| |

Display Unique Rows in a Binary Matrix in JavaIn this section, we will discuss how one can display unique rows in a binary matrix in Java. In this problem, a binary matrix is given and we have to identify, and then print the unique rows of the given binary matrix. Example 1: 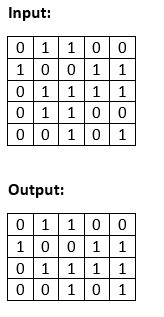
Explanation: In the above input matrix, there are 5 rows: R1 = {0, 1, 1, 0, 0}, and R2 = {1, 0, 0, 1, 1}, R3 = {0, 1, 1, 1, 1}, R4 = {0, 1, 1, 0, 0, 0}, and R5 = {0, 0, 1, 0, 1}. In these 5 rows, rows R1 and R4 are identical, and the other rows are unique. Therefore, row R4 is discarded in the output. Example 2: 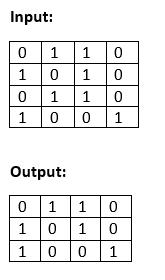
Explanation: In the above input matrix, there are 4 rows: R1 = {0, 1, 1, 0}, and R2 = {1, 0, 1, 0}, R3 = {0, 1, 1, 0}, and R4 = {1, 0, 0, 1}. In these 4 rows, row R1 and R3 are identical, and the rest other rows are unique. Therefore, the row R3 is discarded in the output. Naive ApproachThe naïve approach is simple. First, print the first row, then check the second-row matches with the printed row (first row) or not. If it matches, discard the second row; otherwise, print the second row. For the third row, check whether it matches the printed rows (first and second row) or not. If it does not match, do not print the third row; otherwise, print the third row. Treat the other rows in the same way. Implementation StepsThe following are the steps that are required to implement the naïve approach. Step 1: Traverse the elements of the matrix row-wise. Step 2: For the current row, check whether it matches with any of the previous rows or not. Step 3: If the current row matches with the previous rows, do not print the current row. Step 4: Otherwise, display the current row. Let's see the implementation of the above algorithm. FileName: UniqueRowsMatrix.java Output: For the following matrix: 0 1 1 0 0 1 0 0 1 1 0 1 1 1 1 0 1 1 0 0 0 0 1 0 1 The unique rows are: 0 1 1 0 0 1 0 0 1 1 0 1 1 1 1 0 0 1 0 1 For the following matrix: 0 1 1 0 1 0 1 0 0 1 1 0 1 0 0 1 The unique rows are: 0 1 1 0 1 0 1 0 1 0 0 1 Complexity Analysis: In the above program, we are comparing every row with the previously occurred row to check whether the row is unique or not. In the row comparison, we have to check every element of one row matches with the other row (column-size) or not. Therefore, the time complexity of the above program is O(R2 x C), where R is the total rows present in the matrix and C is the total number of rows present in the matrix. As we are not using any auxiliary array in the program, therefore, the space complexity of the above program is constant, which is O(1). If we observe the above program, we will find that there are many sub-problems that have been computed more than one time, leading to the exponential time complexity. Observe the following. Approach: Using Binary Search TreeIn this approach, the first requirement is to compute the decimal equivalent of each row and push them into the binary search tree. Note that each node of the binary search tree fetches two fields: one for the decimal value, and the other for the row number. Implementation StepsThe following are the steps required to implement the binary search tree approach. Step 1: Create a Binary Search Tree where no duplicate node is stored. Step 2: Create a method to change a row into the decimal and to change the decimal value into the binary array. Step 3: Traverse the input matrix, and insert the row into the Binary Search Tree. Step 4: Do an in-order traversal of the Binary Search Tree and change the decimal into the binary array, and then display it. Let's see the implementation of the above algorithm. FileName: UniqueRowsMatrix1.java Output: For the following matrix: 0 1 1 0 0 1 0 0 1 1 0 1 1 1 1 0 1 1 0 0 0 0 1 0 1 The unique rows are: 0 1 1 0 0 0 0 1 0 1 1 0 0 1 1 0 1 1 1 1 For the following matrix: 0 1 1 0 1 0 1 0 0 1 1 0 1 0 0 1 The unique rows are: 0 1 1 0 1 0 1 0 1 0 0 1 Complexity Analysis: In the above program, we are traversing each row and column of the matrix, which