| |

GATE 20111) In a compiler, keywords of a language are recognized during
Answer: c Explanation: The process of transforming a sequence of symbols into a sequence of tokens is Lexical analysis. In the terms of computer science, process of transforming ordered characters (like as given in a web page or computer program) into a sequence of tokens (assigned and identified meaning strings) is called as lexing, lexical analysis, or tokenization. Lexer is a program that performs lexical analysis. Its also called as scanner or tokenizer, although first stage of a lexer is called as scanner. A lexer and parser are generally combined, to analyze the syntax of different programming languages , web pages, and others. A keyword is also the term used for token: A string with an assigned and identified meaning known as lexical token or token. It will be structured as a pair comprising of a token name and a token value (which is optional). The token name is a category of lexical unit. Common names for tokens are
Consider the following expression in the language C programming: c = x * y + 3; The lexical analysis of above mentioned expression provides the sequence of tokens in below form: [(identifier, c), (operator, =), (identifier, x), (operator, *), (identifier, y), (operator, +), (literal, 3), (separator, ;)] in linguistics a token name is what can be named as part of speech. 2) A layer-4 firewall (a device that can look at all protocol headers up to the transport layer) CANNOT
Answer: d Explanation: A complete HTTP traffic can be blocked by blocking TCP port 80 and it is possible in L4 firewall. D) As it is the liability of Application layer, it cannot block packet based on user identity, it is L4 firewall. 3) If two fair coins are flipped and at least one of the outcomes is known to be a head, what is the probability that both outcomes are heads?
Answer: a Explanation: As we know only one outcome is head, the three possibilities are {head, tail}, {head, head}, {tail, head} The probability that both are heads is = 1 / 3 4) Consider different activities related to email: m1: Send an email from a mail client to a mail server m2: Download an email from mailbox server to a mail client m3: Checking email in a web browser Which is the application level protocol used in each activity?
Answer: c Explanation: protocol used for sending mails by user clients is Simple Mail Transfer Protocol (SMTP). protocol used for receiving mails by clients is Post Office Protocol (POP). simple HTTP process is used for Checking mails in web browser. Today on the internet email is arising as one of the most valuable services. SMTP is used as a method to transfer mail from one user to the another in most internet systems. a push protocol called SMTP is used to send the mail and protocols used to retrieve those emails are IMAP (internet message access protocol) and POP (post office protocol) at the receiver's . SMTP: SMTP protocol is an application layer protocol. A TCP connection is opened to the SMTP server by the client who wants to send the mail and then the mail is sent across the connection. Listening mode is always-on for SMTP server. As soon as SMTP listens for a TCP connection from any client, its process initiates a connection through port 25. As soon as a successful TCP connection is established the client process instantly sends the mail. (C) is the correct option. 5) A company needs to develop a strategy for software product development for which it has a choice of two programming languages L1 and L2. The number of lines of code (LOC) developed using L2 is estimated to be twice the LOC developed with Ll. The product will have to be maintained for five years. Various parameters for the company are given in the table below.
Total cost of the project includes cost of development and maintenance. What is the LOC for L1 for which the cost of the project using L1 is equal to the cost of the project using L2?
Answer: b Explanation: Let assume LOC of L1 = a, so LOC of L2 = 2a Now, (a / 10000) * 1000000 + 5 * 100000 = (2a / 10000) * 750000 + 5 * 50000 Solving for a, we get value of a = 5000 6) The time taken to switch between user and kernel modes of execution be t1 while the time taken to switch between two processes be t2. Which of the following is TRUE?
Answer: C Explanation: talking about Context switches or Process switches, they can occur only in kernel mode. So, we need to move from user to kernel mode for process switches first. Then from which we are taking off CPU, PCB of that process have to be saved. Then PCB of the required process need to be loaded. Now we are done with switching from kernel to user mode. But if we talk about switching from user to kernel mode, it is a very quick operation (just single bit change is required at hardware level) Thus T1< T2 7) A company needs to develop digital signal processing software for one of its newest inventions. The software is expected to have 40000 lines of code. The company needs to determine the effort in person-months needed to develop this software using the basic COCOMO model. The multiplicative factor for this model is given as 2.8 for the software development on embedded systems, while the exponentiation factor is given as 1.20. What is the estimated effort in person-months?
Answer: a Explanation: the formula and effort applied in Constructive Cost Model (COCOMO) is following Barry W. Boehm developed the constructive cost model in the late 1970s and published in Boehm's 1981 book named Software Engineering Economic as a model which is used for estimating effort, schedule and cost for software projects. It pictured on a study of 63 TRW Aerospace projects where Director of Software Research and Technology was Boehm. The projects examined during study were in different sizes ranging from 2,000 to 100,000 lines of code, programming languages used were also different and were ranged from assembly to PL/I. Projects examined were based on the waterfall model of software development Life cycle, in 1981 it was the practiced by most people for software development process. It was typically called COCOMO 81 in references to this model. COCOMO II was developed in 1995 and in 2000 finally published in the book named Software Cost Estimation with COCOMO II. it is the superseder of COCOMO 81 and is professed to be superior and more effective for estimating modern software development projects; provides support for more modern software development processes and a larger database of 161 projects was used for blending it. As software development technology shifted from mainframe systems and overnight batch processing systems to desktop development, the use of off-the-shelf software components and the code reusability, the need for the new model emerged. COCOMO comprises three increasingly detailed and accurate forms hierarchy. Effort Applied (E) = ab(KLOC)bb [ person-months ] = 2.8 * (40)1.20 = 2.8 * 83.65 = 234.25 8) Which one of the following is NOT desired in a good Software Requirement Specifications (SRS) document?
Answer: d Explanation: A requirements specification for a software system is defined in requirements specification document for software. it describes the complete behaviour of a system need to be developed for any client and may also include a set of use cases that to describe user interactions with the software. In addition to above mentioned details, it also comprises of non-functional requirements. For imposing constraints on the design or implementation Non-functional requirements are there (like quality standards, performance engineering requirements, or design constraints) In SRS document following aspects should be clearly document Non-Functional Requirements, Functional Requirements and Goals of implementation for a system. 9) Which of the following pairs have DIFFERENT expressive power?
Answer: b Explanation: NDPDA is used in Languages / grammars having ambiguity. The version of DPDA accepts the deterministic context-free languages, which can be defined as proper subset of context-free languages. Current state and input symbol are used in machine transitions, and also the symbol which is current and at the topmost of the stack. If we talk about symbols which are at lower into the stack are actually do not have immediate effect and are not visible. As discussed about machine actions it includes popping, pushing, or replacing the element placed on the stack top. A DPDA for the same combination of input symbol has maximum one legal transition, top stack symbol and state. Hence because of this it differs from the NPDA(nondeterministic pushdown automaton). 10) HTML(Hypertext Markup Language) has language elements which permit certain actions other than describing the structure of the web document. Which one of the following actions is NOT supported by pure HTML (without any server or client side scripting)pages?
Answer: d Explanation: A) Embed web objects from different sites into the same page we use <object> element. B) Refresh the page automatically after a specified interval we use <meta http-equiv = "refresh"> tag. C) Automatically redirect to another page upon download we can use following html tags like 0 x 0 - <iframe> with the download source and we can also use <meta http - equiv = "refresh" content = "0; url = download.binary" /> to achieve this. D) Without using JavaScript it is practically not possible - generally there exist no idea about the user's time i.e. at what time reply is send by user. 11) A computer handles several interrupt sources of which the following are relevant for this question. Interrupt from CPU temperature sensor (raises interrupt if CPU temperature is too high) Interrupt from Mouse(raises interrupt if the mouse is moved or a button is pressed) Interrupt from Keyboard(raises interrupt when a key is pressed or released) Interrupt from Hard Disk(raises interrupt when a disk read is completed) Which one of these will be handled at the HIGHEST priority?
