| |

Difference between Uniform Memory Access (UMA) and Non-uniform Memory Access (NUMA)Multiprocessors are classified into three types of shared memory models: UMA (Uniform Memory Access), NUMA (Non-uniform Memory Access), and COMA (Cache-only Memory Access). The models differ based on how memory and hardware resources are allocated. The physical memory is uniformly shared among the processors in the UMA model, which also has identical latency for every memory word. In contrast, NUMA gives variable accessing time for the CPU to access memory. In this article, you will learn about the difference between the UMA and NUMA. But before discussing the differences, you must know about the UMA and NUMA. What is UMA?UMA is an abbreviation for "Uniform Memory Access". It is a multiprocessor shared memory architecture. In this model, all of the processors in the multiprocessor system use and access the same memory with the aid of the interconnection network. 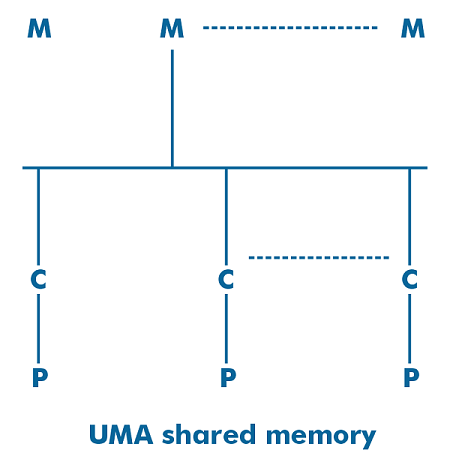
The latency and access speed of each CPU is the same. It can make use of a crossbar switch, a single bus switch, or a multiple bus switch. It is also referred to as SMP (Symmetric Multiprocessor) system because it offers balanced shared memory access. It is suitable for time-sharing and general-purpose applications. What is NUMA?NUMA is an abbreviation for "Non-uniform Memory Access". It is also a multiprocessor model with dedicated memory attached to each CPU. But these small memory components come together to form a single address space. Memory access time is determined by the distance between the CPU and the memory, resulting in varied memory access times. It provides access to any memory place using the physical address. 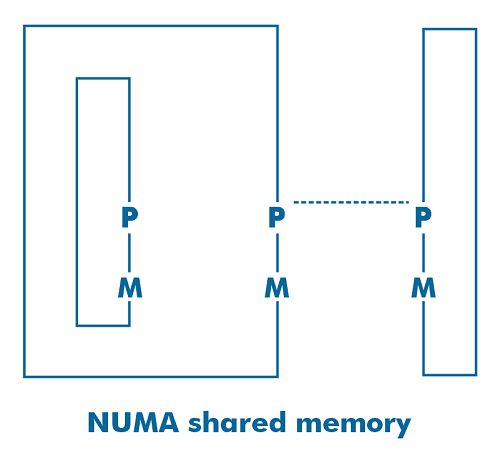
The NUMA architecture is designed to maximize the available memory bandwidth by utilizing several memory controllers. It integrates many machine cores into "nodes", with each core having its own memory controller. In a NUMA system, the core receives the memory handled by the memory controller by its node to access local memory. The core transmits the memory request across the interconnection links to access the distant memory, which the other memory controller processes. The NUMA architecture employs hierarchical and tree bus networks to connect the memory blocks and CPUs. Some examples of the NUMA architecture are BBN, SGI Origin 3000, TC-2000, and Cray. Key Differences between UMA and NUMA
There are various key differences between UMA and NUMA. Some of the key differences between UMA and NUMA are as follows:
Head-to-head comparison between UMA and NUMAHere, you will learn the head-to-head comparisons between UMA and NUMA. The main differences between UMA and NUMA are as follows:
ConclusionThe UMA architecture offers the same overall latency for the processors accessing memory, and it is not particularly useful when accessing local memory because the delay would be uniform. In contrast, in NUMA, each processor has its own dedicated memory, which eliminates delay while accessing local memory. The latency changes depend on the distance between the CPU and memory changes. However, as compared to the UMA design, NUMA offers improved performance.
Next TopicDifference between
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