leads to the time complexity of O(R * C). Also, the time complexity of inserting a row in the binary search tree is O(R). As we are inserting each row, therefore the time consumed in insertion is R * O(log(R)). Thus, the overall time complexity of the above program is O(R * C + R * (log(R))). In the program, we are using the auxiliary space to store the binary search array leading to the space complexity of O(R), where R is the row size of the input matrix and C is the column size of the input matrix. Approach: Using TRIEIn this approach, we will be using the TRIE data structure to find the unique rows. We know that the TRIE data structure is an efficient data structure for data retrieval. Using the TRIE data structure, the complexities of searching can be optimized. As we know that the input matrix is the binary matrix; therefore, we will be customizing the TRIE data structure a bit where each node will have two children one is for 1, and the other is for 0. Implementation StepsStep 1: Create a TRIE data structure for storing the row. Step 2: Traverse through each row and insert it into the TRIE data structure created in the previous step. Since, TRIE can never contain any duplicate entries; therefore, when we traverse the duplicate row to insert it into the TRIE; it does not impact the TRIE data structure. Thus, whatever is present in the TRIE, after each row of the input matrix is traversed, are the unique rows. Step 3: Traverse the TRIE data structure and display the rows. Let's see the implementation of the above algorithm. FileName: UniqueRowsMatrix2.java Output: For the following matrix: 0 1 1 0 0 1 0 0 1 1 0 1 1 1 1 0 1 1 0 0 0 0 1 0 1 The unique rows are: 0 1 1 0 0 0 0 1 0 1 1 0 0 1 1 0 1 1 1 1 For the following matrix: 0 1 1 0 1 0 1 0 0 1 1 0 1 0 0 1 The unique rows are: 0 1 1 0 1 0 1 0 1 0 0 1 Complexity Analysis: In the above program, we are traversing each row and column of the matrix, which leads to the time complexity of O(R * C). In the program, we are using the auxiliary space to store the TRIE data structure leading to the space complexity of O(R * C), where R is the row size of the input matrix and C is the column size of the input matrix. Approach: Using HashSetIn this approach, we will use the HashSet data structure to find the unique rows. We know that the HashSet data structure implements the Set interface. Therefore, there cannot be any duplicate data present in the HashSet. The approach is to convert each row of the HashSet into String and insert it into the HashSet. Implementation StepsStep 1: Create a HashSet data structure for storing the row. Step 2: Traverse through each row and insert it into the Hash data structure created in the previous step. Since, HashSet can never contain any duplicate entries; therefore, when we traverse the duplicate row to insert it into the HashSet, it does not impact the HashSet data structure. Thus, whatever is present in the HashSet, after each row of the input matrix is traversed, are the unique rows. Note that before inserting the row in the HashSet, convert it into the String. For Example, For the following row: 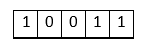
We will have the String as "10011". Step 3: Traverse the HashSet data structure and display the rows. Let's see the implementation of the above algorithm. FileName: UniqueRowsMatrix3.java Output: For the following matrix: 0 1 1 0 0 1 0 0 1 1 0 1 1 1 1 0 1 1 0 0 0 0 1 0 1 The unique rows are: 0 1 1 0 0 0 0 1 0 1 1 0 0 1 1 0 1 1 1 1 For the following matrix: 0 1 1 0 1 0 1 0 0 1 1 0 1 0 0 1 The unique rows are: 0 1 1 0 1 0 1 0 1 0 0 1 Complexity Analysis: In the above program, we are traversing each row and column of the matrix, which leads to the time complexity of O(R * C). In the program, we are using the auxiliary space to store the Hash data structure leading to the space complexity of O(R * C), where R is the row size of the input matrix and C is the column size of the input matrix.
Next TopicRotate A Matrix By 180 Degree in Java
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