Answer: d Explanation: If higher priority interrupt levels which if assigned to a requests, if get delayed or interrupted, can lead to fatal consequences. Some devices with generally has high speed rate of transfer for example magnetic disks are always assigned high priority, whereas slow devices like mouse, keyboard are assigned with low priority. The important interrupt i.e. from CPU temperature sensor can lead to fatal consequences if not given priority or ignored. 12) Consider a relational table with a single record for each registered student with the following attributes.
Which one of the following option is INCORRECT?
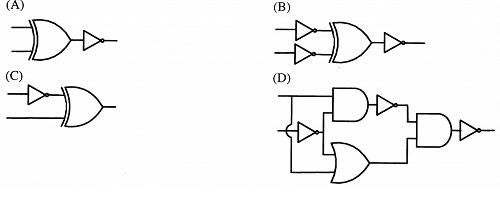
Answer: a Explanation: The role of candidate key value is to uniquely identify the corresponding tuple of a table. Here in above question Bank A/C number is not acting as candidate key. In a question it stated that a student multiple accounts or joint accounts can be there. The column stores the primary a/c number of student. Now taking a case that more than one students has joint a/c and if the joint a/c is their primary account, in that case value of Bank A/C number will not be able to uniquely identify tuple of table. 13) Which one of the following circuits is NOT equivalent to a 2-input XNOR (exclusive NOR) gate?
Answer: d Explanation: Except option D all other options i.e. options A, B, C produce XOR. 14) The simplified SOP (Sum Of Product) form of the boolean expression (P + Q' + R') . (P + Q' + R) . (P + Q + R') is
Answer: b Explanation: below can be seen with given example (P + Q' + R') . (P + Q' + R) . (P + Q +R') =
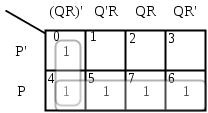
Using K-map, Product Of Sum form is : P + Q'.R' 15) The minimum number of D flip-flops needed to design a mod-258 counter is.
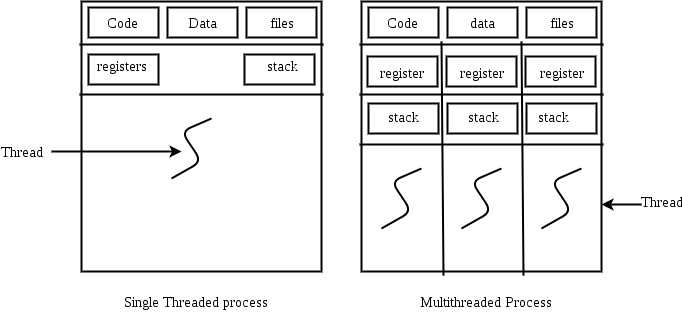
Answer: a Explanation: If we talk of a n-bit binary counter it generally consists of 'n' flip-flops which is capable of counting in binary from 0 to 2n - 1. 2n ≥ 258 16) A thread is usually defined as a "light weight process" because an operating system (OS) maintains smaller data structures for a thread than for a process. In relation to this, which of the following is TRUE?
Answer: c Explanation: Address space of Process is shared by Threads. If we talk about memory it is concerned with processes but exactly not with Threads. A basic unit of CPU utilization is termed as thread, which is composed of a stack, program counter, along with few set of registers, ( also thread ID.) As from fig it can be noticed that, for a one thread of control - it has one PC-program counter, along with single sequence of instructions which generally can be make out at any point of time and if we talk of multi-threaded applications, we can see that multiple threads are there within a one selected process, each having their own stack, program counter, along with few set of registers while sharing data, common code, and certain specific structures like open files.
Option (A): From above diagram it is clear that, apart from CPU Register, data files, stack and code files are also maintained. Hence the option (A) is wrong because according to it operating system maintains only state of CPU register. Option (B): As per given option (B), Operating System doesn't maintain a separate stack for each and every thread. From above diagram it is clear that and it can be seen that , for every thread, a separate stack is maintained. Hence option (B) is also wrong. Option (C): As per given option (C), the Operating System does not form a virtual memory state. So it is absolutely correct that Operating System does not maintain any virtual memory state for single thread. Option (D): As per given option (D), the OS maintains only accounting and scheduling information. But it is not correct as it contains other information like cpu registers stack, program counters, data files, code files are also maintained. 17)
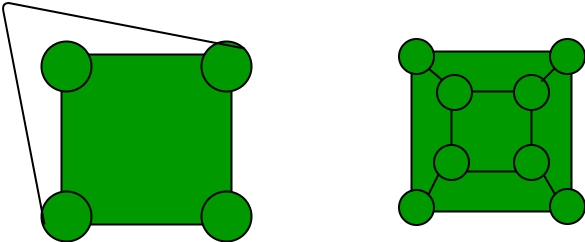
Answer: b Explanation: A Graph can be drawn in a plane in such a manner so that no two edges crossing each other is called as loaner graph. Following two graphs are planar embedding of the concerned graph.
18) If the difference between expectation of the square of a random variable (E[X²]) and the square of the expectation of the random variable (E[X])² is denoted by R, then?
Answer: c Explanation: Variance of random variable can be defined as difference between (E[X])² and (E[X²]). Variance is mainly used for measuring how far a set of numbers is distributed. (zero variance indicates that all the values are same.) whereas a non-zero variance is always represented in positive: 19) The lexical analysis for a modern computer language such as Java needs the power of which one of the following machine models in a necessary and sufficient sense?
Answer: a Explanation: If we talk about lexical analysis then in that case finite automata is used producing keywords, tokens in the form of identifiers, and constants from the program which is inputted. It is used for searching keywords by using string-matching algorithms in the process of pattern recognition, the first step in compilation is Lexical analysis. Program are divided into various tokens in the process of lexical analysis. If we talk of finite state automata, lexical analysers are typically based on it. Tokens can generally be represented via different regular expressions: An identifier is represented by [a - z, A - Z][a - z, A - Z, 0 - 9]* The keyword if is given by if. Integers are given by [- +] ? [0 - 9]+. 20) Let the page fault service time be 10ms in a computer with average memory access time being 20ns. If one page fault is generated for every 10^6 memory accesses, what is the effective access time for the memory?
Answer: b Explanation: Let page fault rate be represented by Y EMAT(Effective Memory Access Time) = Y x (page fault service time) + (1 - Y) x (access time of memory) = ( 1 / (106) ) x 10 x (106) ns + (1 - 1 / (106)) x 20 ns = 30 ns (approximately) 21) Consider a hypothetical processor with an instruction of type LW R1, 20(R2), which during execution reads a 32-bit word from memory and stores it in a 32-bit register R1. The effective address of the memory location is obtained by the addition of a constant 20 and the contents of register R2. Which of the following best reflects the addressing mode implemented by this instruction for operand in memory?
