| |

Sorting Algorithms: Slowest to FastestIn the following tutorial, we will discuss the different sorting algorithms and compare them on the basis of their complexities. So, let's get started. What is a Sorting Algorithm?The sorting Algorithm is a set of instructions that accepts an array or list as an input and arranges the data elements into a specific order. Sorts are most commonly in numerical or a form of alphabetical (or lexicographical) format, and the sorting order can either be ascending (0 - 9, A - Z) or descending (9 - 0, Z - A). Understanding the Importance of Sorting AlgorithmsSorting Algorithms serve a significant role in Computer Science, as they can often reduce the complexity of a problem. These algorithms have direct applications in searching algorithms, database management algorithms, data structure algorithms, divide and conquer methods, and many more. Some of the best examples of real-world implementation of the sorting algorithms are:
Understanding the Types of Sorting in Data StructuresThe sorting Technique in Data Structures is divided into types:
At the same time, the Not-in-Place sorting techniques make use of an auxiliary data structure in order to sort the original array. Some examples of In-Place sorting techniques are Bubble Sort and Selection Sort. Some examples of Not-in-Place sorting algorithms are Merge Sort and Quick Sort. Some Common Sorting AlgorithmsThe following is the list of some commonly used Sorting Algorithms:
Let us examine the above sorting algorithms with their time and space complexities to determine the fastest Sorting Algorithm. Bubble SortBubble Sort is the simplest sorting algorithm. The fundamental concept behind bubble sorting is that it repeatedly swaps adjacent data elements if they are not in the desired order. Suppose a given array of data elements has to be sorted in ascending order. In that case, bubble sort will start by comparing the first data element of the array with the second one and immediately swap them if it turns out to be a larger value than the second element, and then move on to comparing the second and third data elements, and so on. Let us understand the intuitive approach behind the bubble sort using an example: Example: Suppose we are given an array of five different data elements arranged unsorted.
We will now use the bubble sort to arrange these data elements of the array in ascending order. First Iteration:
The bubble sort compares the first two data elements and swaps since 5 is greater than 3 (5 > 3).
Second Iteration:
Third Iteration:
Fourth Iteration:
Now that we have understood the intuitive concept behind the bubble sort, it is time for us to consider its standard implementation in C++ Programming Language. Implementation of Bubble Sort in C++Output: Unsorted Array : 5 3 4 2 1 Sorted Array : 1 2 3 4 5 Explanation: In the above code snippet, we included the 'bits/stdc++.h' header file and used the standard namespace. We have then defined the void function as BubbleSort(), which accepts two arguments - array name and its size. Inside this function, we have defined two iterables, i and j. We have used the nested for-loop to iterate through each element of the array, compare the current element's value with the next element, and swap their positions if it is larger. Now inside the main function, we have defined and initialized an unsorted array as arr. We then calculated its size. We have also printed the elements of the unsorted array for the users. We have then called the BubbleSort() function by passing the array name, i.e., arr, and its size. At last, we have printed the sorted array elements for the users. As a result, the given array, i.e., (5, 3, 4, 2, 1), is sorted into ascending order as (1, 2, 3, 4, 5). Performance Analysis of Bubble Sort Let us now observe the Time complexity of Bubble Sort in the best case, average case, and worst case. We will also observe the Space complexity of Bubble Sort. Time Complexity:
Auxiliary Space Complexity: O(1) Some Applications of Bubble Sort The following are some applications of Bubble Sort:
Selection SortSelection Sort is a sorting algorithm where the given array is divided into two sub-arrays -
Primarily, the sorted segment remains empty whereas the unsorted segment contains the complete list. In each iteration, we will fetch the smallest data element from the unsorted sub-array and push it to the end of the sorted sub-array. Thus, we can successfully construct our sorted array. Let us understand the intuitive approach behind the selection sort using an example: Example: Suppose we are given an array of five different data elements arranged unsorted.
We will now use the selection sort to arrange these data elements of the array in ascending order.
