Huffman Coding Algorithm
Data may be compressed using the Huffman Coding technique to become smaller without losing any of its information. After David Huffman, who created it in the beginning? Data that contains frequently repeated characters is typically compressed using Huffman coding.
A well-known Greedy algorithm is Huffman Coding. The size of code allocated to a character relies on the frequency of the character, which is why it is referred to be a greedy algorithm. The short-length variable code is assigned to the character with the highest frequency, and vice versa for characters with lower frequencies. It employs a variable-length encoding, which means that it gives each character in the provided data stream a different variable-length code.
Prefix Rule
Essentially, this rule states that the code that is allocated to a character shall not be another code's prefix. If this rule is broken, various ambiguities may appear when decoding the Huffman tree that has been created.
Let's look at an illustration of this rule to better comprehend it: For each character, a code is provided, such as:
Assuming that the produced bit stream is 001, the code may be expressed as follows when decoded:
What is the Huffman Coding process?
The Huffman Code is obtained for each distinct character in primarily two steps:
- Create a Huffman Tree first using only the unique characters in the data stream provided.
- Second, we must proceed through the constructed Huffman Tree, assign codes to the characters, and then use those codes to decode the provided text.
Steps to Take in Huffman Coding
The steps used to construct the Huffman tree using the characters provided
If Huffman Coding is employed in this case for data compression, the following information must be determined for decoding:
- For each character, the Huffman Code
- Huffman-encoded message length (in bits), average code length
- Utilizing the formulas covered below, the final two of them are discovered.
How Can a Huffman Tree Be Constructed from Input Characters?
The frequency of each character in the provided string must first be determined.
| Character |
Frequency |
| a |
4 |
| b |
7 |
| c |
3 |
| d |
2 |
| e |
4 |
- Sort the characters by frequency, ascending. These are kept in a Q/min-heap priority queue.
- For each distinct character and its frequency in the data stream, create a leaf node.
- Remove the two nodes with the two lowest frequencies from the nodes, and the new root of the tree is created using the sum of these frequencies.
- Make the first extracted node its left child and the second extracted node its right child while extracting the nodes with the lowest frequency from the min-heap.
- To the min-heap, add this node.
- Since the left side of the root should always contain the minimum frequency.
- Repeat steps 3 and 4 until there is only one node left on the heap, or all characters are represented by nodes in the tree. The tree is finished when just the root node remains.
Examples of Huffman Coding
Let's use an illustration to explain the algorithm:
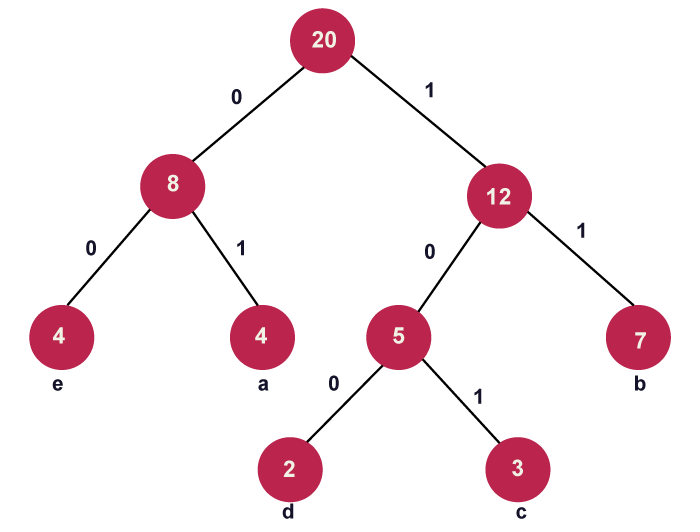
Algorithm for Huffman Coding
Step 1: Build a min-heap in which each node represents the root of a tree with a single node and holds 5 (the number of unique characters from the provided stream of data).

Step 2: Obtain two minimum frequency nodes from the min heap in step two. Add a third internal node, frequency 2 + 3 = 5, which is created by joining the two extracted nodes.
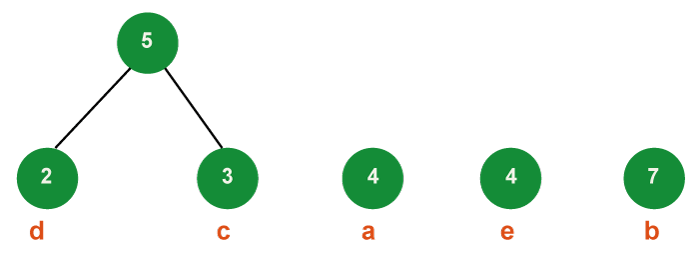
- Now, there are 4 nodes in the min-heap, 3 of which are the roots of trees with a single element each, and 1 of which is the root of a tree with two elements.