Answer: d 22) What does the following fragment of C-program print?
char c[] = "GATE2011";
char *p = c;
printf("%s", p + p[3] - p[1]) ;
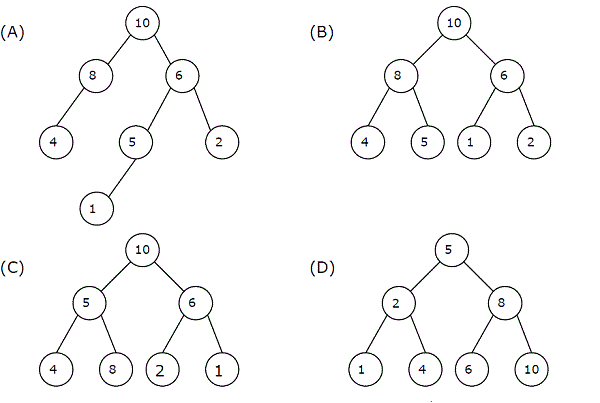
Answer: c Explanation: =>By *p = c, in the given code can be deduced as pointer p is representing string c which is "GATE2021", hence p[3] using given string c is 'E' and p[1] using given string c is 'A'. =>In printf statement : p[3] - p[1] can be deduced as ASCII code of value of character 'E' minus ASCII code value of character 'A' = 4 => Hence the expression p + p[3] - p[1] using above value becomes p + 4 which is base address of string "2011" Therefore printf("%s", p + p[3] - p[1]) ; will finally print the value 2011 23) A max-heap is a heap where the value of each parent is greater than or equal to the values of its children. Which of the following is a max-heap?
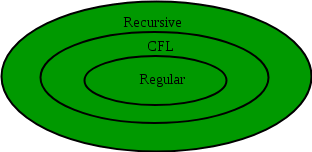
Answer: b Explanation: A binary tree BT is said to be a max-heap in case it is a complete binary tree CBT (A CBT is a binary tree also called complete binary tree where every level, except the last possibly, is completely covered / occupied, and every nodes are as far left) finally follows the max-heap property (where max heap can be defined as a binary tree in which each parent of binary tree is either greater than or equal to the values of its corresponding left and right children's). A)Binary tree represented in figure A is not a max-heap as it does not follow property of complete binary tree B) Binary tree represented in figure B is a max-heap as it follows property of complete binary tree along with it also follows property of max-heap. C) Binary tree represented in figure C is not a max-heap as it can be seen that '8' is the right child of node '5'hence, violates the property of max-heap. D) Binary tree represented in figure D is not a max-heap as it can be seen that '8' is the right child of node '5', so violates the property of max-heap. Apart from above many other nodes in the fig D of binary tree are violating max-heap property. 24) Let P be a regular language and Q be context-free language such that Q ⊆ P. (For example, let P be the language represented by the regular expression p*q* and Q be {pnqn| n ∊ N}). Then which of the following is ALWAYS regular? (A) P ⋂Q
Answer: c Explanation: 1. P ∩ Q said as P intersection Q, would be Q, because of the given fact which Q ⊆ P, i.e. Q is subset of P, hence we can say that it is context free language but it is not regular language. 2. P - Q(P minus Q) = P ∩ Q (P intersection Q) may not be even context free language, because of the closure properties of CFL- context free languages. 3. Σ∗ − P(Σ∗ minus P) is as equivalent to the P compliment, hence we can say it is regular language. Closure laws of regular languages can be referred for same. 4. Σ∗ − Q (Σ∗ minus Q) is as equivalent to the Q compliment, hence we can say that it might not be a CFL- context free language. 25) An algorithm to find the length of the longest monotonically increasing sequence of numbers in an array A[0 :n-1] is given below.
Which of the following statements is TRUE?
Answer: a Explanation: Using Dynamic Programming concept the LIS- Longest Increasing Subsequence problem can be solved. In LIS - longest increasing subsequence problem our job is to find the from the given sequence the length of the longest subsequence in such a manner so all the values in the subsequence are sorted in non-decreasing order. Let's take an example, the length of longest increasing subsequence for {11, 23, 10, 34, 22, 51, 42, 61, 81} is 6 and longest increasing subsequence is {11, 23, 34, 51, 61, 81}. Examples: Input: arry[] = {4, 11, 3, 2, 21} Output: Length of L I S = 3The L I S is 4, 11, 21 Input: arry[] = {6, 4, 11, 8, 41, 81} Output: Length of L I S = 4The L I S is {4, 8, 41, 81} Input: arry[] = {4, 3} Output: Length of L I S = 1The L I S are {4} and {3} Method using Recursion technique Optimal Substructure: Let arry [0 . . . . . . . . . . n - 1] be the array which is inputted and let L(i) be the length of the longest increasing subsequence which terminates at an index i such that arry[ i ] is representing the last element of the longest increasing subsequence. Then, L(i) can be recursively written as: L( i ) = 1 + max( L( j ) ) we can say that value j: 0 < j < i and arry[ j ] < arry[ i ]; orL( i ) = 1, in case no such j exists. For calculating longest increasing subsequence of a given array, The thing needed to return is said as max(L( i )) and value of i lies 0 < i < n. Formally, the length of the longest increasing subsequence terminating at an index i, will be one more than the max lengths of all L I S terminating at indices prior to index i, where arry[ j ] < arry[ i ] (j < i). Thus, we observe that the longest increasing subsequence problem obeys the optimal substructure property as the important problem which can be solved using solutions to subproblems. The below recursive tree will help to make the used approach much better: Input : arry[] = {3, 10, 2, 11} F(i): Represent longest increasing subsequence of subarray terminating at an index 'i' (longest increasing subsequence 1} 26) Consider the language L1, L2, L3 as given below. L1 = {0p 1q | p, q ε N} L2 = {0p1q | p, q ε N and p = q} L3 = {0p 1q0r | p, q, r ε N and p = q = r} Which of the following statements is NOT TRUE?
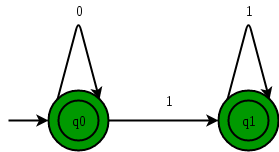
Answer: c Explanation: L1 is regular language. Its Deterministic Finite Automata DFA is represented as
L2 is not regular language, and it can be proved via pumping lemma. Either given L2 is Context Free Language. S → AB ------------------------ (a) A → 0A | ε --------------- (b) B → 1B | ε ---------------- (c) L3 is not Context Free Language, it also can be proved via pumping lemma. Either given L3 is Recursively Enumerable Language.
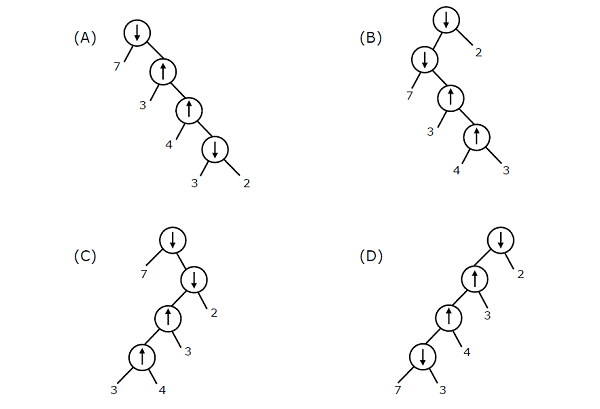
From the above fig it can be said that every RL is also a Context Free Language. So Push Down Automata is used for recognizing L1 and L2. As a Context Free Language and Regular language are also a Recursive language. So we can say that Turing Machine can be used for recognizing all the given L1, L2 and L3. L2 is not RL, which can be proved using pumping lemma. Either given L2 is Context Free Language. S → AB A → 0A | ε B → 1B | ε L3 is not Context Free Language, can be proved using pumping lemma (refer to Ullman). Either given L3 is Recursively Enumerable Language. 27) Consider two binary operators ' ↑ ' and ' ↓ ' with the precedence of operator ↓ being lower than that of the ↑ operator. Operator ↑ is right associative while operator ↓ is left associative. Which one of the following represents the parse tree for expression (7 ↓ 3 ↑ 4 ↑ 3 ↓ 2) ?
