lot of information based on what they observe. Machines can observe everything, translate that vision into numbers, and store those numbers in memory. Here, the issue of how computers translate visuals into numbers arises. The pixel value is utilized to translate images into numbers, which is the answer. A pixel is a minor component of a digital picture or graphic that can be shown on a digital display device. 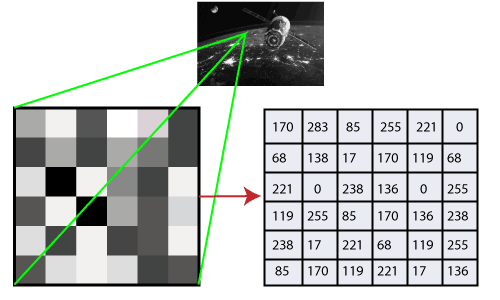
The numbers show how bright the image is at that specific location. In the image above, we've demonstrated how a grayscale image's pixel values comprise just one value-the intensity of the black color there. There are two typical techniques to recognize the pictures: 1. Grayscale: Images that just include the two colors black and white are known as grayscale images. Black is considered to have the lowest intensity, whereas white has the highest, according to the contrast assessment of intensity. The computer gives each pixel in the grayscale image a value dependent on how dark it is when we use it. 2. RGB: An RGB is a mixture of red, green, and blue that results in a new color. The computer extracts Each pixel's value, which then organizes the information into an array for interpretation. 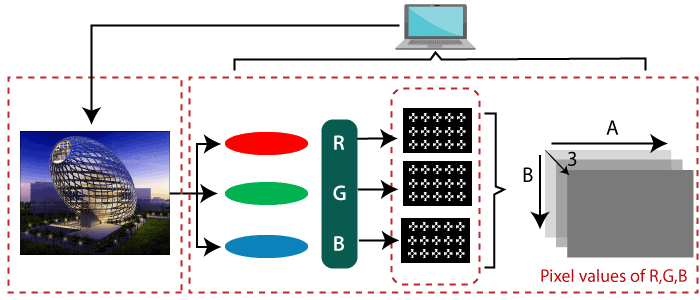
Why OpenCV is used for Computer Vision?
PrerequisiteYou must have a foundational understanding of Python programming before learning OpenCV. AudienceBoth beginners and experts can benefit from the information in our OpenCV lesson. ProblemWe assure that you will not find any problem in this OpenCV tutorial. But if there is any mistake, please post the problem in contact form.
Next TopicOpenCV Installation
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