Therefore, we will get the following array: (16, 26, 23, 28, 18)
Therefore, we will now get the following array: (16, 18, 26, 23, 28)
Therefore, we will now get the following array: (16, 18, 23, 26, 28)
Therefore, we will now get the following array: (16, 18, 23, 26, 28)
Hence, the final sorted array will be: (16, 18, 23, 26, 28) Now that we have understood the intuitive concept behind the selection sort, it is time for us to consider its standard implementation in C++ Programming Language. Implementation of Selection Sort in C++Output: Unsorted Array : 25 23 28 16 18 Sorted Array : 16 18 23 25 28 Explanation: In the above code snippet, we included the 'bits/stdc++.h' header file and used the standard namespace. We have then defined the void function as SelectionSort(), which accepts two arguments - array name and its size. Inside this function, we have defined two iterables, i and j and a variable as curr. We have used the nested for-loop to iterate through each element of the array. Inside the first for-loop, we have initialized the curr variable as the current value of index i. Inside the second for-loop, we have compared the element value at index j is less than element at position curr and called the swap() function to swap their positions if it is larger. Now inside the main function, we have defined and initialized an unsorted array as arr. We then calculated its size. We have also printed the elements of the unsorted array for the users. We have then called the SelectionSort() function by passing the array name, i.e., arr, and its size. At last, we have printed the sorted array elements for the users. As a result, the given array, i.e., (25, 23, 28, 16, 18), is sorted into ascending order as (16, 18, 23, 25, 28). Performance Analysis of Selection SortLet us now observe the Time complexity of Selection Sort in the best case, average case, and worst case. We will also observe the Space complexity of Selection Sort. Time Complexity:
Auxiliary Space Complexity: O(1) Some Applications of Selection Sort The following are some applications of Selection Sort:
Insertion SortInsertion Sort is a sorting algorithm in which the given array is divided into a sorted and an unsorted segment. In each iteration, we have to find the optimal position of the data element to be inserted in the sorted subsequence and then insert it while shifting the remaining data elements to the right side. Let us understand the intuitive approach behind the insertion sort using an example: Example: Suppose we are given an array of five different data elements arranged unsorted.
We will now use the insertion sort to arrange these data elements of the array in ascending order.
Therefore, we will get the following array: (23, 26, 28, 16, 18)
Therefore, our array will remain unchanged: (23, 26, 28, 16, 18)
Therefore, we will get the following array: (16, 23, 26, 28, 18)
Hence, the final sorted array will be: (16, 18, 23, 26, 28) Now that we have understood the intuitive concept behind the insertion sort, it is time for us to consider its standard implementation in C++ Programming Language. Implementation of Insertion Sort in C++Output: Unsorted Array : 25 23 28 16 18 Sorted Array : 16 18 23 25 28 Explanation: We included the 'bits/stdc++.h' header file in the above code snippet and used the standard namespace. We have then defined the void function as InsertionSort(), which accepts two arguments - array name and its size. Inside this function, we have defined two iterables, i and j, and a variable as the temp. We have used the for-loop to iterate through each element of the array. Inside this, we have initialized the temp variable as the value at arr[i] and iterable j as the value preceding that of i. We then used the while loop to compare the element value at index j and temp and swap their positions if larger. Now inside the main function, we have defined and initialized an unsorted array as arr. We then calculated its size. We have also printed the elements of the unsorted array for the users. We have then called the InsertionSort() function by passing the array name, i.e., arr, and its size. At last, we have printed the sorted array elements for the users. As a result, the given array, i.e., (25, 23, 28, 16, 18), is sorted into ascending order as (16, 18, 23, 25, 28). Performance Analysis of Insertion Sort Let us now observe the Time complexity of Insertion Sort in the best case, average case, and worst case. We will also observe the Space complexity of Insertion Sort. Time Complexity:
Auxiliary Space Complexity: O(1) Some Applications of Insertion Sort The following are some applications of Insertion Sort:
Quick SortQuick Sort is a sorting algorithm that works on the divide and conquer approach. The instinctive concept behind this sorting technique is it chooses a data element as the pivot from a given array of data elements and then partitions the array around that pivot data element. Consequently, it calls itself recursively portioning the two subarrays afterward. Let us understand the intuitive approach behind the quick sort using an example: Example: 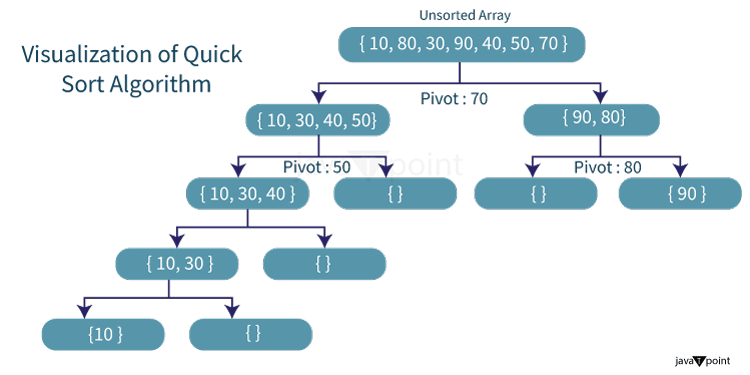
The logical steps included in the Quick Sort algorithm are as shown below:
Now that we have understood the intuitive concept behind the quick sort, it is time for us to consider its standard implementation in C++ Programming Language. Implementation of Quick Sort in C++Output: Unsorted Array : 25 23 28 16 18 Sorted Array : 16 18 23 25 28 Explanation: We included the 'bits/stdc++.h' header file in the above code snippet and used the standard namespace. We have then defined the function as partition_array() to partition the array around the pivot element. This function accepts three arguments - array name, start point, and end point. Inside this function, we have initialized a value of the pivot element and defined an iterable for iteration. We then used the for-loop to iterate through the elements and swap the elements to sort the array. We have then defined the void function as QuickSort(), which accepts three arguments - array name, start point, and end point. Inside this function, we have compared if the starting point is lower than the ending point and called the partition_array() function. We have then recursively called the QuickSort() function. Now inside the main function, we have defined and initialized an unsorted array as arr. We then calculated its size. We have also printed the elements of the unsorted array for the users. We then called the QuickSort() function by passing the array name and starting and ending points. At last, we have printed the sorted array elements for the users. As a result, the given array, i.e., (25, 23, 28, 16, 18), is sorted into ascending order as (16, 18, 23, 25, 28). Performance Analysis of Quick Sort Let us now observe the Time complexity of Quick Sort in the best case, average case, and worst case. We will also observe the Space complexity of Quick Sort. Time Complexity:
Auxiliary Space Complexity: O(log n) Some Applications of Quick Sort The following are some applications of Quick Sort:
Merge SortMerge Sort is another sorting algorithm that works on the divide and conquer approach. In each iteration, merge sort divides the input array into two equal sub-arrays, calls itself recursively for the two sub-arrays, and finally merges the two sorted halves. Let us understand the intuitive approach behind the merge sort using an example: 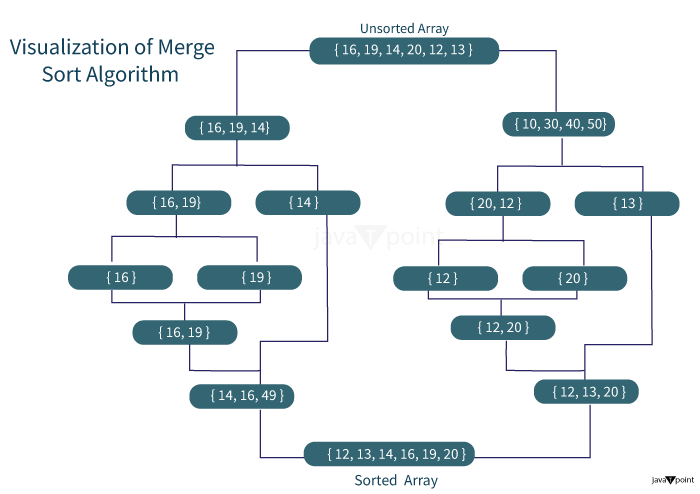
Now that we have understood the intuitive concept behind the merge sort, it is time for us to consider its standard implementation in C++ Programming Language. Implementation of Merge Sort in C++Output: Unsorted Array : 25 23 28 16 18 Sorted Array : 16 18 23 25 28 Explanation: We included the 'bits/stdc++.h' header file in the above code snippet and used the standard namespace. We have then defined the function as merge_subarray() that accepts multiple arguments like an array name, starting point, middle point, and ending point. Inside this function, we have defined some variables along with some arrays. We have then inserted the elements into these arrays using the for-loop. We have then defined and initialized some iterables and used the while loop to sort the sub-arrays by swapping their elements. We have then defined another function as MergeSort() that accepts three parameters - array name, starting point, and ending point. Inside this function, we have used the if conditional statement to check whether the starting point is greater than or equal to the ending point and added a return statement to break the loop. We have then defined and initialized a variable as middle and recursively called MergeSort() function to sort the array. We have then called the merge_subarray() function. Now inside the main function, we have defined and initialized an unsorted array as arr. We then calculated its size. We have also printed the elements of the unsorted array for the users. We then called the MergeSort() function by passing the array name and starting and ending points. At last, we have printed the sorted array elements for the users. As a result, the given array, i.e., (25, 23, 28, 16, 18), is sorted into ascending order as (16, 18, 23, 25, 28). Performance Analysis of Merge Sort Let us now observe the Time complexity of Merge Sort in the best case, average case, and worst case. We will also observe the Space complexity of Merge Sort. Time Complexity:
Auxiliary Space Complexity: O(n) Some Applications of Merge Sort The following are some applications of Merge Sort:
Counting SortCounting Sort is a fascinating sorting algorithm primarily focusing on the frequency of unique data elements between a particular range (something along the lines of hashing). This sorting algorithm works by counting the number of data elements having distinct key values and then building a sorted array after estimating the position of each unique data element in the unsorted sequence. Counting Sort stands apart from the algorithms we discussed earlier as it involves zero comparisons between the input data elements. Let us understand the intuitive approach behind the counting sort using an example: Example: For simplicity, suppose we are given an unsorted array of data elements ranging from 0 to 3.
Now process the input data : 1, 0, 3, 1, 3, 1
Final Array : (0, 1, 1, 1, 3, 3) Now that we have understood the intuitive concept behind the counting sort, it is time for us to consider its standard implementation in C++ Programming Language. Implementation of Counting Sort in C++Output: Unsorted Array : 1 0 3 1 3 1 Sorted Array : 0 1 1 1 3 3 Explanation: We included the 'bits/stdc++.h' header file in the above code snippet and used the standard namespace. We have then defined the function as getMaximum() that accepts two parameters as the array name and its size in order to retrieve the maximum value from the array. Inside this function, we have first initialized a variable with an initial maximum value. We then iterated through the array, updated the variable value with the final maximum value, and returned it. We have then defined another function as CountingSort(), that accepts two parameters as the array name and its size. Inside this function, we have defined an array to store the output, called the getMaximum() function, and a counter array. We have then used the for-loop to set the initial values of the elements in the counter array to 0. We have again used the for-loop to update the values in the counter array for the given array. We then iterated through the counter array again using the for-loop, modifying its value to form a prefix sum array. Again, we used the for-loop to generate the output from the input sequence, then decreased its count by 1. At last, we have used the for-loop to iterate through the data elements of the array and update their values in respect of the output array. Now inside the main function, we have defined and initialized an unsorted array as arr. We then calculated its size. We have also printed the elements of the unsorted array for the users. We then called the CountingSort() function by passing the array name and starting and ending points. At last, we have printed the sorted array elements for the users. As a result, the given array, i.e., (1, 0, 3, 1, 3, 1), is sorted into ascending order as (0, 1, 1, 1, 3, 3). Performance Analysis of Counting Sort Let us now observe the Time complexity of Counting Sort in the best case, average case, and worst case. We will also observe the Space complexity of Counting Sort. Time Complexity:
Auxiliary Space Complexity: O(k), where k is the count of unique elements in the array. Some Applications of Counting Sort The following are some applications of Counting Sort:
Radix SortAs we have already discussed, Counting Sort stands apart because it is not a comparison-based sorting algorithm similar to Merge Sort or Bubble Sort. Thus, we can reduce its time complexity to linear time. However, this sorting technique fails when the data elements of the input array range from 1 to n2, which results in an increase of its time complexity to O(n2). The fundamental concept behind radix sorting is to extend the functionality of counting sort to achieve a better time complexity when the data elements of the input array range from 1 to n2. Let us understand this sorting algorithm in brief: Algorithm: For each digit i, where i varies from the least significant digit to the most significant digit of the number, we will use the count sort algorithm to sort the input array to the ith digit. Note: We have used the counting sort because it is a stable sorting algorithm.Let us understand the intuitive approach behind the radix sort using an example: Example: Suppose we are given an array of six different data elements arranged unsorted.