Answer: b Explanation: Given the expression in above question : (7 ↓ 3 ↑ 4 ↑ 3 ↓ 2). We work according to precedence an ↑ has higher precedence, Therefore the sub-expression represented via ([3 ↑ 4 ↑ 3) will first be evaluated. As because operator ↑ is right to left associative hence the sub-expression, 4 ↑ 3 would be evaluated first. Hence the pattern of evaluation of expression will be ((7 ↓ (3 ↑ (4 ↑ 3))) ↓ 2). Here we have to note that among the two ↓ operators, second one is evaluated after the first one since the associativity of operator ↓ is from left to right. 28) On a non-pipelined sequential processor, a program segment, which is a part of the interrupt service routine, is given to transfer 500 bytes from an I/O device to memory. Initialize the address registerInitialize the count to 500 LOOP: Load a byte from device Store in memory at address given by address register Increment the address register Decrement the count If count != 0 go to LOOP Assume that each statement in this program is equivalent to machine instruction which takes one clock cycle to execute if it is a non-load/store instruction. The load-store instructions take two clock cycles to execute. The designer of the system also has an alternate approach of using DMA controller to implement the same transfer. The DMA controller requires 20 clock cycles for initialization and other overheads. Each DMA transfer cycle takes two clock cycles to transfer one byte of data from the device to the memory. What is the approximate speedup when the DMA controller based design is used in place of the interrupt driven program based input-output?
Answer: a Explanation: 29) We are given a set of n distinct elements and an unlabelled binary tree with n nodes. In how many ways can we populate the tree with the given set so that it becomes a binary search tree?
Answer: b Explanation: Counting the number of different BST possible for 'n' nodes, is equivalent to counting the number of different BT possible for 'n' nodes while having assumption that nodes are not labelled. Hence, this value will also be = 2nCn / (n + 1) (nth Catalan number) In other way, we can say that for every valid BST, we can get factorial n! BT by permuting the vertices, of which only 1 permutation is a BST Hence, the total number of BST possible using 'n' nodes will be Number of different BT with 'n' distinct nodes / factorial n! = (2n)! / (n + 1) = 2n Cn / (n + 1) (nth Catalan number) (One fact can also be kept in mind that for a given tree structure, only one BST can be there. Hence, number of different Binary Search tree's with 'n' nodes will be equal to the number of distinct BT structures possible for 'n' nodes) 30) Which one of the following options is CORRECT given three positive integers x, y and z, and a predicate? P(x) = ¬ (x = 1) ∧∀y (∃z (x = y * z) ⇒ (y = x) ∨ (y = 1))
Answer: a Explanation:
So the predicate is evaluated as P(x) = (¬ (x = 1)) ∧ (∀y (∃z (x = y * z) ⇒ ((y = x) ∨ (y = 1)))) If the value of given P(x) comes out to be true then it means x ≠ 1 and ∀y if there exists value of z in such a manner that x = y * z then we can say that y must be x (that is z = 1) or y must be 1 (that is z = x) Which clearly says that x have only 2 factors the first can be 1 and second can be x itself. The predicate used for defining the prime number. 31) Given i = ? -1, what will be the evaluation of the integral?
Answer: d Explanation:
32) Consider a database table T containing two columns X and Y each of type integer. After the creation of the table, one record (X = 1, Y = 1) is inserted in the table. Let MX and MY denote the respective maximum values of X and Y among all records in the table at any point in time. Using MX and MY, new records are inserted in the table 128 times with X and Y values being MX + 1, 2 * MY + 1 respectively. It may be noted that each time after the insertion, values of MX and MY change. What will be the output of the following SQL query after the steps mentioned above are carried out? SELECT Y FROM T WHERE X = 7;
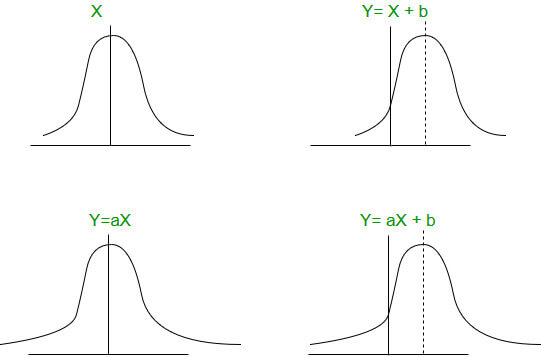
Answer: a Explanation: Given initial value, i.e. value of first tuple of table is 1 1, at this point of time maximum value of MX = 1 and MY = 1, now using above given formula( with X and Y values being MX + 1, 2 * MY + 1 respectively) X = MX + 1 = 1 + 1 = 2 ---------------------------- (1) Y = 2 * MY + 1 = 2 * 1 + 1 = 3 ------------------------- (2) Using equation 1 and 2, tuple 2 of below table is formed. From tuple two we can see the maximum value of X and Y are MX = 2 and MY = 3 above given formula( with X and Y values being MX + 1, 2 * MY + 1 respectively) X = MX + 1 = 2 + 1 = 3 ------------------------ (3) Y = 2 * MY + 1 = 2 * 3 + 1 = 7 ------------------------- (4) Using equation 3 and 4, tuple 3 of below table is formed. From tuple three we can see the maximum value of X and Y are MX = 3 and MY = 7 above given formula( with X and Y values being MX + 1, 2 * MY + 1 respectively) X = MX + 1 = 3 + 1 = 4 ---------------------------- (5) Y = 2 * MY + 1 = 2 * 7 + 1 = 15 ------------------ (6) Using equation 5 and 6, tuple 4 of below table is formed. From tuple four we can see the maximum value of X and Y are MX = 4 and MY = 15 above given formula( with X and Y values being MX + 1, 2 * MY + 1 respectively) X = MX + 1 = 4 + 1 = 5 -----------------------------(7) Y = 2 * MY + 1 = 2 * 15 + 1 = 31 ----------------------------- (8) Using equation 7 and 8, tuple 5 of below table is formed. From tuple five we can see the maximum value of X and Y are MX = 5 and MY = 31 above given formula( with X and Y values being MX + 1, 2 * MY + 1 respectively) X = MX + 1 = 5 + 1 = 6 ------------------------ (9) Y = 2 * MY + 1 = 2 * 31 + 1 = 63 ----------------------------- (10) Using equation 9 and 10, tuple 6 of below table is formed. From tuple six we can see the maximum value of X and Y are MX = 6 and MY = 63 above given formula( with X and Y values being MX + 1, 2 * MY + 1 respectively) X = MX + 1 = 6 + 1 = 7 --------------------------------------- (11) Y = 2 * MY + 1 = 2 * 63 + 1 = 127 --------------------------- (12) Using equation 11 and 12, tuple 7 of below table is formed. Hence using above method a table is formed below, as given in the question that Query SELECT Y FROM T WHERE X = 7; we need to fetch the value for X = 7, hence no need to insert value 128 times. Now from given table the query SELECT Y FROM T WHERE X = 7;, will produce value of Y = 127. 33) Consider a finite sequence of random values X = { x1, x2, . . . . . . . . . . . . , xn}. Let μx be the mean and σx be the standard deviation of X. Let another finite sequence Y of equal length be derived from this as yi = a*xi + b, where a and b are positive constants. Let μy be the mean and σy be the standard deviation of this sequence. Which one of the following statements is INCORRECT?