Step 3: Get the two minimum frequency nodes from the heap in a similar manner in step three. Additionally, add a new internal node formed by joining the two extracted nodes; its frequency in the tree should be 4 + 4 = 8.
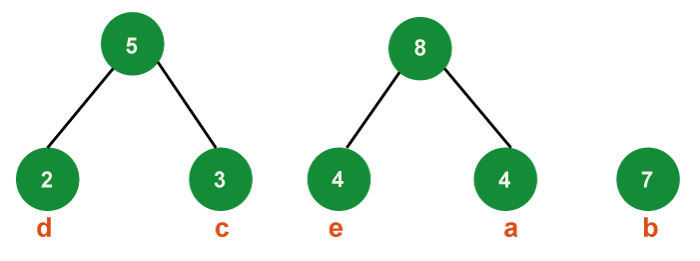
- Now that the minimum heap has three nodes, one node serves as the root of trees with a single element and two heap nodes serve as the root of trees with multiple nodes.
Step 4: Get the two minimum frequency nodes in step four. Additionally, add a new internal node formed by joining the two extracted nodes; its frequency in the tree should be 5 + 7 = 12.
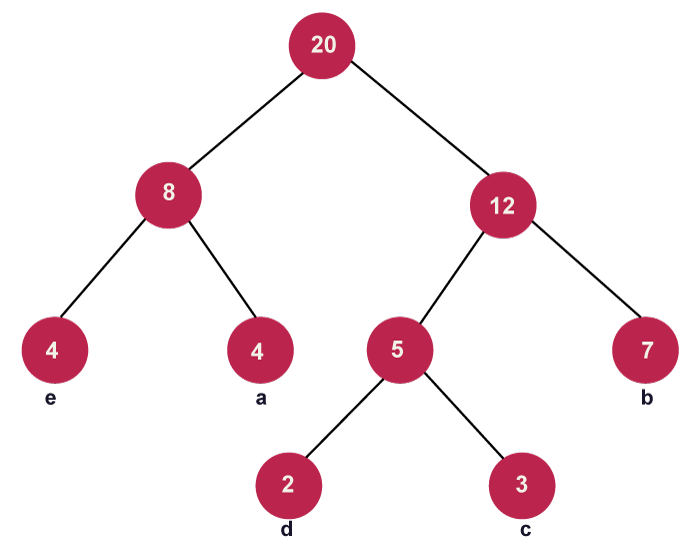
- When creating a Huffman tree, we must ensure that the minimum value is always on the left side and that the second value is always on the right side. Currently, the image below shows the tree that has formed:
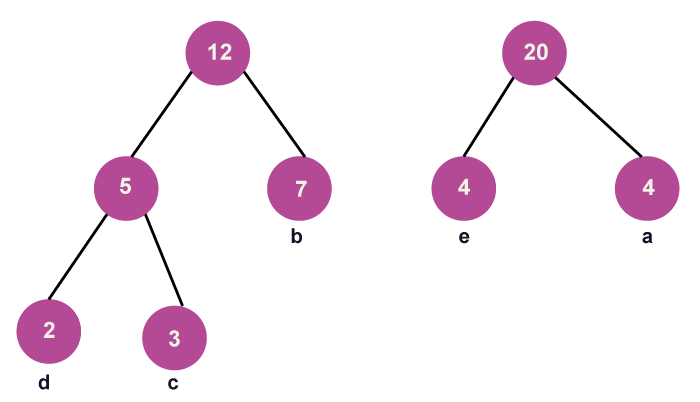
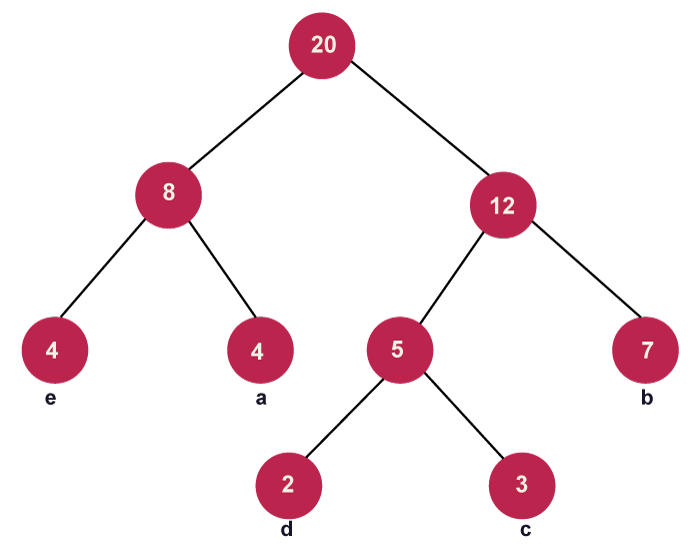
Step 5: Get the following two minimum frequency nodes in step 5. Additionally, add a new internal node formed by joining the two extracted nodes; its frequency in the tree should be 12 + 8 = 20.