We will now use the radix sort to arrange these data elements of the array in ascending order.
After sorting, we will get the following array: (90, 151, 232, 54, 634, 37)
After sorting, we will get the following array: (232, 634, 37, 151, 54, 90)
After sorting, we will get the following array: (37, 54, 90, 151, 232, 634), which is also the final sorted array. Now that we have understood the intuitive concept behind the radix sort, it is time for us to consider its standard implementation in C++ Programming Language. Implementation of Radix Sort in C++Output: Unsorted Array : 54 90 151 37 634 232 Sorted Array : 37 54 90 151 232 634 Explanation: We included the 'bits/stdc++.h' header file in the above code snippet and used the standard namespace. We have then defined the function as getMaximum() that accepts two parameters as the array name and its size in order to retrieve the maximum value from the array. Inside this function, we have first initialized a variable with an initial maximum value. We then iterated through the array, updated the variable value with the final maximum value, and returned it. We have then defined another function as CountingSort(), that accepts multiple parameters such as the array name, its size, and significant bit. Inside this function, we have defined an array to store the output, a counter array, and an iterable. We then used multiple for-loops to sort the array according to their selected significant bits. We have then defined the function as RadixSort(), which accepts two parameters as the array name and its size. Inside this function, we have called the getMaximum() function and used the for-loop to call the CountingSort() function. Now inside the main function, we have defined and initialized an unsorted array as arr. We then calculated its size. We have also printed the elements of the unsorted array for the users. We then called the RadixSort() function by passing the array name and its size. At last, we have printed the sorted array elements for the users. As a result, the given array, i.e., (54, 90, 151, 37, 634, 232), is sorted into ascending order as (37, 54, 90, 151, 232, 634). Performance Analysis of Radix Sort Let us now observe the Time complexity of Radix Sort in the best case, average case, and worst case. We will also observe the Space complexity of Radix Sort. Time Complexity:
Auxiliary Space Complexity: O(n + k), where n is the number of elements in the array and k is the count of unique elements in the array. Some Applications of Radix Sort The following are some applications of Radix Sort:
Bucket SortBucket Sort is a comparison-based sorting algorithm that divides the data elements of an array into multiple buckets recursively and then sorts these buckets individually with the help of a different sorting algorithm. At last, the final sorted buckets are re-united to produce the sorted array. Let us understand the bucket sort algorithm with the help of a pseudocode: We can explore the working of the bucket sort algorithm further by assuming that we have already created an array of multiple 'buckets' (lists). Data elements are now inserted from the unsorted array into these 'buckets' on the basis of their properties. These buckets are finally sorted separately with the help of the insertion sort algorithm, as discussed earlier. The following is the pseudocode for the Bucket Sort algorithm: Pseudocode: Now that we have understood the intuitive concept behind the bucket sort, it is time for us to consider its standard implementation in C++ Programming Language. Implementation of Bucket Sort in C++Output: Unsorted Array : 0.454 0.583 0.4471 0.6146 0.563 0.9412 Sorted Array : 0.4471 0.454 0.563 0.583 0.6146 0.9412 Explanation: We included the 'bits/stdc++.h' header file in the above code snippet, defined a constant to perform push back and used the standard namespace. We have then defined the function as BucketSort() that accepts two parameters as the array name and its size in order to sort the elements of the array. Inside this function, we have first defined an array using vector to represent buckets. We then used the for-loop to iterate through the array pushing the data elements from it to the bucket. We have then again used the for-loop to iterate through the elements of the bucket and