Answer: d Explanation: On adding constant 'b' shift the distribution, on multiplying to a constant such as 'a' stretch the distribution along median
The most recurrent data of the distribution is Mode, Hence index position of the mode will not alter. Using above graph it can be seen clearly that index position of the median will also not change. Now for the mean
And for the standard deviation
34) A deck of 5 cards (each carrying a distinct number from 1 to 5) is shuffled thoroughly. Two cards are then removed one at time from the deck. What is the probability that the two cards are selected with the number on the first card being one higher than the number on the second card?
Answer: a Explanation: The job is to select 2 cards from the set of 5 cards. Now the order in which they are taken out matters more, there are 5P2 = 5! / 3! = 20 elementary events from which there are 4 favourable number of cases: Card 4 before card 3, card 5 before card 4, card 3 before card 2 and finally card 2 before card 1. Hence, probability = 4 / 20 = 1 / 5 35) Consider the following table of arrival time and burst time for three processes P0, P1 and P2. The pre-emptive shortest job first scheduling algorithm is used. Scheduling is carried out only at arrival or completion of processes. What is the average waiting time for the three processes?
Answer: a Explanation:
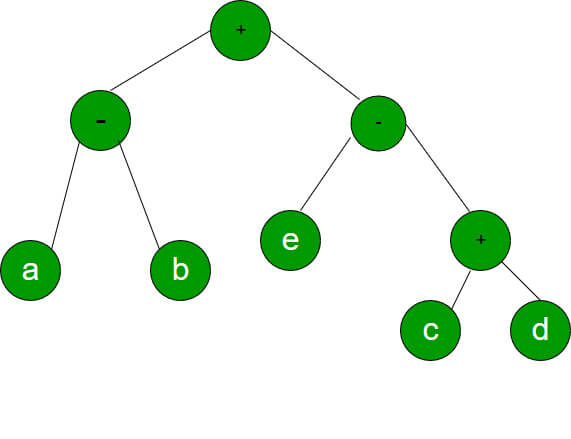
From the above Gantt chart the process P0 is allocated to CPU at time 0 ms and we can see from the table that there is no other process in ready queue as next process arrives at 1 ms. The process P1 arrives at 1 ms then process P0 is pre-empted after P1 arrives at 1 ms, we can see from the table that execution time of P1 which is 4 ms is less than the remaining time of P0 which is now 8 ms. We can see from Gantt chart that process P1 runs for 4ms completely. The process P2 arrived at 2 ms since remaining time of P1 is less than execution time of P2, therefore P1 continued as burst time of P2 is longer than P1. Process P1 completes its entire execution, Now process P0 with remaining time of 8 ms scheduled again as the remaining time for P0 is less than the burst time of P2. From Gantt chart it can be seen that P0 waits for 5 - 1 - 0 = 4 ms, P1 waits for 1 - 1 = 0 ms and P2 waits for 13 - 2 = 11 ms. So average waiting time is (0 + 4 + 11) / 3 = 5. 36) Consider evaluating the following expression tree on a machine with load-store architecture in which memory can be accessed only through load and store instructions. The variables a, b, c, d and e initially stored in memory. The binary operators used in this expression tree can be evaluate by the machine only when the operands are in registers. The instructions produce results only in a register. If no intermediate results can be stored in memory, what is the minimum number of registers needed to evaluate this expression?
Answer: d Explanation: Insert c in R1 : R1 ← c, Insert d in R2 : R2 ← d, Insert sum of R1 and R2 in R2 : R2 ← R1 + R2, Insert e in R1 : R1 ← e, Insert difference of R1 and R2 in R2 : R2 ← R1 - R2 We can now compute the remaining expression, i.e. first we should load value a and value b into the CPU registers but we need the value in register R2 somewhat later. Hence we must make use of another Register. Insert a in R1 : R1 ← a, Insert b in R3 : R3 ← b, Insert difference of R1 and R3 in R1 : R1 ← R1 - R3 Insert sum of R1 and R2 in R1 : R1 ← R1 + R2, 37) Which of the given options provides the increasing order of asymptotic complexity of functions f1, f2, f3 and f4? f1(n) = 2^n
Answer: a Explanation: n*logn among all is the slowest growing function, after that n(3 / 2), and then comes n(logn). Finally, 2n among all is the fastest growing function. 38) Four matrices M1, M2, M3 and M4 of dimensions p x q, q x r, r x s and s x t respectively can be multiplied is several ways with different number of total scalar multiplications. For example, when multiplied as ((M1 X M2) X (M3 X M4)), the total number of multiplications is pqr + rst + prt. When multiplied as (((M1 X M2) X M3) X M4), the total number of scalar multiplications is pqr + prs + pst. If p = 10, q = 100, r = 20, s = 5 and t = 80, then the number of scalar multiplications needed is:
Answer: c Explanation: Using ((M1 X (M2 X M3)) X M4) is a case of minimum number of multiplications. Total number of multiplications = 5 * 20 * 100 + 100 * 10 * 5 + 80 * 5 * 10 = 19000. 39) Consider a relational table r with sufficient number of records, having attributes A1, A2,..., An and let 1 <= p <= n. Two queries Q1 and Q2 are given below.
The database can be configured to do ordered indexing on Ap or hashing on Ap. Which of the following statements is TRUE?
Answer: c Explanation: Hashing can be proved better in case values are accessed for a record from hash table. In case records are searched in the range of values, then in that case ordered indexing will be an better option. We can say that by use of indexing we can optimize the efficiency of a database by actually reducing the no. of disk accesses needed when processing of query takes place. Hashing is data structure method which is basically use for fast locating and accessing of data from database. For creating Indexes few database columns are used. From fig it can be clearly seen that the 1st column is the Search key which has a copy of the candidate key or primary key of the relational schema. Values in relational schema indexes are in sorted order because corresponding value can be quickly accessed. Note: The point which needs to be noted that data may or may not be in sorted order.From fig it can be seen that the 2nd column is the denoted as Data Reference or Pointer which has a set of pointers which is used for holding the address of the various disk blocks, disk blocks are blocks where particular key value can be located.
40) Consider the matrix as given below.
Which one of the following options provides the CORRECT values of the eigenvalues of the matrix?
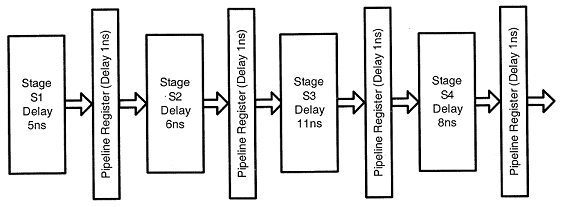
Answer: a Explanation: The diagonal entries are the eigen values of a triangular matrix. Same can be calculate or we can verify the answers given using characteristic equation denoted by |M - λI| = 0. 1 - λ 2 3 0 4 - λ 7 = 0 0 0 3 - λ Which means (4 - λ) * (1 - λ) * (3 - λ) = 0 41) Consider an instruction pipeline with four stages (S1, S2, S3 and S4) each with combinational circuit only. The pipeline registers are required between each stage and at the end of the last stage. Delays for the stages and for the pipeline registers are as given in the figure:
What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation?
Answer: b Explanation: Overhead occurring due to Pipeline registers is actually not counted in normal execution of time, therefore in that case Total count will be calculated as 11 + 6 + 8 + 5 = 30 [without using register of pipeline] Considering the case of pipeline, each stage comprises of 11 n-sec (a;ong with 1 n-sec for an extra overhead occurring due to pipeline registers). and, in stable state o/p is generated after each cycle of pipeline. So considering, in this case it is given as 11 n-sec. On taking into account 1n-sec i.e. adding 1 n-sec extra overhead occurred, Will finally come up with 12 n-sec of constant output producing cycle. So on dividing 30 by 12 we get result as 2.5, i.e. option B is finally correct answer. 42) Definition of a language L with alphabet {a} is given as following. L= { ank | k > 0, and n is a positive integer constant} What is the minimum number of states needed in a DFA to recognize L?