Continue until all of the distinct characters have been added to the tree. The Huffman tree created for the specified cast of characters is shown in the above image.
Now, for each non-leaf node, assign 0 to the left edge and 1 to the right edge to create the code for each letter.
Rules to follow for determining edge weights:
- We should give the right edges weight 1 if you give the left edges weight 0.
- If the left edges are given weight 1, the right edges must be given weight 0.
- Any of the two aforementioned conventions may be used.
- However, follow the same protocol when decoding the tree as well.
Following the weighting, the modified tree is displayed as follows:
Understanding the Code
- We must go through the Huffman tree until we reach the leaf node, where the element is present, in order to decode the Huffman code for each character from the resulting Huffman tree.
- The weights across the nodes must be recorded during traversal and allocated to the items located at the specific leaf node.
- The following example will help to further illustrate what we mean:
- To obtain the code for each character in the picture above, we must walk the entire tree (until all leaf nodes are covered).
- As a result, the tree that has been created is used to decode the codes for each node. Below is a list of the codes for each character:
| Character |
Frequency/count |
Code |
| a |
4 |
01 |
| b |
7 |
11 |
| c |
3 |
101 |
| d |
2 |
100 |
| e |
4 |
00 |
Below is implementation in C programming:
Output
f: 0
c: 100
d: 101
a: 1100
b: 1101
e: 111
……………
Process executed in 1.11 seconds
Press any key to continue.
Java Implementation of above code:
Output
f: 0
c: 100
d: 101
a: 1100
b: 1101
e: 111
……………….
Process executed in 1.11 seconds
Press any key to continue.
Explanation:
By traversing, the Huffman Tree is created and decoded. The values gathered during the traversal are then to be applied to the character located at the leaf node. Every unique character in the supplied stream of data may be identified using the Huffman Code in this manner. O (nlogn), where n is the total number of characters, is the time complexity. ExtractMin() is called 2*(n - 1) times if there are n nodes. Since extractMin() calls minHeapify(), its execution time is O (logn). The total complexity is therefore O (nlogn). There is a linear time algorithm if the input array is sorted. This will be covered in more detail in our upcoming piece.
Problems with Huffman Coding
Let's talk about the drawbacks of Huffman coding in this part and why it isn't always the best option:
- If not all of the characters' probabilities or frequencies are negative powers of 2, it is not regarded as ideal.
- Although one may get closer to the ideal by grouping symbols and expanding the alphabet, the blocking method necessitates handling a larger alphabet. Therefore, Huffman coding may not always be very effective.
- Although there are many effective ways to count the frequency of each symbol or character, reconstructing the entire tree for each one can be very time-consuming. When the alphabet is large and the probability distributions change quickly with each symbol, this is typically the case.
Greedy Huffman Code Construction Algorithm
- Huffman developed a greedy technique that generates a Huffman Code, an ideal prefix code, for each distinct character in the input data stream.
- The approach uses the fewest nodes each time to create the Huffman tree from the bottom up.
- Because each character receives a length of code based on how frequently it appears in the given stream of data, this method is known as a greedy approach. It is a commonly occurring element in the data if the size of the code retrieved is less.
The use of Huffman Coding
- Here, we'll talk about some practical uses for Huffman Coding:
- Conventional compression formats like PKZIP, GZIP, etc. typically employ Huffman coding.
- Huffman Coding is used for data transfer by fax and text because it minimizes file size and increases transmission speed.
- Huffman encoding (particularly the prefix codes) is used by several multimedia storage formats, including JPEG, PNG, and MP3, to compress the files.
- Huffman Coding is mostly used for image compression.
- When a string of often recurring characters has to be sent, it can be more helpful.
Conclusion
- In general, Huffman Coding is helpful for compressing data that contains frequently occurring characters.
- We can see that the character that occurs most frequently has the shortest code, whereas the one that occurs the least frequently has the greatest code.
- The Huffman Code compression technique is used to create variable-length coding, which uses a varied amount of bits for each letter or symbol. This method is superior to fixed-length coding since it uses less memory and transmits data more quickly.
- Go through this article to have a better knowledge of the greedy algorithm.
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