sort them using the insertion sort into ascending order. We have then again used the for-loop to update the sorted elements from the buckets in the array. Now inside the main function, we have defined and initialized an unsorted array as arr. We then calculated its size. We have also printed the elements of the unsorted array for the users. We then called the BucketSort() function by passing the array name and its size. At last, we have printed the sorted array elements for the users. As a result, the given array, i.e., (0.454 0.583 0.4471 0.6146 0.563 0.9412), is sorted into ascending order as (0.4471 0.454 0.563 0.583 0.6146 0.9412). Performance Analysis of Bucket Sort Let us now observe the Time complexity of Bucket Sort in the best case, average case, and worst case. We will also observe the Space complexity of Bucket Sort. Time Complexity:
Auxiliary Space Complexity: O(n), where n is the number of elements in the array and k is the count of unique elements in the array. Some Applications of Bucket Sort The following are some applications of Bucket Sort:
Comb SortComb Sort is quite fascinating. It is an improved version of the bubble sort algorithm. As some have observed earlier, the bubble sort algorithm compares adjacent data elements for every iteration. However, the comb sort algorithm compares and swaps the data elements by a large gap value. The gap value shrinks by a factor of 1.3 for each iteration until the gap value reaches 1, at which it stops the execution. This shrink factor has been calculated to be 1.3 by trial and error (after testing the comb sort algorithm on over 2 lakh random arrays). Let us understand the intuitive approach behind the comb sort using an example: Example: Suppose we are given an array of ten different data elements arranged unsorted.
Initial Gap Value: 10
Therefore, the elements will be sorted in the following format: 100, 90, 80, 70, 60, 50, 40, 30, 20, 10 30, 90, 80, 70, 60, 50, 40, 100, 20, 10 30, 20, 80, 70, 60, 50, 40, 100, 90, 10 30, 20, 10, 70, 60, 50, 40, 100, 90, 80
Since the data elements are already arranged in ascending order for gap value 5. Therefore, the array will remain unchanged as shown below: 30, 20, 10, 70, 60, 50, 40, 100, 90, 80
Therefore, the elements will be sorted in the following format: 30, 20, 10, 70, 60, 50, 40, 100, 90, 80 30, 20, 10, 40, 60, 50, 70, 100, 90, 80
Therefore, the elements will be sorted in the following format: 30, 20, 10, 40, 60, 50, 70, 100, 90, 80 10, 20, 30, 40, 60, 50, 70, 100, 90, 80 10, 20, 30, 40, 60, 50, 70, 80, 90, 100
Therefore, the elements will be sorted in the following format: 10, 20, 30, 40, 60, 50, 70, 80, 90, 100 10, 20, 30, 40, 50, 60, 70, 80, 90, 100
Now that we have understood the intuitive concept behind the comb sort, it is time for us to consider its standard implementation in C++ Programming Language. Implementation of Comb Sort in C++Output: Unsorted Array : 100 90 80 70 60 50 40 30 20 10 Sorted Array : 10 20 30 40 50 60 70 80 90 100 Explanation: We included the 'bits/stdc++.h' header file in the above code snippet and used the standard namespace. We have then defined the function as CombSort(), which accepts two parameters as the array name and its size in order to sort the elements of the array. Inside this function, we initially defined the variable specifying the gap value and a Boolean flag setting it to True. We have then used the while loop that will iterate until the gap value will reduce to 1 and flag turn False. We have updated the gap value inside this loop by dividing the current gap by 1.3. We have also used the if conditional statement to check if the gap value is less than one and set it to 1. We have also updated the value of the flag and used the for-loop to iterate through the data elements of the array and sort them according to their gap values. Now inside the main function, we have defined and initialized an unsorted array as arr. We then calculated its size. We have also printed the elements of the unsorted array for the users. We then called the CombSort() function by passing the array name and its size. At last, we have printed the sorted array elements for the users. As a result, the given array, i.e., (100, 90, 80, 70, 60, 50, 40, 30, 20, 10), is sorted into ascending order as (10, 20, 30, 40, 50, 60, 70, 80, 90, 100). Performance Analysis of Comb Sort Let us now observe the Time complexity of Comb Sort in the best case, average case, and worst case. We will also observe the Space complexity of Comb Sort. Time Complexity:
Auxiliary Space Complexity: O(1) Some Applications of Comb Sort The following are some applications of Comb Sort:
Shell SortThe Shell Sort algorithm is an improved version of the Insertion Sort algorithm in which we resort to diminishing partitions in order to sort the data. In each pass, the gap size is reduced to half its previous value for each pass throughout the array. Hence, for every iteration, the data elements of the array are compared by the calculated gap value and swapped (if required). Let us understand the shell sort algorithm with the help of a pseudocode: The following is the pseudocode for the Shell Sort algorithm: Pseudocode: The concept of shell sort allows the exchange of data elements situated far from each other. In Shell Sort, we make the array N-sorted for a large value of N. We then keep reducing the value of N until it becomes 1. An array is said to be N-sorted if all the sub-arrays of every Nth element are sorted. For each iteration, the gap size will be floor(N/2). Now that we have understood the intuitive concept behind the shell sort, it is time for us to consider its standard implementation in C++ Programming Language. Implementation of Shell Sort in C++Output: Unsorted Array : 100 90 80 70 60 50 40 30 20 10 Sorted Array : 10 20 30 40 50 60 70 80 90 100 Explanation: We included the 'bits/stdc++.h' header file in the above code snippet and used the standard namespace. We have then defined the function as ShellSort(), which accepts two parameters as the array name and its size in order to sort the elements of the array. Inside this function, we have used the nested for-loop to iterate through the elements of the array in respect to the gap values. We have then defined and initialized the variable as the current element of the array and an iterable. We have then again used the for-loop to sort the array in ascending order. Now inside the main function, we have defined and initialized an unsorted array as arr. We then calculated its size. We have also printed the elements of the unsorted array for the users. We then called the ShellSort() function by passing the array name and its size. At last, we have printed the sorted array elements for the users. As a result, the given array, i.e., (100, 90, 80, 70, 60, 50, 40, 30, 20, 10), is sorted into ascending order as (10, 20, 30, 40, 50, 60, 70, 80, 90, 100). Performance Analysis of Shell Sort Let us now observe the Time complexity of Shell Sort in the best case, average case, and worst case. We will also observe the Space complexity of Shell Sort. Time Complexity:
Auxiliary Space Complexity: O(1) Some Applications of Shell Sort The following are some applications of Shell Sort:
Complete Performance Analysis Chart of Sorting AlgorithmsThe following is the complete performance analysis chart of different sorting algorithm that we have studied earlier along with some more algorithms: Table of Complexity Comparison
Which is the Best Sorting Algorithm?From the table shown above, we can observe that the time complexity of Quick Sort is O(n log n) in the best and average case scenarios and O(n2) in the worst case. However, since Quick Sort has the upper hand in the average cases for most inputs, this algorithm is generally considered the "FASTEST" sorting algorithm. What is the Easiest Sorting Algorithm?Bubble Sort is broadly appreciated as the simplest sorting algorithm among the other sorting algorithms. The fundamental concept of this algorithm is to scan through the complete array, comparing the adjacent data elements and swapping them (if necessary) until the array is sorted. Which Sorting Algorithm would one prefer for a nearly sorted list?When we have to sort a nearly sorted list, the Insertion Sort algorithm is the clear winner specifically because its time complexity reduces to O(n) from a whopping O(n2) on such a sample. In contrast to Insertion Sort, algorithms like Merge Sort and Quick Sort do not generally adapt well to nearly sorted arrays.
Next TopicExtended Euclidian Algorithm
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