Answer: b Explanation: From the given question that value 'n' is a constant and the value of k is any integer which is positive in nature. Let us take an example, suppose n is given as 3, then in that case the DFA - deterministic finite automata must be able to accept following values 3a, 6a, 9a, 12a, . . . . . . . For building such a DFA - deterministic finite automata, we require 4 states.
The above DFA clearly shows that it is accepting values such as 3a, 6a, 9a, 12a, . . . . . . . so on. 43) An 8KB direct-mapped write-back cache is organized as multiple blocks, each of size 32-bytes. The processor generates 32-bit addresses. The cache controller maintains the tag information for each cache block comprising of the following. 1 Valid bit 1 Modified bit As many bits as the minimum needed to identify the memory block mapped in the cache. What is the total size of memory needed at the cache controller to store meta-data (tags) for the cache?
Answer: d Explanation: From the question give the cache size = 8 KB From the question give the block size = 32 bytes So the formula of calculating No. of cache lines = cache size / block size = (8 * 1024 bytes) / 32 bytes = 256 bytes _________________ (a)
In order to store meta-data of 1 line total bits required = 19 + 1 + 1 = 21 bits____________________ (b) Using equation a and b, putting in below formula: Total Memory Needed = Total bits needed for storing meta-data of 1 line * Number of cache lines 256 * 21 = 5376 bits 44) An application loads 100 libraries at start-up. Loading each library requires exactly one disk access. The seek time of the disk to a random location is given as 10 ms. Rotational speed of disk is 6000 rpm. If all 100 libraries are loaded from random locations on the disk, how long does it take to load all libraries? (The time to transfer data from the disk block once the head has been positioned at the start of the block may be neglected)
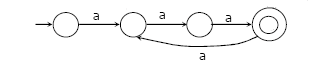
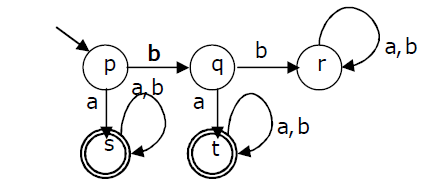
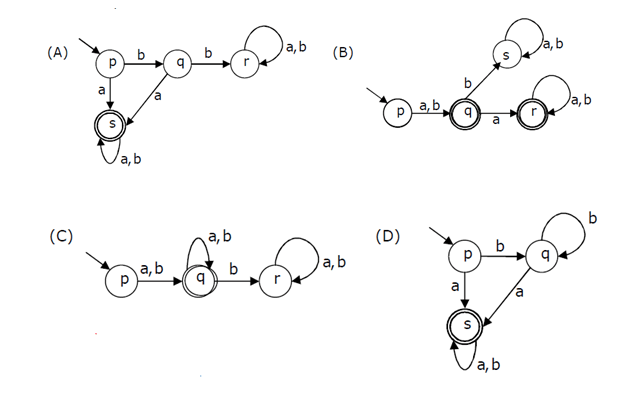
Answer: b Explanation: As time required to transfer, i.e. transfer time can be ignored, Hence the avg. access time is sum of average rotational latency and average seek time. Now avg. seek time for a random location time is given in the question equal as 10 ms. On the other hand the avg. rotational latency is 1/2 of the time required in order to complete a rotation. 6000 rotations require 1 minute is clearly given in the question. Hence 1 rotation will approximately take a time which is equivalent to = 60 / 6000 sec which is 10 ms. Therefore avg. rotational latency is 1/2 of 10 ms, i.e. 5ms. Avg. Disk Access Time = Rotational Latency + Seek Time = 5 ms + 10 ms = 15 ms _________________ (a) Also for hundred (100) libraries, the avg. disk access time will be equivalent to 15 * 100 = 1500 ms 45) A deterministic finite automation (DFA)D with alphabet {a, b} is given below
Which of the following finite state machines is a valid minimal DFA which accepts the same language as D?
Answer: a Explanation: It is clearly given in an elaborated DFA of question that it does not accept 'b' as string, hence Option (B) and Option (C) are invalid as both of the options accept 'b' as a string which is actually not being accepted by given DFA - Deterministic Finite Automata. Even option (D) is also an invalid option as it accepts string "bba" which is actually not being accepted by given DFA in the question, Hence Option (A) is correct option. 46) Database table by name Loan_Records is given below. What is the output of the following SQL query?
Answer: c Explanation: The content of virtual table will be Following will be contents of virtual table T On applying Natural Join on above two table we will get below table as a result. In natural join the table must have common columns, here in above tables Bank_Manager column is the common column. "Sunderajan" has two entries in the column Bank_Manager, Hence there will be 4 entries with Bank_Manager as "Sunderajan". 47) The following is the comment written for a C function. /* This function computes the roots of a quadratic equation x^2 + b.x + c = . The function stores two real roots in *root1 and *root2 and returns the status of validity of roots. It handles four different kinds of cases. (i) When coefficient a is zero irrespective of discriminant (ii) When discreminant is positive (iii) When discriminant is zero (iv) When discriminant is negative. Only in case (ii) and (iii) the stored roots are valid. Otherwise 0 is stored in roots. The function returns 0 when the roots are valid and -1 otherwise. The function also ensures root1 >= root2 int get_QuadRoots( float a, float b, float c, float *root1, float *root2); */ A software test engineer is assigned the job of doing black box testing. He comes up with the following test cases, many of which are redundant.
Which one of the following option provide the set of non-redundant tests using equivalence class partitioning approach from input perspective for black box testing?
Answer: c Explanation: T2, T4, T5 and T6 belong to different classes. Hence it gives an optimal test suite. 48) Consider the following recursive C function that takes two arguments What is the return value of the function foo when it is called as foo(345, 10) ?
Answer: b Explanation: The call foo(345, 10) returns sum of decimal digits (because r is 10) in the number n. Sum of digits for 345 is 3 + 4 + 5 = 12. The call foo(345, 10) will execute in following sequence. foo(34, 10), function foo is called again with parameter n = 34 and r = 10 foo(3, 10), function foo is called again with parameter n = 3 and r = 10 foo(0, 10), function foo is called again with parameter n = 0 and r = 10 49) Consider the same recursive C function that takes two arguments What is the return value of the function foo when it is called as foo(513, 2)?
