| |

Spark reduceByKey FunctionIn Spark, the reduceByKey function is a frequently used transformation operation that performs aggregation of data. It receives key-value pairs (K, V) as an input, aggregates the values based on the key and generates a dataset of (K, V) pairs as an output. Example of reduceByKey FunctionIn this example, we aggregate the values on the basis of key.
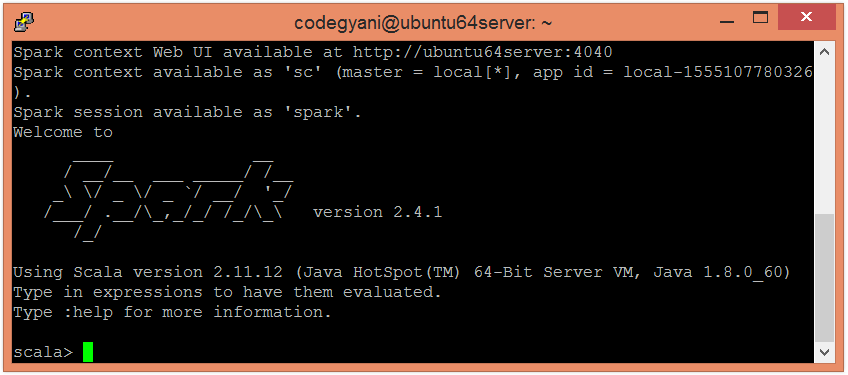
Now, we can read the generated result by using the following command. 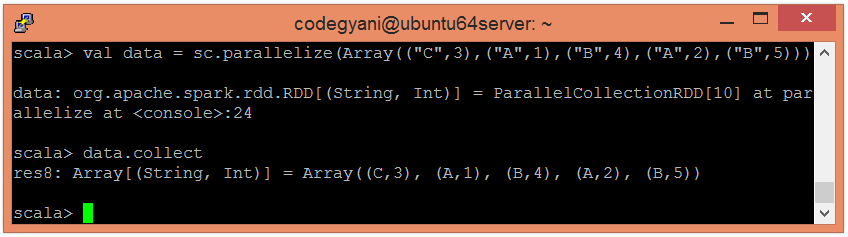

Here, we got the desired output.
Next TopicSpark Co-Group Function
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share



Like/Subscribe us for latest updates or newsletter 