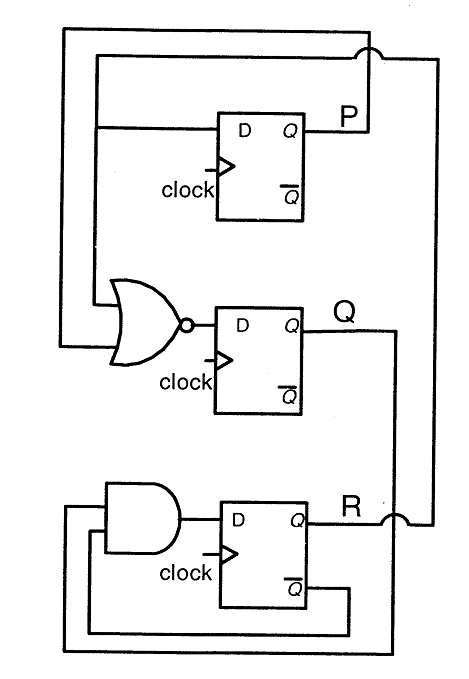
Answer: d Explanation: foo(513, 2) will return 1 + foo(256, 2). All subsequent recursive calls (including foo(256, 2)) will return 0 + foo(n / 2 , 2) except the last call foo(1, 2) . The last call foo(1, 2) returns 1. So, the value returned by foo(513, 2) is 1 + 0 + 0 . . . . . . . . . .+ 0 + 1. The function foo(n, 2) basically returns sum of bits (or count of set bits) in the number n. The call foo(513, 2) will execute in following sequence. foo(256, 2), function foo is called again with parameter n = 256 and r = 2 foo(128, 2), function foo is called again with parameter n = 128 and r = 2 foo(64, 2), function foo is called again with parameter n = 64 and r = 2 foo(32, 2), function foo is called again with parameter n = 32 and r = 2 foo(16, 2), function foo is called again with parameter n = 16 and r = 2 foo(8, 2), function foo is called again with parameter n = 8 and r = 2 foo(4, 2), function foo is called again with parameter n = 4 and r = 2 foo(2, 2), function foo is called again with parameter n = 2 and r = 2 foo(1, 2), function foo is called again with parameter n = 1 and r = 2 foo(0, 2), function foo is called again with parameter n = 0 and r = 2 50) Consider the following circuit involving three D-type flip-flops used in a certain type of counter configuration.
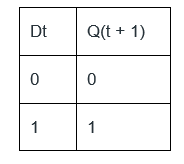
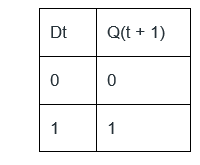
If at some instance prior to the occurrence of the clock edge, P, Q and R have a value 0, 1 and 0 respectively, what shall be the value of PQR after the clock edge?
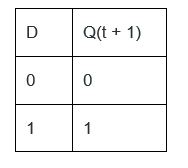
Answer: d Explanation: P' = R, Q' = (P + R)', R' = QR' From the question it is given that (P = 0, Q = 1, R = 0), next state P' = 0, Q' = 1, R' = 1 Truth Table of D Flip Flop
Initially (p = 0, q = 1, r = 0) D flip flop for p = R Alternative approach - Truth table of a D Flip-Flop-
As per the given circuit diagram, it is quite clear that the Boolean expressions of P, Q, and R, are- Here the subscript t refers to the current clock cycle, and the subscript (t + 1) refers to the next clock cycle. QP(t + 1) = P(t + 1) = Rt QQ(t + 1) = Q(t + 1) = Rt' Pt' QQ(t + 1) = Q(t + 1) = QtRt'
51) Consider the data given in previous question. If all the flip-flops were reset to 0 at power on, what is the total number of distinct outputs (states) represented by PQR generated by the counter?
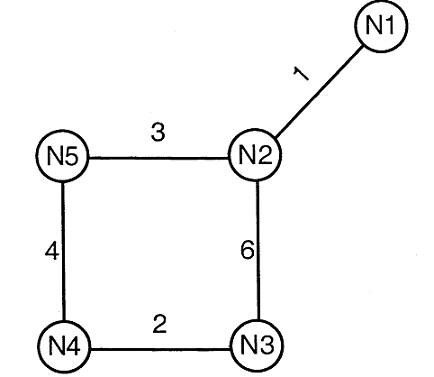
Answer: b Explanation: There will be 4 different states which can be represented as, 0 0 0 → 0 1 0 → 0 1 1 → 1 0 0 (→ 0 0 0) Hence the correct option is option B 52) Consider a network with five nodes, N1 to N5, as shown below.
The network uses a Distance Vector Routing protocol. Once the routes have stabilized, the distance vectors at different nodes are as following. N1: (0, 1, 7, 8, 4) Each distance vector is the distance of the best known path at the instance to nodes, N1 to N5, where the distance to itself is 0. Also, all links are symmetric and the cost is identical in both directions. In each round, all nodes exchange their distance vectors with their respective neighbours. Then all nodes update their distance vectors. In between two rounds, any change in cost of a link will cause the two incident nodes to change only that entry in their distance vectors. 52. The cost of link N2-N3 reduces to 2(in both directions). After the next round of updates, what will be the new distance vector at node, N3.
Answer: a Explanation: If we talk about the next round, each node will receive and send distance vectors to and from neighbours, and finally update its DV - distance vector. The node N3 will receive (1, 0, 2, 7, 3) from the node N2 and finally it will update the distances to the N1 and node N5 as '3' and '5' respectively. 53) Consider the same data as given in previous question. After the update in the previous question, the link N1-N2 goes down. N2 will reflect this change immediately in its distance vector as cost, infinite. After the NEXT ROUND of update, what will be cost to N1 in the distance vector of N3?
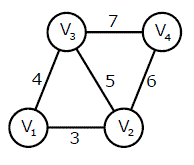
Answer: c Explanation: From the above question we can say that in next round, node N3 will receive distance from node N2 to node N1 as infinite. Finally it will receive distance from node N4 to node N1 as value 8. Hence it will update distance to N1 as 2 + 8. 54) An undirected graph G(V, E) contains n ( n > 2 ) nodes named v1 , v2 , . . . . . . . .vn. Two nodes vi , vj are connected if and only if 0 < |i - j| <= 2. Each edge (vi, vj ) is assigned a weight i + j. A sample graph with n = 4 is shown below.
What will be the cost of the minimum spanning tree (MST) of such a graph with n nodes?
Answer: b Explanation: M S T for two nodes can be represented as below (V1) _ (V2) The Total weight will be equal to 3 M S T for three nodes can be represented as below (V1) _ (V2) | (V3) The Total weight will be equal to 4 + 3 = 7 M S T for four nodes can be represented as below (V1) _ (V2) _ (V4) | (V3) The Total weight will be equal to 4 + 3 + 6 = 13 M S T for four nodes can be represented as below V1) _ (V2) _ (V4) | (V3) | (V5) The Total weight will be equal to 4 + 3 + 8 + 6 = 21 M S T for four nodes can be represented as below (V1) _ (V2) _ (V4) _ (V6) | (V3) | (V5) The Total weight will be equal to 4 + 3 + 8 + 10 + 6 = 31 Observation using above examples is that when we add kth node, the weight of M S T increases by the factor represented as 2k - 2. Let T(n) be the weight of M S T. Hence the T(n) can be written as: T(n) = T(n - 1) + (2n - 2) for n > 2 The different values of T(n) are as follows T(1) = 0, T(2) = 0 and T(2) = 3 Recurrence can be denoted as sum of series (2n - 2) + (2n - 4) + (2n - 6) + (2n - 8) + . . . . . . . . 3 and the recurrence has the solution n^2 - n + 1. Therefore the option B is the correct option. 55) The length of the path from v5 to v6 in the MST of previous question with n = 10 is
Answer: c Explanation: Any Minimum Spanning Tree that has greater than 5 nodes will actually have the equal distance b/w v6 & v5 because of the basic structure of all Minimum Spanning Tree (having greater than 5 nodes) would be following. (V1) _ (V2) _ (V4) _ (V6) _ . . . . . . . (more even numbered nodes) (more odd numbered nodes) Hence the distance between V6 and V5 can be computed as = 6 + 4 + 3 + 10 + 8 = 31 56) Which of the following options is the closest in the meaning to the word below: Inexplicable
Answer: a Explanation: As per the question our job is to find the word which has closest meaning of word Inexplicable from the given four options, The meaning of Inexplicable is something which cannot be explained. Hence from the given options 'Incomprehensible' is the best option among all given four options. 57) If Log(P) = (1 / 2)Log(Q) = (1 / 3)Log(R), then which of the following options is TRUE?
Answer: b Explanation: It is given that Log(P) = (1 / 2)Log(Q) = (1 / 3)Log(R) Let X = Log(P) = (1 / 2)Log(Q) = (1 / 3)Log(R) Let take the base of given log be Y P = Yx - - - - - - - - 1 Using above 1, 2 and 3 we can say that Q2 = PR 58) Choose the most appropriate word (s) from the options given below to complete the following sentence. I Contemplated . . . . . . . . . . Singapore for my vacation but decided against it.
Answer: c Explanation: As per the question our job is to find the most appropriate word that properly fits from the four options, 'Contemplate' is a transitive verb. Hence it must be followed by a gerund . Therefore the appropriate use of contemplate is 'verb' along with the 'ing' form. Let us discuss something about Transitive verb: It can be defined as a verb which accepts 1 or more than 1 objects. Hence it is opposite of intransitive verbs, that actually do not have objects. Transitivity can be thought of as a important property of a clause, through which activity is transmitted via an agent to a patient. Hence the correct option among given four options are 'visiting'. 59) Choose the most appropriate word from the options given below to complete the following sentence. If you are trying to make a strong impression on your audience, you cannot do so by being understated, tentative or . . . . . . . . . . . . . . . .
Answer: b Explanation: Restrained is looking the best option to take place in the above sentence, apart from this all other options does not fit better in above blank space. 60) Choose the word from the options given below that is most nearly opposite in meaning to the given word: Amalgamate
Answer: b Explanation: As our job is too choose opposite meaning of word Amalgamate, As per dictionary meaning of Amalgamate is unite or combine for creating one structure or organization. Hence from the given options 'Separate' means to divide i.e. opposite of unite is a close antonym, of word Amalgamate. 61) Few school curricula include a unit on how to deal with bereavement and grief, and yet all students at some point in their lives suffer from losses through death and parting. Based on the above passage which topic would not be included in a unit on bereavement?
Answer: c Explanation: According to the given passage above, the unit on bereavement is discussing about how to handle grief and bereavement, it's not all about the death causes. Except this all other given options makes a valid sense. 62) P, Q, R and S are four types of dangerous microbes recently found in a human habitat. The area of each circle with its diameter printed in brackets represents the growth of a single microbe surviving human immunity system within 24 hours of entering the body. The danger to human beings varies proportionately with the toxicity, potency and growth attributed to a microbe shown in the figure below:
A pharmaceutical company is contemplating the development of a vaccine against the most dangerous microbe. Which microbe should the company target in its first attempt?
Answer: a Explanation: Answer should be A The risk in humans varies proportionately with the potency, growth, and potency attributed for a microbe R = 30 x 300 x 0.4 = 3600 Q = 40 x 600 x 0.5 = 12000 P = 50 x 800 x 0.4 = 16000 S = 20 x 200 x 0.8 = 3200 According to the official answer key released by GATE 2011, the right option is d. Toxicity as represented in the above graph can be defined as the milligrams of bacteria which is needed to spoil the human body. Toxicity for the value S is max as less amount Level Of Danger (D) ∝ Growth (G) Level of danger - D ∝ 1 / Toxicity (T) Level of danger - D ∝ Potency (P) Level of danger - D = GP / T Hence the level of risk will be maximum for the value of S. Which is given by, Danger of S = ( 0.8 × π(10)2 ) / 200 = 1.256 In the similar manner other values can be calculated. 63) The variable cost (V) of manufacturing a product varies according to the equation V = 4q, where q is the quantity produced. The fixed cost (F) of production of same product reduces with q according to the equation F = 100 / q. How many units should be produced to minimize the total cost (V + F)?
Answer: a Explanation: As per the question asked how many units should be produced to minimize the total cost (V + F) The cost in terms of value of (V + F) can be written as 4q + 100 / q = (4q2 + 100) / q For the resultant equation first derivative will be (8q2 - 100 - 4q2 ) / q2 For the value of (V + F) to be min it is required that its 1st derivative should be equal to 0. i.e. we can write the above equation [(8q2 - 100 - 4q2 ) / q2] = 0 => 4q2 - 100 = 0 4q2 = 100 => q = 5. Hence for the value q = 5 the above equation will produce min value. 64) A transporter receives the same number of orders each day. Currently, he has some pending orders (backlog) to be shipped. If he uses 7 trucks, then at the end of the 4th day he can clear all the orders. Alternatively, if he uses only 3 trucks, then all the orders are cleared at the end of the 10th day. What is the minimum number of trucks required so that there will be no pending order at the end of the 5th day?
Answer: c Explanation: As the given question ask that what is the minimum number of trucks required so that there will be no pending order at the end of the 5th day. Suppose every truck takes at most 'y' units of time. Again suppose that the daily order be 'x' and suppose backlog be 'z'. Hence we can write 7 * 4 * y = 4x + z __________________ (1) Also we can write 3 * 10 * y = 10x + z __________________ (2) We require the value of (5x + z) / 5 in terms of y. We can get value of x by subtracting first from second6x = 2y => x = y / 3 Finally value of z can be calculated by substituting value of x in equation (1) 4x + z = 28y4(y / 3) + z = 28yz = (80 / 3)y ___________________ (3) So the value of (5x + z) / 5 is 5 * (y / 3) + (80 / 3)y which is 17 / 3 Hence we can say that almost 6 trucks needed so that there will be no pending order at the end of the 5th day. 65) A container originally contains 10 litres of pure spirit. From this container 1 litre of spirit is replaced with 1 litre of water. Subsequently, 1 litre of the mixture is again replaced with 1 litre of water and this process is repeated one more time. How much spirit is now left in the container?
Answer: d Explanation: The given in question that container originally contains 10 litres of pure spirit, and from this one litre is replaced with one litre of water, and the process continues for next two times. Therefore using above concept spirit remained after 1st replacement with water = 9 litre Similarly spirit remained after 2nd replacement with water = 9 x (9 / 10) Finally spirit remained after 3rd replacement with water = 9 x (9 / 10) x (9 / 10) = 7.29
Next Topic#
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
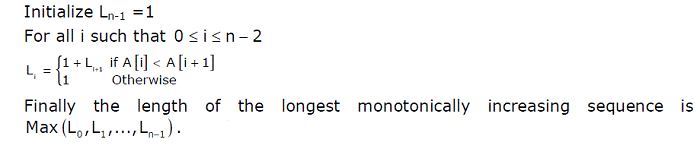
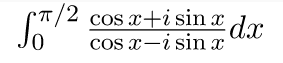
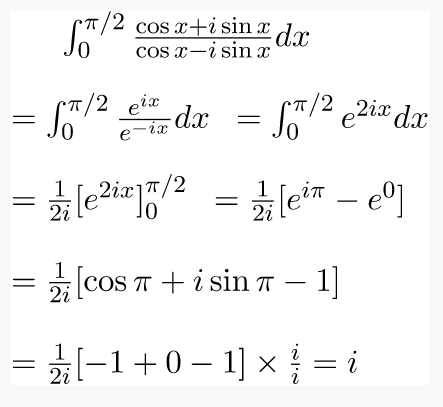
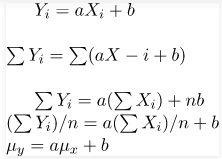
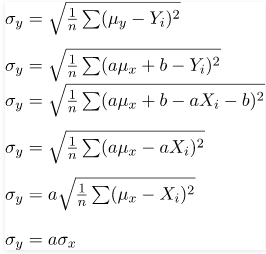
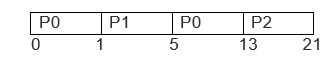




 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








